















































软件

产品


合并是指将多个张量在某个维度上合并为一个张量,比如我们要将某学校所有的考试成绩单进行合并,张量A中记录了该学校1-4班的50名学生的9门科目的成绩,此时对应的shape就是[4,50,9],张量B记录了5-10班的成绩,此时的shape就是[6,50,9],我们合并这两个张量就能够得到该学校全部成绩的张量C为[10,50,9],此时张量合并的用处就得以体现了。
张量的合并可以通过拼接和堆叠来实现,拼接操作并不会产生新的维度,仅在现有的维度上合并,而堆叠会创建新维度。选择使用拼接还是堆叠操作来合并张量,取决于具体的场景是否需要创建新维度。
我们可以直接使用Tensorflow中的tf.concat(tensors,axis)函数拼接张量:
需要注意的是,拼接的时候我们要保证非合并维度的长度必须是一致的。
对于我们最开始举的例子,代码实现方式如下:
import tensorflow as tfimport numpy as npa = tf.random.normal([4,50,9])b = tf.random
.normal([6,50,9])c = tf.concat([a,b],axis=0)# print(c.shape)# (10, 50, 9)# 尝试对其他的纬度进行拼接 a = tf
.random.normal([5,50,6])b = tf.random.normal([5,50,7])c = tf.concat([a,b],axis=2)# print(c.shape)
# (5, 50, 13)1.2.3.4.5.6.7.8.9.10.11.12.13.我们上面使用到的拼接操作是在现有的维度上合并数据,并不会创建新的维度,如果我们在合并数据时,希望创建一个新的维度,则需要使用tf.stack操作。比如我们要将两个班级的考试成绩单进行合并,张量A中记录了第一个班级的50名学生的9门科目的成绩,此时对应的shape就是[50,9],张量B记录了第二个班级的成绩,此时的shape也是[50,9],我们合并这两个张量就能够得到该学校全部成绩的张量C为[2,50,9],此时我们就可以使用堆叠的操作来创建一个新的维度。
我们可以直接使用tf.stack(tensors,axis)进行多个张量的堆叠:
需要注意的是,在进行堆叠操作的时候要保证所有张量的纬度是一致的。
axis对应值的插入位置如下图所示:
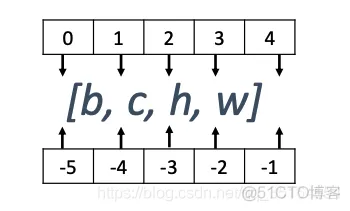
代码的实现方式如下:
a = tf.random.normal([35,8])b = tf.random.normal([35,8])c = tf.stack([a,b],axis=0)# print(c.shape)
# (2, 35, 8)d = tf.stack([a,b],axis=-1)# print(d.shape)# (35, 8, 2)1.2.3.4.5.6.7.8.既然我们可以进行合并操作,那么同样我们也可以进行逆向的分割操作,将一个张量拆分为多个张量,用我们之前的成绩单数据,整个学校的数据为[10,50,9]现在我们把它分为10个张量,每个张量保存对应班级的成绩单。
我们可以直接使用tf.split(x,num_or_size_splits,axis)进行分割操作:
代码实现方式如下:
x = tf.random.normal([10, 35, 8])y = tf.split(x, 10, axis=0)print(len(y))print(y[0].shape)1.2.3.4.
10(1, 35, 8)1.2.在进行神经网络计算的时候,我们通常需要统计数据的各种属性,如均值、最值、众数等信息,但是对于复杂的张量,我们往往不能通过观察数据来获取有用的信息,下面来学习一下数据统计的方法。
向量范数是表征向量“长度”的一种度量方法,他可以推广到张量上,在神经网络中我们通常用来表示张量的权值大小,梯度大小等,常用的向量范数有:
我们可以使用tf.norm(x,ord)求解张量的范数:
代码实现方式如下:
x = tf.ones([2,2])# 计算L1范数tf.norm(x,ord=1)# 计算L2范数tf.norm(x,ord=2)# 计算∞范数tf.
norm(x,ord=np.inf)1.2.3.4.5.6.7.
<tf.Tensor: shape=(), dtype=float32, numpy=1.0>1.我们可以使用tensorflow进行简单的数据统计,常用的函数如下:
x = tf.random.normal([4,10])# 计算某个维度上的最大值tf.reduce_max(x,axis=1)# 计算全局的最大值tf
.reduce_max(x)# 计算某个纬度的最小值tf.reduce_min(x,axis=1)# 计算全局的最小值tf.reduce_min(x)
# 计算某个维度的均值tf.reduce_mean(x,axis=1)# 计算全局的均值tf.reduce_mean(x)# 计算某个维度的和tf
.reduce_sum(x,axis=1)# 计算全局的和tf.reduce_sum(x)# 得到最大值的索引tf.argmax(x)# 得到最小值的索引tf
.argmin(x)1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.
<tf.Tensor: shape=(10,), dtype=int64, numpy=array([1, 3, 3, 3, 3, 1, 2, 3, 3, 1])>1.通常我们会涉及到对两个张量进行比较的操作,tensorflow中常用的比较函数如下:
| 函数 | 比较逻辑 |
| tf.math.greater | a>b |
| tf.math.less | a<b |
| tf.math.greater_equal | ab |
| tf.math.less_equal | ab |
| tf.math.not_equal | ab |
| tf.equal | a=b |
| tf.math.is_nan | a=nan |
对于很多图片数据来说,长度宽度总是不同的,这也导致我们很难对不同维度之间的数据进行运算,此时就需要我们将不同长度的数据扩充为相同的长度,使得二者之间可以进行运算,通常的做法是,在需要补充长度的数据开始或结束处填充足够数量的特定数值,这些特定数值一般代表了无效意义,例如0,使得填充后的长度满足系统要求。那么这种操作就叫作填充 (Padding)。
举个例子
我们考虑下面两个句子:
算上标点,我们对其进行数字编码,可以变成如下的形式:
对于第一个句子,我们就需要进行一个填充操作,在末尾填充若干个0变成如下的形式:
这样我们就能进行运算操作了。
Tensorflow中填充操作可以用tf.pad(x,padding)实现:
代码的实现方式如下:
a = tf.constant([1, 2, 3, 4])b = tf.constant([1, 2, 3, 5, 4])a = tf.pad(a, [[0, 1]])
# 将两个句子堆叠合并tf.stack([a, b], axis=0)1.2.3.4.5.
<tf.Tensor: shape=(2, 5), dtype=int32, numpy=array([[1, 2, 3, 4, 0],
[1, 2, 3, 5, 4]], dtype=int32)>1.2.3.之前我们了解过,通过tf.tile()函数可以实现长度为1的维度复制功能,其实我们还可以进行任意维度的复制操作。
代码实现方式如下:
x = tf.random.normal([4, 32, 32, 3])tf.tile(x, [2, 2, 1, 1])# shape=(8, 64, 32, 3)1.2.3.在很多的场景中,我们需要限制元素的范围。
Tensorflow中也提供了数据限幅的方法,我们可以通过tf.maximum(x,a)实现数据的下限幅,此时的数据将会大于a,同样我们可以通过tf.minimum(x,a)实现数据的上限幅,此时的数据将会小于a,tf.clip_by_value(x,a,b)函数实现上下限幅,此时的数据将会在a和b之间。
代码实现方式如下:
x = tf.range(9)tf.maximum(x,2)# [2, 2, 2, 3, 4, 5, 6, 7, 8]tf.minimum(x,7)
# [0, 1, 2, 3, 4, 5, 6, 7, 7]tf.clip_by_value(x,2,7)# [2, 2, 2, 3, 4, 5, 6, 7, 7]1.2.3.4.5.6.7.
<tf.Tensor: shape=(9,), dtype=int32, numpy=array([2, 2, 2, 3, 4, 5, 6, 7, 7], dtype=int32)>1.
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















