















































软件

产品


本章概述:在第一章的系列文章中介绍了tf框架的基本用法,从本章开始,介绍与tf框架相关的数据读取和写入的方法,并会在最后,用基础的神经网络,实现经典的Mnist手写数字识别。
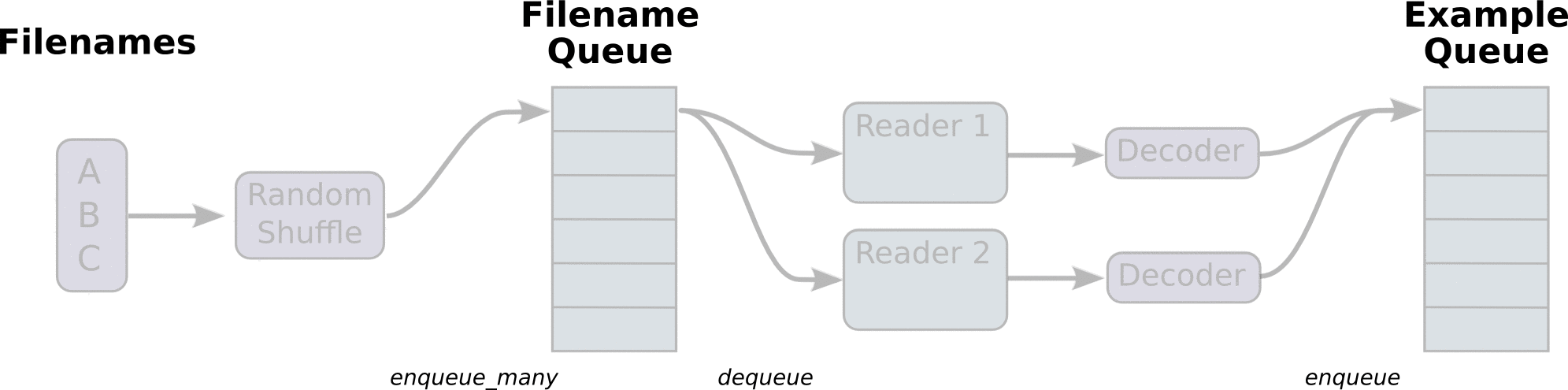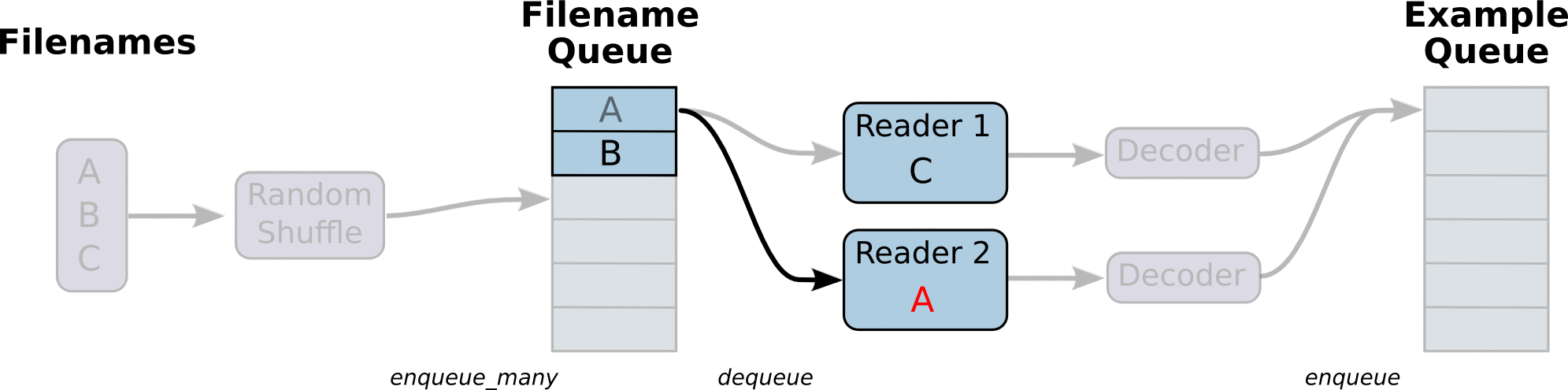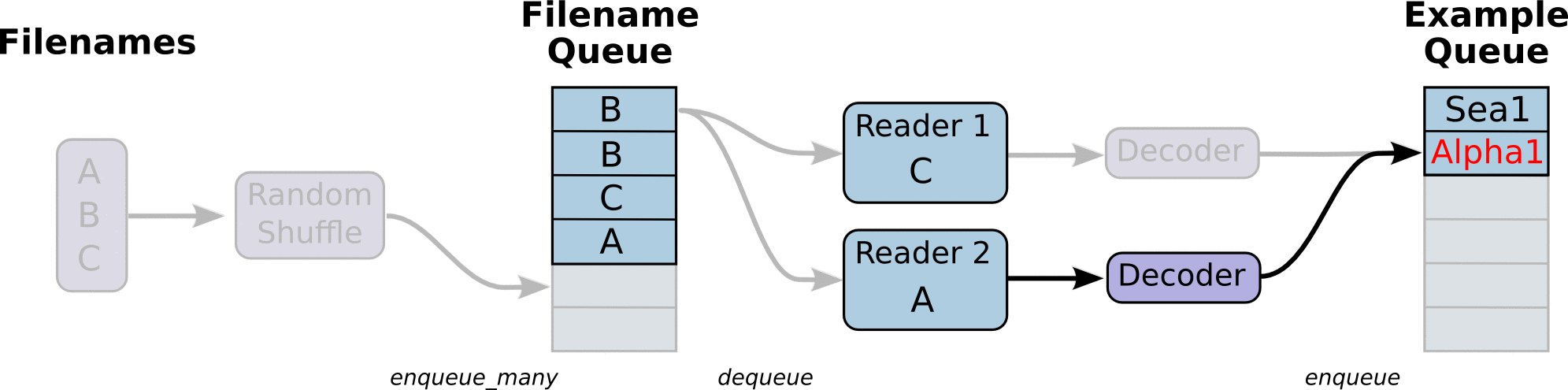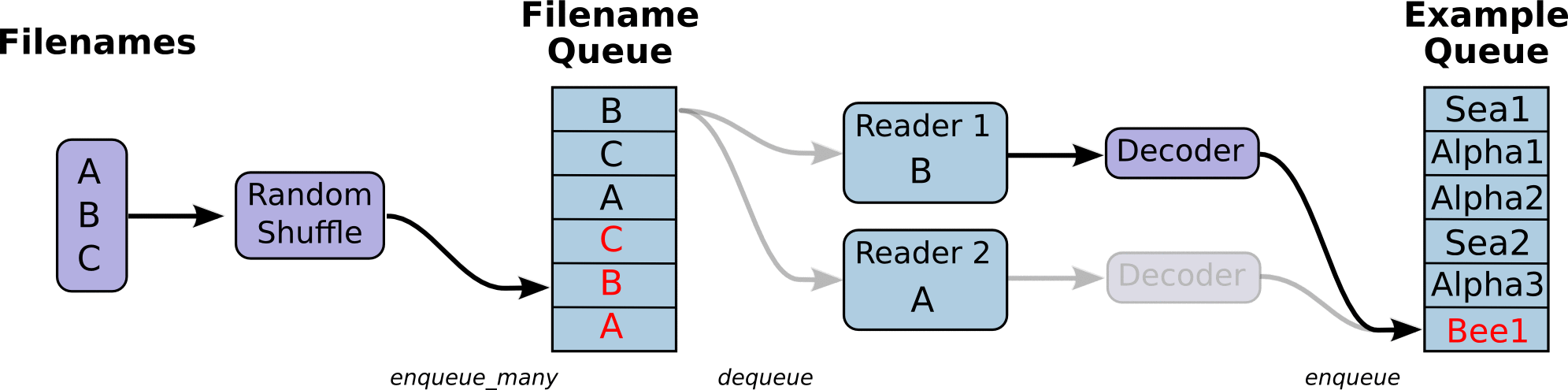
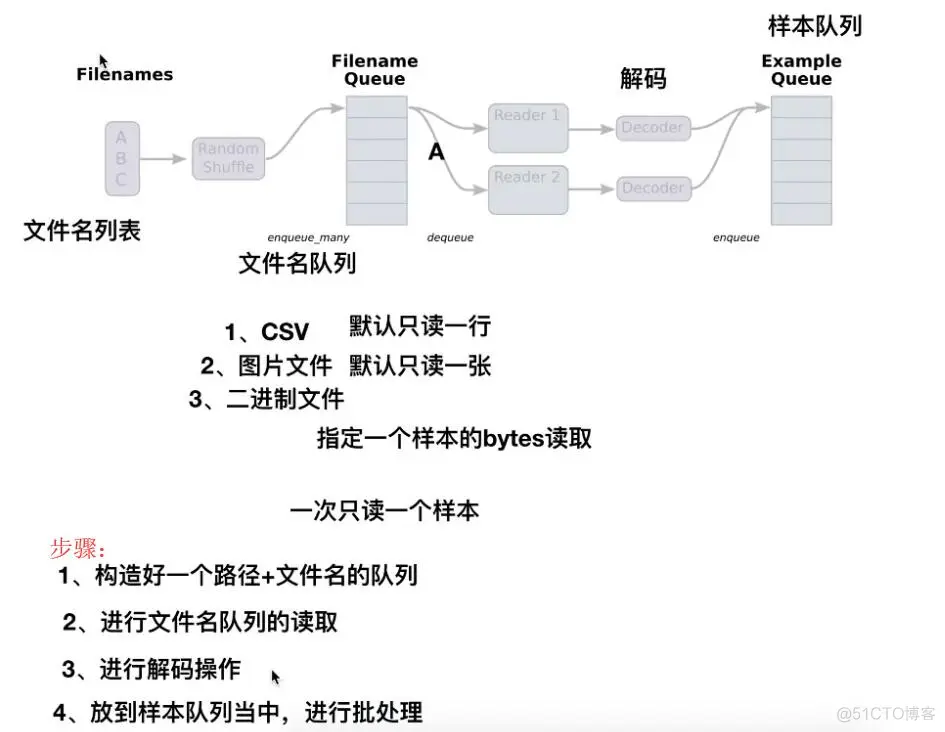
我们称之为构造文件队列,将需要读取的文件装入到一个固定的队列当中
这里需要从队列当中读取文件内容,并且进行解码操作。关于读取内容会有一定的规则
TensorFlow默认每次只读取一个样本,具体到文本文件读取一行、二进制文件读取指定字节数(最好一个样本)、图片文件默认读取一张图片、TFRecords默认读取一个example
1、他们有共同的读取方法:read(file_queue):从队列中指定数量内容返回一个Tensors元组(key文件名字,value默认的内容(一个样本))2、由于默认只会读取一个样本,所以通常想要进行批处理。使用tf.train.batch或tf.train.shuffle_batch进行多样本获取,便于训练时候指定每批次多个样本的训练
对于读取不通的文件类型,内容需要解码操作,解码成统一的Tensor格式
解码阶段,默认所有的内容都解码成tf.uint8格式,如果需要后续的类型处理继续处理
在解码之后,我们可以直接获取默认的一个样本内容了,但是如果想要获取多个样本,这个时候需要结合管道的末尾进行批处理
以上的创建这些队列和排队操作称之为tf.train.QueueRunner。每个QueueRunner都负责一个阶段,并拥有需要在线程中运行的排队操作列表。一旦图形被构建, tf.train.start_queue_runners 函数就会要求图中的每个QueueRunner启动它的运行排队操作的线程。(这些操作需要在会话中开启)
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















