















































软件

产品


Tensorflow 现在将 Dataset 作为首选的数据读取手段,而 Iterator 是 Dataset 中最重要的概念。这篇文章的目的是,以官网文档为基础,较详细的介绍 Iterator 的用法。
在文章开始之前,首先得对 Dataset 和 Iterator 有一个感性的认识。
Dataset 是数据集,Iterator 是对应的数据集迭代器。
如果 Dataset 是一个水池的话,那么它其中的数据就好比是水池中的水,Iterator 你可以把它当成是一根水管。
在 Tensorflow 的程序代码中,正是通过 Iterator 这根水管,才可以源源不断地从 Dataset 中取出数据。
但为了应付多变的环境,水管也需要变化,Iterator 也有许多种类。
下面,细细道来。
创建单次迭代器,非常的简单,只需要调用 Dataset 对象相应的方法。
make_one_shot_iterator()1.这个方法会返回一个 Iterator 对象。
而调用 iterator 的 get_next() 就可以轻松地取出数据了。
import tensorflow as tfdataset = tf.data.Dataset.range(5)iterator = dataset.make_one_shot_iterator()with tf.
Session() as sess: while True: try: print(sess.run(iterator.get_next()))
except tf.errors.OutOfRangeError: break1.2.3.4.5.6.7.8.9.上面的代码非常简单,首先创建了一个包含 0 到 4 的数据集。然后,创建了一个单次迭代器。
通过循环调用 get_next() 方法就可以将数据取出。
需要注意的是,通常用 try-catch 配合使用,当 Dataset 中的数据被读取完毕的时候,程序会抛出异常,获取这个异常就可以从容结束本次数据的迭代。
然后, iterator 就完成了它的历史使命。单次的迭代器,不支持动态的数据集,它比较单纯,它不支持参数化。
什么是参数化呢?你可以理解为单次的 Iterator 认死理,它需要 Dataset 在程序运行之前就确认自己的大小,但我们都知道 Tensorflow 中有一种 feeding 机制,它允许我们在程序运行时再真正决定我们需要的数据,很遗憾,单次的 Iterator 不能满足这要的要求。
单次 Iterator 无法满足参数化的要求,但有其他类型的 Iterator 可以完成这个目标。
先看一段代码,问问自己,你觉得它能正常运行吗?
def initialable_test(): numbers = tf.placeholder(tf.int64,shape=[]) dataset = tf.data.Dataset
.range(numbers) iterator = dataset.make_one_shot_iterator() with tf.Session() as sess:
while True: try: print(sess.run(iterator.get_next(),feed_dict={numbers:5}))
except tf.errors.OutOfRangeError: break1.2.3.4.5.6.7.8.9.10.答案是否定的,程序会报错。
ValueError: Cannot capture a placeholder (name:Placeholder, type:Placeholder) by value.1.原因,我前面刚刚有讲过,因为他是单词迭代器。
不过,我们可以这样改写代码:
def initialable_test(): numbers = tf.placeholder(tf.int64,shape=[]) dataset = tf.data.Dataset
.range(numbers) # iterator = dataset.make_one_shot_iterator()
iterator = dataset.make_initializable_iterator() with tf.Session() as sess:
sess.run(iterator.initializer,feed_dict={numbers:5}) while True:
try: print(sess.run(iterator.get_next()))
except tf.errors.OutOfRangeError: break
sess.run(iterator.initializer,feed_dict={numbers:6}) while True:
try: print(sess.run(iterator.get_next()))
except tf.errors.OutOfRangeError: break1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.运行程序,结果就是打印了 01234,012345 相信大家可以很容易明白发生了什么。
跟单次 Iterator 的代码只有 2 处不同。
你可以这样理解,Dataset 这个水池连续装了 2 次水,每次水量不一样,但可初始化的 Iterator 很好地处理了这件事情,但需要注意的是,这个时候 Iterator 还是面对同一个 Dataset。
有时候,需要一个 Iterator 从不同的 Dataset 对象中读取数值。Tensorflow 针对这种情况,提供了一个可以重新初始化的 Iterator,它的用法相对而言,比较复杂,但好在不是很难理解。
def reinitialable_iterator_test(): training_data = tf.data.Dataset.range(10)
validation_data = tf.data.Dataset.range(5) iterator = tf.data.Iterator
.from_structure(training_data.output_types,
training_data.output_shapes) train_op = iterator.make_initializer(training_data)
validation_op = iterator.make_initializer(validation_data) next_element = iterator.get_next()
with tf.Session() as sess: for _ in range(3): sess.run(train_op)
for _ in range(3): print(sess.run(next_element)) print('===========')
sess.run(validation_op) for _ in range(2): print(sess.run(next_element))
print('===========')1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.它的运行结果如下:
012===========01===========012===========01===========012===========01===========1.2.3.4.5.6.
7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.核心代码其实只有 3 行。
iterator = tf.data.Iterator.from_structure(training_data.output_types,
training_data.output_shapes) train_op = iterator.make_initializer(training_data)
validation_op = iterator.make_initializer(validation_data)1.2.3.4.Iterator 可以接多个水池里面的水,但是要求这水池里面的水是同样的品质。
也就是,多个 Dataset 中它们的元素数据类型和形状应该是一致的。
通过 from_structure() 统一规格,后面的 2 句代码可以看成是 2 个水龙头,它们决定了放哪个水池当中的水。
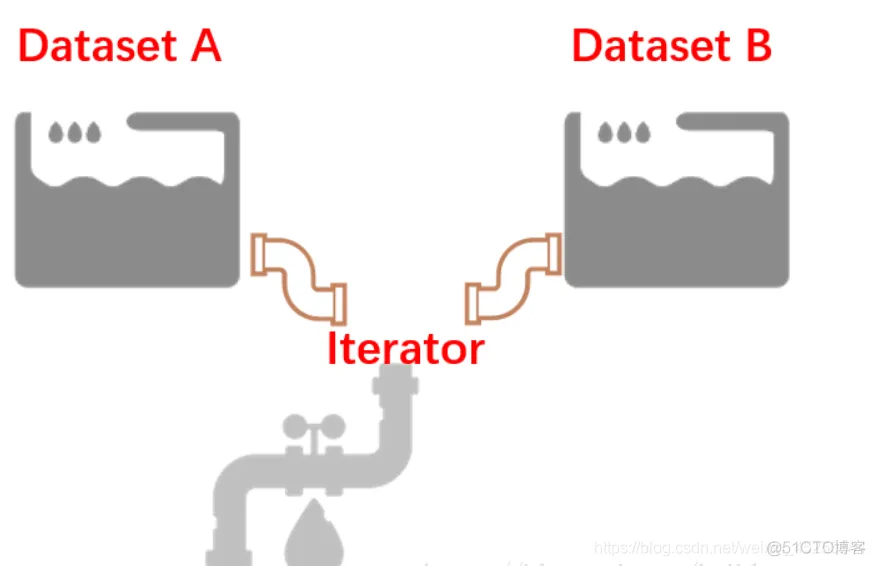
不知道大家注意到一点没有?每次 Iterator 切换时,数据都从头开始打印了。如果,不想这种情况发生,就需要接下来介绍的另外一种 Iterator。
Tensorflow 最美妙的一个地方就是 feeding 机制,它决定了很多东西可以在程序运行时,动态填充,这其中也包括了 Iterator。
不同的 Dataset 用不同的 Iterator,然后利用 feeding 机制,动态决定,听起来就很棒,不是吗?
我们都知道,无论是在机器学习还是深度学习当中,训练集、验证集、测试集是大家绕不开的话题,但偏偏它们要分离开来,偏偏它们的数据类型又一致,所以,经常我们要写同样的重复的代码。
复用,是软件开发中一个重要的思想。
可馈送的 Iterator 一定程度上可以解决重复的代码,同时又将训练集和验证集的操作清晰得分离开来。
def feeding_iterator_test(): train_data = tf.data.Dataset.range(100).map(
lambda x : x + tf.random_uniform([],0,10,tf.int64) ) val_data = tf.data.Dataset.range(5)
handle = tf.placeholder(tf.string,shape=[]) iterator = tf.data.Iterator.from_string_handle(
handle,train_data.output_types,train_data.output_shapes) next_element = iterator.get_next()
train_op = train_data.make_one_shot_iterator() validation_op = val_data.make_initializable_iterator()
with tf.Session() as sess: train_iterator_handle = sess.run(train_op.string_handle())
val_iterator_handle = sess.run(validation_op.string_handle()) for _ in range(3):
for _ in range(2): print(sess.run(next_element,feed_dict={handle:train_iterator_handle}))
print('======') sess.run(validation_op.initializer)
for _ in range(5): print(sess.run(next_element,feed_dict={handle:val_iterator_handle}))
print('======')1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.看起来跟前面以小节的代码没有多大区别。核心代码如下:
handle = tf.placeholder(tf.string,shape=[])iterator = tf.data.Iterator.from_string_handle(
handle,train_data.output_types,train_data.output_shapes)train_iterator_handle = sess.run(train_op.
string_handle())val_iterator_handle = sess.run(validation_op.string_handle())1.2.3.4.5.它是通过一个 string 类型的 handle 实现的。
需要注意的一点是,string_handle() 方法返回的是一个 Tensor,只有运行一个 Tensor 才会返回 string 类型的 handle。不然,程序会报错。
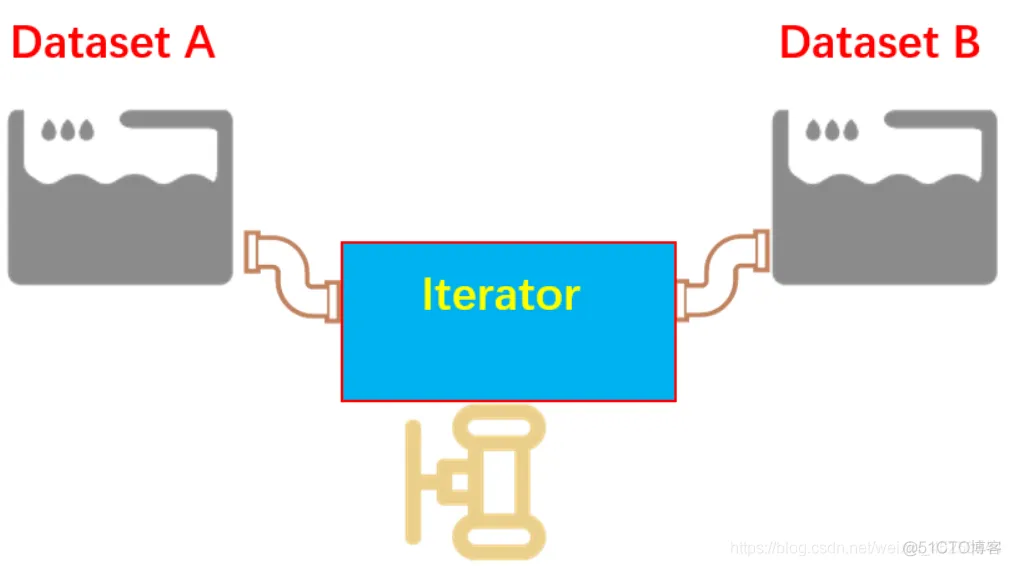
如果用图表的形式加深理解的话,那就是可馈送 Iterator 的方式,可以自主决定用哪个 Iterator,就好比不同的水池有不同的水管,不需要用同一根水管接到不同的水池当中去了。
可馈送的 Iterator 和可重新初始化的 Iterator 非常相似,但是,可馈送的 Iterator 在不同的 Iterator 切换的时候,可以做到不从头开始。
相信阅读到这里,你已经明白了这 4 中 Iterator 的用法了。
终上所述,在真实的神经网络训练过程当中,可馈送的 Iterator 是最值得推荐的方式。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















