















































软件

产品


import tensorflow as tf
import numpy as np
import random
import os
import pathlib
import shutil
from random import shuffle
使用的数据集的文件结构如下:
train和test文件夹里面的文件名 (如001D-1-20-12-10)都有标识其阴性或者阳性,之后用标签0,1标记。
p.iterdir() #遍历目录的子目录和文件 p.is_dir() #判断是否是目录,返回布尔值 p.is_file() #判断是否是文件,返回布尔值 p.exists() #判断路径是否存在,返回布尔值 p.resolve() #返回绝对路径,WindowsPath p.unlink() #删除目录或文件p.glob() #条件遍历目录 p.rename() #重命名目录或文件夹
Path.glob(pattern):获取路径下的所有符合pattern的文件,返回一个generator
下面返回的就是所有的文件,因为已经是归类好的都是数据图片了,也可以使用'*.jpg'这样的来进行获取。
这里使用shuffle把图片路径打乱了一下,不然可能出现病例成批出现的结果影响模型训练。
path = R"data_sets\train_test_dataset"
train_path=path+'\\'+'train'
train_filelist=os.listdir(train_path)
train_data_path = pathlib.Path('data_sets\\train_test_dataset\\train')
train_X = list(train_data_path.glob('*.*'))
train_X = [str(path) for path in train_X] # 所有图片路径的列表
shuffle(train_X)
因为还不是很熟悉python的使用方法,所以使用了很笨的判断字符确认阳性与否的方法打标签,这个方法很不具有通用性,想办法改进一下。这里一开始出锅了,打乱后标记的输入是路径,导致一开始训练train acc很高,test acc一直0.5,后来才检查出来标签没打好。
lb=lambda img:1 if img[35]=='A' else 0
train_y=[lb(file) for file in train_X]
创建好训练集的数据和标签后丢给Dataset.from_tensor_slices()进行特征切片,将特征和标签对应起来。
train_data_set = tf.data.Dataset.from_tensor_slices((train_X,train_y))
方法和创建训练集相同。
test_path=path+'\\'+'test'
test_filelist=os.listdir(test_path)
test_data_path = pathlib.Path('data_sets\\train_test_dataset\\test')
test_x = list(test_data_path.glob('*.*'))
test_x = [str(path) for path in test_x] # 所有图片路径的列表
lb2=lambda img:1 if img[34]=='A' else 0
shuffle(test_x)
test_y=[lb2(test_file) for test_file in test_x]
test_data_set = tf.data.Dataset.from_tensor_slices((test_x,test_y))
定义加载和预处理图片函数load_and_preprocess_from_path_label()
由上面创建的data_set的元素都只是路径,我们需要从路径读出图片,并设置图片大小,归一化,转换类型等等,可以将这些方法都定义到这个函数中
def load_and_preprocess_from_path_label(path, label):
image = tf.io.read_file(path) # 读取图片
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.resize(image, [128, 128]) # 重设图片大小为(128,128 )
image /= 255.0 # 归一化到[0,1]范围
return image, label
map接收一个函数,Dataset中的每个元素都会被当作这个函数的输入,并将函数返回值作为新的Dataset 引用 就如我们这里的操作,将路径元素丢进去处理出来一个归一化后的图片。
train_iter = train_data_set.map(load_and_preprocess_from_path_label)
test_iter = test_data_set.map(load_and_preprocess_from_path_label)
直接将数据集作为网络输入的话会报错,因为维数为3,神经网络的输入维数为4,将数据集分批传入就不会报错了,设定batch_size为32.
BATCH_SIZE = 32
train_iter=train_iter.batch(BATCH_SIZE)
test_iter=test_iter.batch(BATCH_SIZE)
使用的网络是前几篇博客中使用的vgg网络,微调了一些层的结构。
仍然使用动手深度学习网站上的训练和可视化函数获取结果。
net2=d2l.train_ch6(net, train_iter, test_iter, 24, lr, d2l.try_gpu())
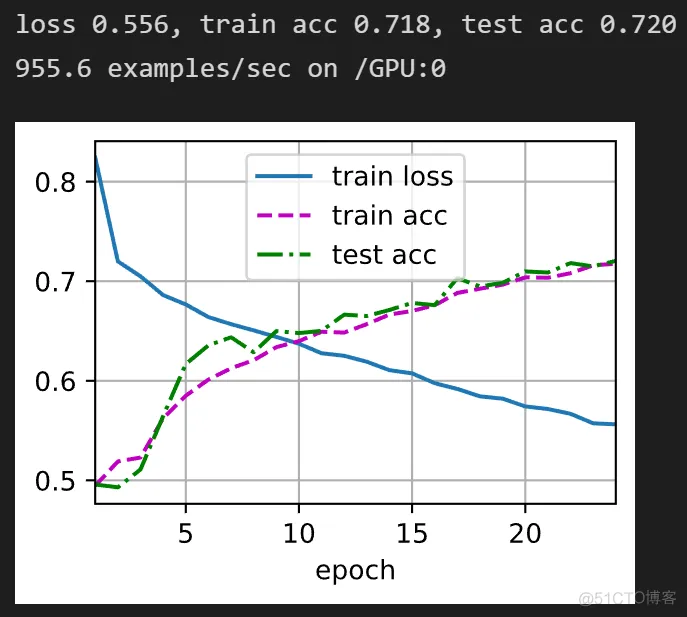
看结果分析证明数据读取和划分应该是问题不大的,现在对于数据集的处理和网络的输入也熟悉一点了。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















