















































软件

产品


TensorFlow是由Tensor和Flow两个英文单词构成。谷歌公司首款智能芯片命名为Tensor(2021年推出),它可以构建构建适应未来的 AI/ML(人工智能/机器学习)各种应用需求。TensorFlow在2015年由谷歌公司推出,用于各类机器学习算法的编程实现。Tensor芯片推出时间要比TensorFlow晚,谷歌将首款智能芯片命名为Tensor,应该是配合TensorFlow拓展AI/ML应用市场。
Tensor原意是张肌(医学)、张量(化学),对TensorFlow来说,Tensor是张量,张量是一个可用来表示一些矢量、标量和其他张量之间的线性关系的多线性函数。在TensorFlow中,张量是标量、矢量、矩阵、多维数据等数据类型。Flow是流动、持续的意思。由此可见,TensorFlow是标量、矢量、矩阵、多维数组等数据在多个处理节点持续流动和被处理。
TensorFlow是用于开发机器学习应用的计算框架,在基于核心库的基础上,它对外提供了针对不同编程语言的开发接口,支持Python、C++、Java等编程语言开发和训练机器学习模型。TensorFlow对Python的支持最为完善,相关帮助文档和学习教程最为丰富,开发实例容易获取。另外还有比较重要的一点,Python在数值计算、图像视觉处理、数据处理等方面有得天独厚的第三方库优势,这些库都是机器学习必不可少的构件,相对C++、Java语言来说,使用Python学习TensorFlow可以快速提升你的学习曲线。
学习TensorFlow的最佳配置环境如下图所示。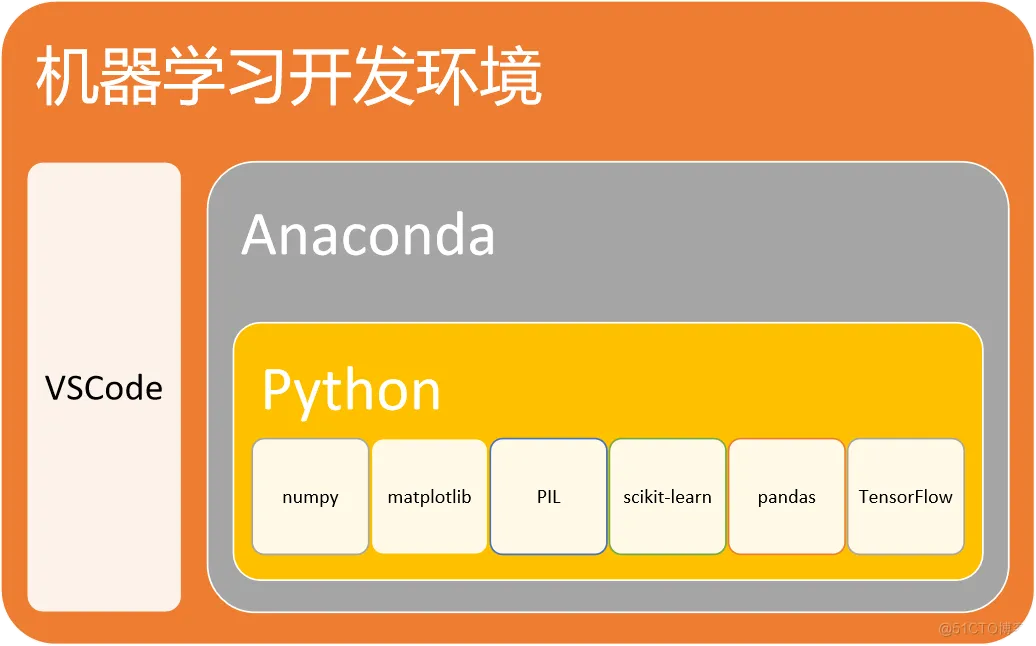
图 1-1学习TensorFlow最佳配置环境
Anaconda可以创建基于Python的虚拟开发环境,它允许在同一机器上创建几个相互独立的Python开发环境,隔离不同项目所需的不同版本的工具包,有效防止版本的冲突。例如:我们可以在同一机器上创建基于TensorFlow-cpu和TensorFlow-gpu两个版本的TensorFlow开发学习环境,观察和研究CPU模式和GPU模式在训练和部署机器学习模型上的差异。
VSCode是一款代码编辑器,编程环境对开发者非常友好,编写代码过程中的语法帮助、代码排版和美化方面做的还是不错的,用VSCode做机器学习的代码编辑器,可以省掉代码优化排版、Python语法错误排查等费时费力的工作。
numpy是数值计算库,多用于矩阵和多维向量的数值计算,同时提供了大量数值计算函数,可以解决机器学习中大量数值计算的问题。
matplotlib是一个数据可视化库,主要用于对机器学习中的数据进行可视化处理,将数据以图表方式展现出来,便于观察和分析数据。
PIL是图片处理库,开发基于图像识别等机器学习程序时,需要使用该库对图片进行切片、过滤、灰度化等图像处理操作。
Pandas是对数据进行处理的工具,机器学习中需要大量的对数据进行处理的操作,通过该工具可以对数据进行快速建模。
scikit-learn也是常用的机器学习库,不同于tensorflow,它不是深度学习。它擅长传统的机器学习方法。那么传统的机器学习和深度学习有什么区别呢?下面给出一个传统的机器学习案例。
建立人口自然增长率预测模型
下表是国民总收入、人均GDP和居民消费价格指数及人口自然增长率部分数据集。
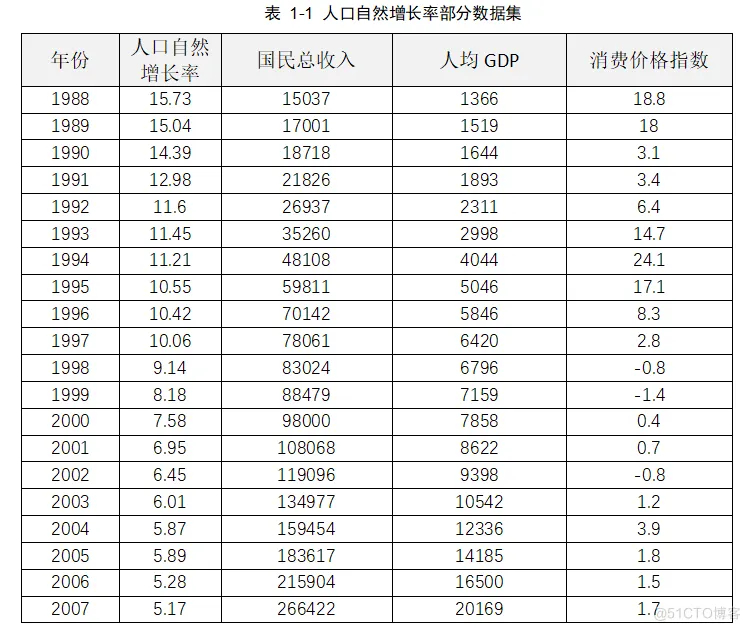
要求编写一个机器学习应用程序,为中国人口自然增长率建立预测模型,该模型根据国民总收入、人均GDP和居民消费价格指数三个因素来预测中国人口自然增长率,这三个因素也称为样本特征。
有了学习数据集,就要考虑设计学习算法了。学习算法是从学习数据集找出数据集变量间的函数关系,即建立预测模型(函数模型)。
在身高预测体重案例中,其数据集有两个变量:身高和体重,体重是因变量,身高是自变量,建立的函数关系是一元一次函数,变量间的关系是线性关系。
在预测人口自然增长率案例的数据集中,有四个变量,其中人口自然增长率是因变量,国民总收入、人均GDP、消费价格指数是自变量,学习算法要建立的函数关系是多元函数,是多元一次函数,还是多元二次函数,……,需要我们通过散点图来发现因变量与多个自变量间的关系。
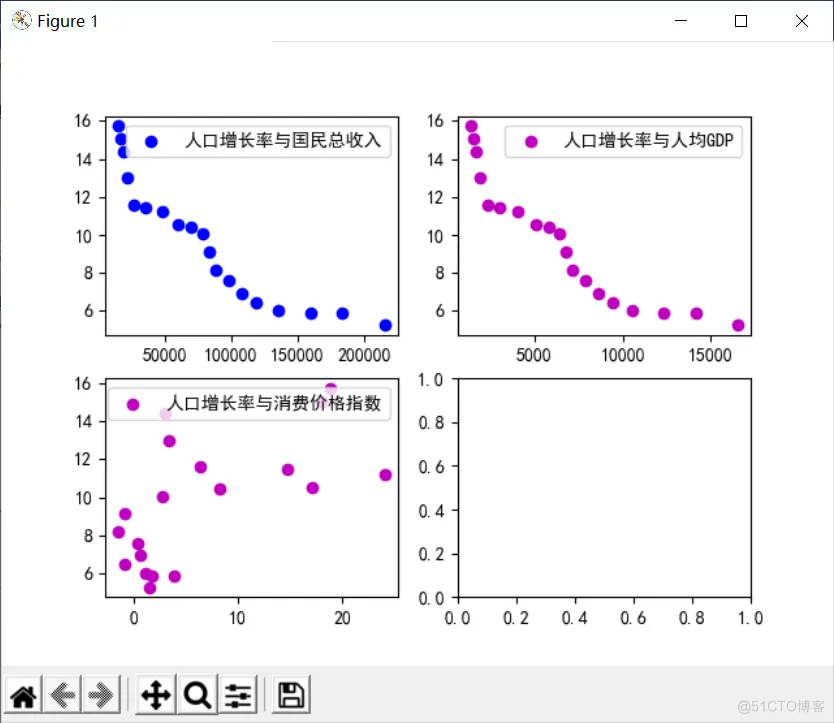
图 1-2 人口自然增长率关系图
从散点图可以看出,人口增长率与国民总收入、人均GDP呈现较好地线性关系,人口增长率与消费价格指数线性关系较弱,在本案例中,可以认为它们具有一定的线性关系。
由此,人口增长率与国民总收入、人均GDP、消费价格指数的线性关系可以假设用下面的多元线性回归模型来表示:
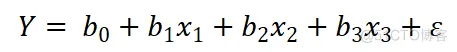
通过学习算法确定回归模型系数值的活就由scikit-learn来做了,可见在传统机器学习中,特征数据和模型的设定一般是由人工来完成的。
在机器学习领域,有很多机器学习任务并不适合从已知数据中提取特征数据,然后将这些特征数据提供给机器学习算法。例如,假设我们要编写一个对服装图像进行分类的程序,使用传统的机器学习方法就会存在问题,因为我们难以准确地根据像素值来描述服装图像数据的特征。解决这个问题的途径之一是使用深度学习技术,深度学习类似于人通过眼睛来识别服装图像并进行分类,深度学习会通过像素值识别出边,再由边识别出角和轮廓,然后进一步识别出图像中的服装,其图像识别过程由简单到复杂,由简单到复杂的识别过程不是一挥而就的,而是分成多个识别层,每个识别层输入的数据是前一层输出的数据,最后的识别层会输出识别出的服装所属的类别。
tensorflow提供了一个对服装图像进行分类的案例,该案例训练一个神经网络模型,对运动鞋和衬衫等服装图像进行分类。
案例提供了训练和测试用的数据集,该数据集包含 10 个类别的 70,000 个灰度图像。这些图像以低分辨率(28x28 像素)展示了单件衣物,如图1-3所示。

图 1-3服装灰度图像
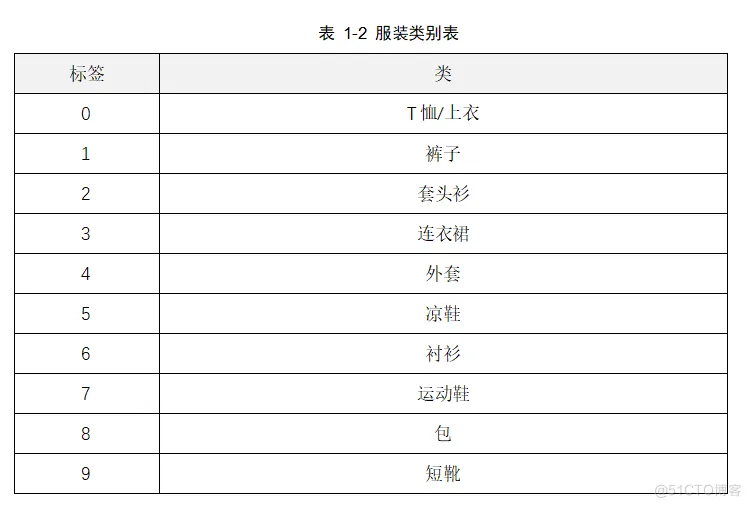
数据集还包括了一个服装类型的标签数组,数组的每个值介于0~9之间,这些标签对应于图像所代表的服装类。如表1-2所示。
训练该神经网络模型需要向模型传送上面的数据集,模型学习将图像和标签关联起来。该模型的基本组成部分是层,层会从向其传送的图像数据中提取表示形式(类似于人的眼睛,从图像数据提取特征数据),该网络的第一层将图像数据从二维数组(28 x 28 像素)转换成一维数组,然后是密集连接或全连接神经层,最后一个层会返回一个数组,该数组存储了当前图像属于各个类别的得分,用来表示当前图像属于 10 个类中的哪一类。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















