















































软件

产品


优化器总结
机器学习中,有很多优化方法来试图寻找模型的最优解。比如神经网络中可以采取最基本的梯度下降法。
梯度下降法(Gradient Descent)
梯度下降法是最基本的一类优化器,目前主要分为三种梯度下降法:标准梯度下降法(GD, Gradient Descent),随机梯度下降法(SGD, Stochastic Gradient Descent)及批量梯度下降法(BGD, Batch Gradient Descent)。
评价:标准梯度下降法主要有两个缺点:
评价:
评价:
动量优化方法是在梯度下降法的基础上进行的改变,具有加速梯度下降的作用。一般有标准动量优化方法Momentum、NAG(Nesterov accelerated gradient)动量优化方法。
NAG在Tensorflow中与Momentum合并在同一函数tf.train.MomentumOptimizer中,可以通过参数配置启用。
自适应学习率优化算法针对于机器学习模型的学习率,传统的优化算法要么将学习率设置为常数要么根据训练次数调节学习率。极大忽视了学习率其他变化的可能性。然而,学习率对模型的性能有着显著的影响,因此需要采取一些策略来想办法更新学习率,从而提高训练速度。 目前的自适应学习率优化算法主要有:AdaGrad算法,RMSProp算法,Adam算法以及AdaDelta算法。
思想:
算法描述:
思想:
算法描述:

思想:AdaGrad算法和RMSProp算法都需要指定全局学习率,AdaDelta算法结合两种算法每次参数的更新步长即:

评价:
思想:
算法描述:

评价:Adam通常被认为对超参数的选择相当鲁棒,尽管学习率有时需要从建议的默认修改。
各种优化器的比较
终于结束的漫长的理论分析,下面对各种优化器做一些有趣的比较。
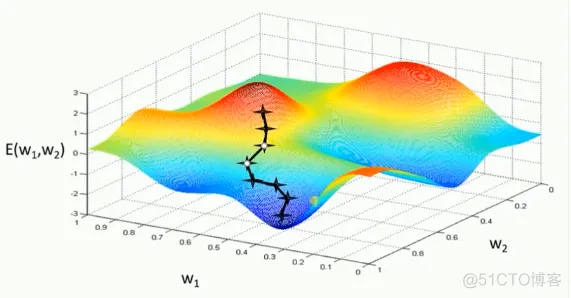
(1) 示例一
上图描述了在一个曲面上,6种优化器的表现,从中可以大致看出:
① 下降速度:
② 下降轨迹:
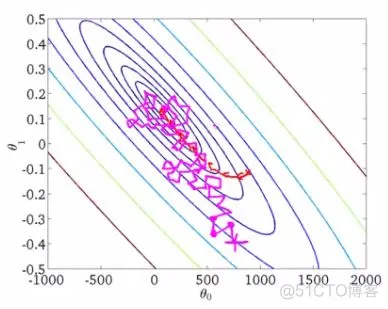
(2) 示例二
上图在一个存在鞍点的曲面,比较6中优化器的性能表现,从图中大致可以看出:
(3) 示例三
上图比较了6种优化器收敛到目标点(五角星)的运行过程,从图中可以大致看出:
① 在运行速度方面
② 在收敛轨迹方面
#梯度下降:SGD优化器
train_step=tf.compat.v1.train.GradientDescentOptimizer(0.2).minimize(loss)
# Iter 0,Testing Accuracy 0.9236
# Iter 1,Testing Accuracy 0.9449
# Iter 2,Testing Accuracy 0.9508
# Iter 3,Testing Accuracy 0.9527
# Iter 4,Testing Accuracy 0.9591
# Iter 5,Testing Accuracy 0.962
# Iter 6,Testing Accuracy 0.9643
# Iter 7,Testing Accuracy 0.9672
# Iter 8,Testing Accuracy 0.9675
# Iter 9,Testing Accuracy 0.9696
# Iter 10,Testing Accuracy 0.97021.2.3.4.5.6.7.8.9.10.11.12.13.#使用自适应学习率,使用AdaGrad优化器
train_step=tf.compat.v1.train.AdagradOptimizer(0.2).minimize(loss)
# Iter 0,Testing Accuracy 0.855
# Iter 1,Testing Accuracy 0.8647
# Iter 2,Testing Accuracy 0.957
# Iter 3,Testing Accuracy 0.9633
# Iter 4,Testing Accuracy 0.9683
# Iter 5,Testing Accuracy 0.9723
# Iter 6,Testing Accuracy 0.9707
# Iter 7,Testing Accuracy 0.9727
# Iter 8,Testing Accuracy 0.9748
# Iter 9,Testing Accuracy 0.9738
# Iter 10,Testing Accuracy 0.97521.2.3.4.5.6.7.8.9.10.11.12.13.#使用自适应学习率:使用RMSProp优化器
train_step=tf.compat.v1.train.RMSPropOptimizer(0.02).minimize(loss)
# Iter 0,Testing Accuracy 0.9007
# Iter 1,Testing Accuracy 0.9102
# Iter 2,Testing Accuracy 0.9165
# Iter 3,Testing Accuracy 0.9298
# Iter 4,Testing Accuracy 0.9373
# Iter 5,Testing Accuracy 0.9205
# Iter 6,Testing Accuracy 0.9306
# Iter 7,Testing Accuracy 0.9422
# Iter 8,Testing Accuracy 0.9297
# Iter 9,Testing Accuracy 0.9417
# Iter 10,Testing Accuracy 0.93591.2.3.4.5.6.7.8.9.10.11.12.13.# 使用自适应学习绿:使用Adam优化器
train_step=tf.compat.v1.train.AdamOptimizer(0.02,0.9).minimize(loss)
# Iter 0,Testing Accuracy 0.8112
# Iter 1,Testing Accuracy 0.8114
# Iter 2,Testing Accuracy 0.81
# Iter 3,Testing Accuracy 0.7948
# Iter 4,Testing Accuracy 0.8212
# Iter 5,Testing Accuracy 0.8145
# Iter 6,Testing Accuracy 0.8443
# Iter 7,Testing Accuracy 0.8678
# Iter 8,Testing Accuracy 0.8394
# Iter 9,Testing Accuracy 0.8934
# Iter 10,Testing Accuracy 0.89171.2.3.4.5.6.7.8.9.10.11.12.13.#使用自适应学习绿:使用AdaDelta优化器
train_step=tf.compat.v1.train.AdadeltaOptimizer(0.02).minimize(loss)
# Iter 0,Testing Accuracy 0.4545
# Iter 1,Testing Accuracy 0.5644
# Iter 2,Testing Accuracy 0.7053
# Iter 3,Testing Accuracy 0.759
# Iter 4,Testing Accuracy 0.7785
# Iter 5,Testing Accuracy 0.7925
# Iter 6,Testing Accuracy 0.8028
# Iter 7,Testing Accuracy 0.8114
# Iter 8,Testing Accuracy 0.8165
# Iter 9,Testing Accuracy 0.82
# Iter 10,Testing Accuracy 0.82371.2.3.4.5.6.7.8.9.10.11.12.13.#使用动量优化法:Momentum优化器
train_step=tf.compat.v1.train.MomentumOptimizer(0.2,0.5).minimize(loss)
# Iter 0,Testing Accuracy 0.8425
# Iter 1,Testing Accuracy 0.8539
# Iter 2,Testing Accuracy 0.9527
# Iter 3,Testing Accuracy 0.9588
# Iter 4,Testing Accuracy 0.9665
# Iter 5,Testing Accuracy 0.9697
# Iter 6,Testing Accuracy 0.9699
# Iter 7,Testing Accuracy 0.9724
# Iter 8,Testing Accuracy 0.9723
# Iter 9,Testing Accuracy 0.9719
# Iter 10,Testing Accuracy 0.97311.2.3.4.5.6.7.8.9.10.11.12.13.#使用动量优化法:使用NAG优化器
train_step=tf.compat.v1.train.MomentumOptimizer(learning_rate=0.2,momentum=0.5,use_nesterov=True).minimize(loss)
# Iter 0,Testing Accuracy 0.8483
# Iter 1,Testing Accuracy 0.8606
# Iter 2,Testing Accuracy 0.953
# Iter 3,Testing Accuracy 0.9558
# Iter 4,Testing Accuracy 0.9601
# Iter 5,Testing Accuracy 0.9657
# Iter 6,Testing Accuracy 0.9666
# Iter 7,Testing Accuracy 0.9683
# Iter 8,Testing Accuracy 0.9721
# Iter 9,Testing Accuracy 0.9721
# Iter 10,Testing Accuracy 0.97171.2.3.4.5.6.7.8.9.10.11.12.13.NAG在Tensorflow中与Momentum合并在同一函数tf.train.MomentumOptimizer中,可以通过参数配置启用。
综上,比较来说AdaGrad优化器和Momentum优化器相对来说比较好
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















