















































软件

产品


matlab是一种高级技术计算语言和交互式环境,广泛用于工程、科学和金融等领域。matlab可以进行数值计算、可视化和编程等操作,并且拥有许多预先编写好的工具箱,方便用户快速完成各种任务。
matlab的优点包括:
总之,matlab是一款功能强大而又易于学习和使用的科学计算软件,适用于各种数据分析、建模和仿真等工作。
数据处理是指对数据进行收集、整理、分析和转换等操作,以便更好地理解和利用数据。以下是一些常见的数据处理步骤:
使用 matlab 进行数据处理,可以按照以下步骤进行操作:
readtable 函数读取文本文件,使用 xlsread 函数读取 excel 文件等。isnan 函数、unique 函数等等。mean 函数、std 函数、var 函数、corrcoef 函数等等。plot 函数、scatter 函数、histogram 函数等等。以上是一个简单的流程,当然在实际处理数据时会更加复杂,要根据实际情况具体分析。
要在MATLAB中导入数据,可以使用以下方法:
在MATLAB主界面中点击“Home”选项卡中的“Import Data”按钮,在弹出的“Import Tool”窗口中选择要导入的文件,然后按照提示进行操作即可。
在MATLAB命令行窗口中使用load函数或readtable函数来导入数据,例如:
load('data.mat'); % 导入MAT文件
data = readtable('data.csv'); % 导入CSV文件
其中,load函数可以导入MATLAB工作区中保存的MAT文件,而readtable函数可以导入包含表格数据的CSV、TXT等格式的文件。
以下是一个简单的 MATLAB 数据清理代码的示例:
% 加载数据
data = readtable('data.csv');
% 删除缺失值
data = rmmissing(data);
% 删除重复项
data = unique(data);
% 删除不需要的列
data(:, {'column1', 'column2'}) = [];
% 重命名列
data.Properties.VariableNames{'oldname'} = 'newname';
% 更改数据类型
data.column3 = string(data.column3);
% 将数据导出为 CSV 文件
writetable(data, 'clean_data.csv');
实际数据清理可能会更加复杂并涉及许多其他操作。此外,具体的数据清理步骤取决于数据本身以及要解决的问题,因此需要根据情况进行调整。
以下是一个简单的 MATLAB 数据分析代码示例,用于计算一组数据的平均值和标准差:
% 假设数据存储在 data.txt 文件中,每个数据之间以空格或制表符隔开
data = importdata('data.txt');
% 计算平均值和标准差
mean_value = mean(data);
std_deviation = std(data);
% 输出结果
fprintf('平均值:%f\n', mean_value);
fprintf('标准差:%f\n', std_deviation);
该代码首先使用 importdata 函数将数据从指定的文件中导入到 MATLAB 中。然后,使用 mean 和 std 函数计算平均值和标准差。最后,使用 fprintf 函数输出结果。
以下是一些常用的方法:
plot 函数绘制数据的趋势变化。例如:x = 0:0.01:2*pi;
y = sin(x);
plot(x,y)
scatter 函数绘制数据的分布情况。例如:x = randn(100,1);
y = randn(100,1);
scatter(x,y)
bar 函数绘制数据的数值大小。例如:x = [1 2 3 4 5];
y = [10 8 6 4 2];
bar(x,y)
pie 函数绘制数据的比例关系。例如:x = [30 20 50];
labels = {'A', 'B', 'C'};
pie(x, labels)
contour 函数绘制数据的等高线分布情况。例如:[x,y,z] = peaks(25);
contour(x,y,z)
这里只是列举了一些常用的可视化函数和示例,当然还有很多其他的可视化方法和函数。
以下是MATLAB实现对Wine-Quality数据处理的基本代码:
% 读取数据文件
wine_data = readtable('winequality-red.csv');
% 提取自变量和因变量
X = table2array(wine_data(:, 1:11));
Y = table2array(wine_data(:, 12));
% 数据预处理
% 对自变量进行缩放
X = zscore(X);
% 划分训练集和测试集
cv = cvpartition(size(X, 1), 'HoldOut', 0.3);
X_train = X(cv.training,:);
Y_train = Y(cv.training,:);
X_test = X(cv.test,:);
Y_test = Y(cv.test,:);
% 训练模型
model = fitlm(X_train, Y_train);
% 预测结果
Y_pred = predict(model, X_test);
% 计算均方误差(MSE)
mse = immse(Y_test, Y_pred);
% 显示结果
disp(['MSE: ', num2str(mse)]);
% 绘制散点图对比真实值和预测值
scatter(Y_test, Y_pred);
hold on;
% 绘制一条y=x的直线表示理想情况下真实值和预测值完全相等
plot(min(Y_test):max(Y_test), min(Y_test):max(Y_test));
xlabel('true quality');
ylabel('predicted quality');
title('wine quality prediction results');
legend('predicted vs. true', 'ideal');
上述代码中,首先我们读取了一个名为“winequality-red.csv”的数据文件,它包含了红葡萄酒的化学成分以及品质评级。接着,我们提取了自变量和因变量并进行了数据预处理,其中对自变量进行了缩放以便更好地训练模型。然后,我们将数据划分为训练集和测试集,使用线性回归模型训练了模型,并利用测试数据集对其进行验证。最后,我们计算出均方误差并显示结果。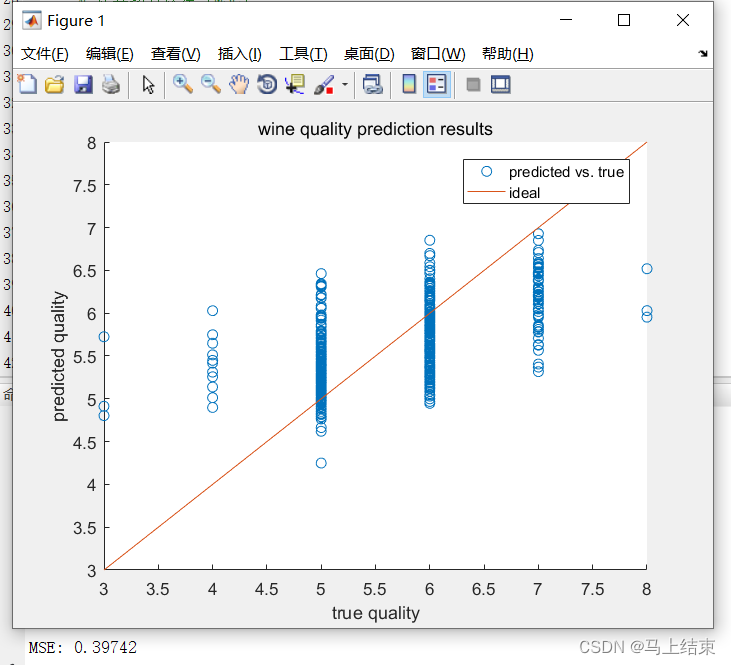
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















