















































软件

产品


Tensor Flow 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。
这是谷歌开源的一个强大的做深度学习的软件库,提供了C++ 和 Python 接口,下面给出用Tensor Flow 建立MLP 网络做笑脸识别的一个简单用例。这个用例可以帮助我们熟悉如何利用tensorflow 建立MLP, 并且利用MLP做分类。
我们用到的数据库是GENKI4K,这个数据库有4000张图像,首先做人脸检测与剪切,然后提取HOG特征。这个数据库有 4000 张图,我们建立一个含有两个隐含层的MLP, 激励函数用的是Relu, f(x)=max(0,x)。
我们将裁剪得到的人脸图像resize成64×64, 然后提取HOG 特征,基于默认的设置,得到HOG特征的维数是1764, 第一个隐含层我们设置300个节点,第二个隐含层我们设置100个节点,最后的输出是2个节点,分别表示笑或不笑。
网络结构如下所示:
input(1764)->hidden 1(300)->hidden 2(100)->output(2)
import string, os, sys
import numpy as np
import matplotlib.pyplot as plt
import scipy.io
import random
import tensorflow as tf
# set the folder path
dir_name = '/media/chi/New Volume/Dataset/GENKI4K/Feature_Data'
print '----------- no sub dir'
# set the file path
files = os.listdir(dir_name)
for f in files:
print (dir_name + os.sep + f)
file_path = dir_name + os.sep+files[14]
# get the data
dic_mat = scipy.io.loadmat(file_path)
data_mat = dic_mat['Hog_Feat']
print (dic_mat.keys())
print (type(dic_mat))
print ('feature: ', data_mat.shape)
# print data_mat.dtype
file_path2 = dir_name + os.sep + files[15]
# print file_path2
dic_label = scipy.io.loadmat(file_path2)
label_mat = dic_label['Label']
file_path3 = dir_name + os.sep+files[16]
print ('file 3 path: ', file_path3)
dic_T = scipy.io.loadmat(file_path3)
T = dic_T['T']
T = T-1
print (T.shape)
label = label_mat.ravel()
print (label.shape)
label_y = np.zeros((4000, 2))
label_y[:, 0] = label
label_y[:, 1] = 1-label
print (label_y.shape)
T_ind=random.sample(range(0, 4000), 4000)
# Parameters
learning_rate = 0.005
train_epoch=100
batch_size = 40
batch_num=4000/batch_size
# Network Parameters
n_hidden_1 = 300 # 1st layer number of features
n_hidden_2 = 100 # 2nd layer number of features
n_input = 1764 # data input
n_classes = 2 # total classes (2)
drop_out = 0.5
# tf Graph input
x = tf.placeholder(tf.float32, [None, n_input])
y = tf.placeholder(tf.float32, [None, n_classes])
# Create some wrappers for simplicity
# 定义MLP 函数
def multilayer_perceptron(x, weights, biases, drop_out):
# Hidden layer with RELU activation
layer_1 = tf.add(tf.matmul(x, weights['w1']), biases['b1'])
layer_1 = tf.nn.relu(layer_1)
# Hidden layer with RELU activation
layer_2 = tf.add(tf.matmul(layer_1, weights['w2']), biases['b2'])
layer_2 = tf.nn.relu(layer_2)
# layer_2 = tf.nn.dropout(layer_2, drop_out)
# Output layer with linear activation
out_layer = tf.matmul(layer_2, weights['w_out']) + biases['b_out']
return out_layer
# Store layers weight & bias
weights = {
'w1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'w2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'w_out': tf.Variable(tf.random_normal([n_hidden_2, n_classes]))
}
biases = {
'b1': tf.Variable(tf.random_normal([n_hidden_1])),
'b2': tf.Variable(tf.random_normal([n_hidden_2])),
'b_out': tf.Variable(tf.random_normal([n_classes]))
}
# Construct model
pred = multilayer_perceptron(x, weights, biases, drop_out)
# Define loss and optimizer
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
# Initializing the variables
init = tf.initialize_all_variables()
# Evaluate model
correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# Initialize the variables
init = tf.initialize_all_variables()
train_loss = np.zeros(train_epoch)
train_acc = np.zeros(train_epoch)
with tf.Session() as sess:
sess.run(init)
for epoch in range(0, train_epoch):
for batch in range (0, batch_num):
arr_3 = T_ind[ batch * batch_size : (batch + 1) * batch_size ]
batch_x = data_mat[arr_3, :]
batch_y = label_y[arr_3, :]
# Run optimization op (backprop)
sess.run(optimizer, feed_dict={x: batch_x, y: batch_y})
# Calculate loss and accuracy
loss, acc = sess.run([cost, accuracy], feed_dict={x: data_mat,
y: label_y})
train_loss[epoch] = loss
train_acc[epoch] = acc
print("Epoch: " + str(epoch+1) + ", Loss= " + \
"{:.3f}".format(loss) + ", Training Accuracy= " + \
"{:.3f}".format(acc))
plt.subplot(211)
plt.plot(train_loss, 'r')
plt.xlabel("Epoch")
plt.ylabel("Training loss")
plt.grid(True)
plt.subplot(212)
plt.xlabel("Epoch")
plt.ylabel('Training Accuracy')
plt.ylim(0.0, 1)
plt.plot(train_acc, 'r')
plt.grid(True)
plt.show()
仿真结果: (这里只给出了整个 training set 的结果)
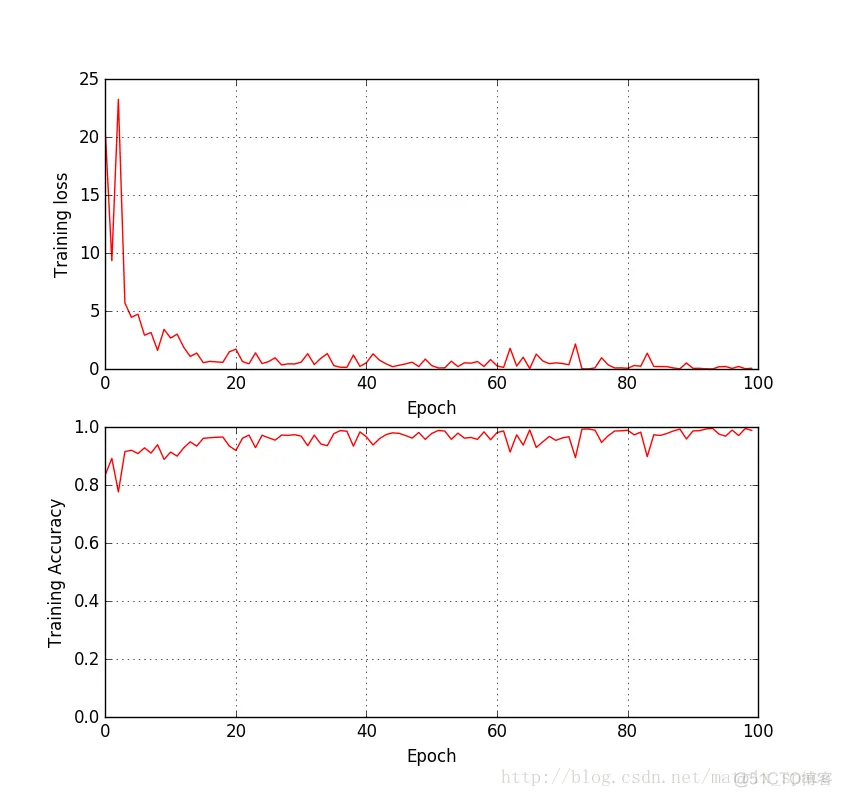
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















