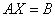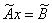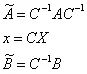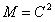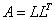软件

产品


在之前的文章【数值算法】共轭梯度法求解线性方程组中,我们指出,共轭梯度法是求解对称正定系数的线性方程组的极为有效的方法,并且指出:对于n阶线性方程组,通常最多n+1次迭代可以获得收敛。在实际的有限元开发实践中,需要求解的经常是非常大,极端大的线性方程组,此时,采用共轭梯度法,有时可能需要上万次的迭代才能收敛,虽然每次收敛的计算量并不大,但是整体求解也会花费较多时间。
实际上,共轭梯度法能否快速收敛与系数矩阵A密切相关。文献【1】指出,对于共轭梯度法存在以下定理:
如果A=I+B为nxn的对称正定矩阵,且rank(B)=r,则共轭梯度法至多r+1步收敛。其中I指单位矩阵,rank是矩阵的秩。
从该定理可知,共轭梯度法能否快速收敛,主要取决于“A”是否“接近于”单位矩阵。特别地,当A就是单位矩阵时,rank(B)=0,此时一步即可收敛,当然这是很显然的。
基于上述定理,多种基于共轭梯度法法衍生的预处理共轭梯度法(PCG)得以广泛地应用。具体来说,实际过程如下:
假设要求解的方程是
预处理共轭梯度法的思想是求解
其中,
并且,C为对称正定矩阵,且使得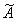
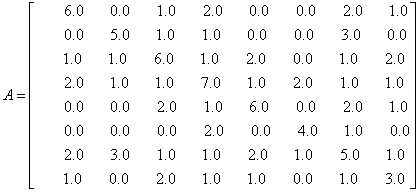
结合原始的共轭梯度法,可以得到以下的预处理共轭梯度法(PCG):
从上述算法中可以看出,其主要改动是需要首先求解
这一预处理方程,得到Zk的值后再代替原来的rk进行运算。采用不同的M,当然就会得到不同的Zk,最终影响共轭梯度法的收敛性。很显然,对于整个原始方程的PCG求解效率来说,首先这个预处理方程需要比较容易求解,否则求解该预处理方程就已经花费了较多时间,则整个原始方程求解效率自然不会高。其次,M的选取需要确实能够减少迭代步数。这两方面在实际中往往是冲突的,例如,假设M取为简单的单位矩阵,则Zk就是rk,几乎不需要求解,此时PCG共轭梯度法就退化为普通的共轭梯度法,预处理相当于未生效;假设M取原始系数矩阵A,则很显然,一步迭代就能得到最终解,但是求解该预处理方程,本质上就和求解原始方程无二。
在实践中,尤其是有限元程序开发中,常见的M的选取至少有两种:对角线预处理和不完备的Cholesky预处理。
1)对角线预处理:对角线预处理指的就是M矩阵为原始系数矩阵A的对角线矩阵。在知名的开源有限元软件FEAPpv中,就是采用的这种方法进行共轭梯度法预处理。一般情况下,这种方法求解预处理方程十分简单,但是通常对于系数矩阵严格对角占优(即对角线元素大于该行其他元素之和)的情况下才比较有效。例如之前文章中待求解的系数矩阵为:
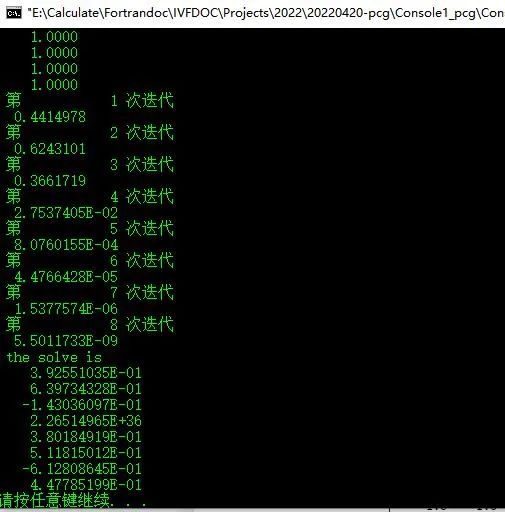
该矩阵并不严格对角占优,采用对角线预处理共轭梯度法求解结果如下:
采用对角线预处理,迭代次数并无太多改善。
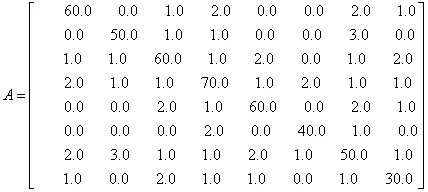
但是如果系数矩阵A的对角线扩大10倍:
采用共轭梯度法求解:
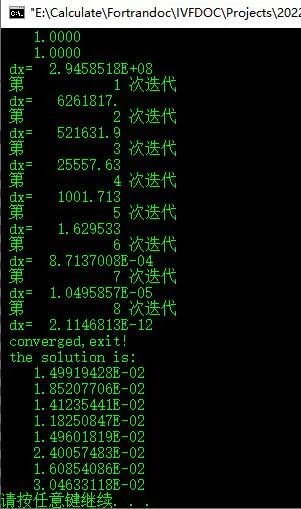
而采用对角线预处理共轭梯度法求解:
采用对角线预处理共轭梯度法仅需4次迭代即获得收敛结果。
2)不完备的Cholesky分解预处理
不完备的Cholesky分解预处理指的是对系数矩阵A进行不完备的Cholesky分解。常规的Cholesky分解如下:
其中,A是正定矩阵,L是下三角矩阵。而在不完备的Cholesky预处理共轭梯度法中,也是对A进行此分解,但是仅对于A中非0元素进行分解,A中的0元素在L中依然是0,或者甚至是求解过程中只在内存中存取A的非0元素。
求得系数矩阵A的不完备的下三角矩阵L后,
令
再采用预处理共轭梯度法的具体算法获得最终解。当然,由于L是下三角矩阵,因此预处理方程一般通过两次“回代”(参考本公众号文章[数值算法与编程]高斯消去法的回代部分)即可求解。
以之前的文章共轭梯度法中的原始方程求解为例,采用不完备Cholesky分解预处理求解如下:
仅需3次迭代,即获得收敛解,而原来的常规共轭梯度法需要9次迭代。并且,matlab计算结果如下:
通过对比不难看出,虽然仅仅是3次迭代,但是已经具备较高的求解精度。
在实际开发中,共轭梯度法还有较多的发挥空间,比如,比如,知名有限元大师Thomas J.R. Hughes在1983年创立了一种基于共轭梯度法的element by element算法,这种方法不需要组装整体刚度矩阵,而是通过逐个单元进行求解,求解效率很高,且由于不需要组装整体刚度矩阵,计算过程中的内存需求显著减少,并且免去了常规的采用稀疏矩阵存储有限元刚度矩阵的组装过程,实际上,相较于常规的矩阵,对于CSR,CSC等格式的有限元整体刚度稀疏矩阵组装,并不是一件十分容易的事情。以上,就是共轭梯度法(二)之预处理共轭梯度法的全部内容,感谢您的阅读!
【完】
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020