软件

产品


随着当前对机器人智能化和通用性需求的不断提高,越来越多的需要机器人能够快速方便的获取生产、生活技能,并在动态不确定环境下结合经验记忆获取新技能。制约机器人在更多领域和场景发展的因素主要体现在以下几个方面:
1)对环境和任务的适应性差,机器人技能泛化能力弱;
2)学习技能需要大量样本数据,训练时间长,新任务往往需要重新学习;
3)不能回忆和利用所学知识和经验。
故需要研究使机械臂具有人类学习的技巧的方法,在不确定条件下,无人为干预,结合经验以优化方式产生主动行为完成任务。
2、研究方法
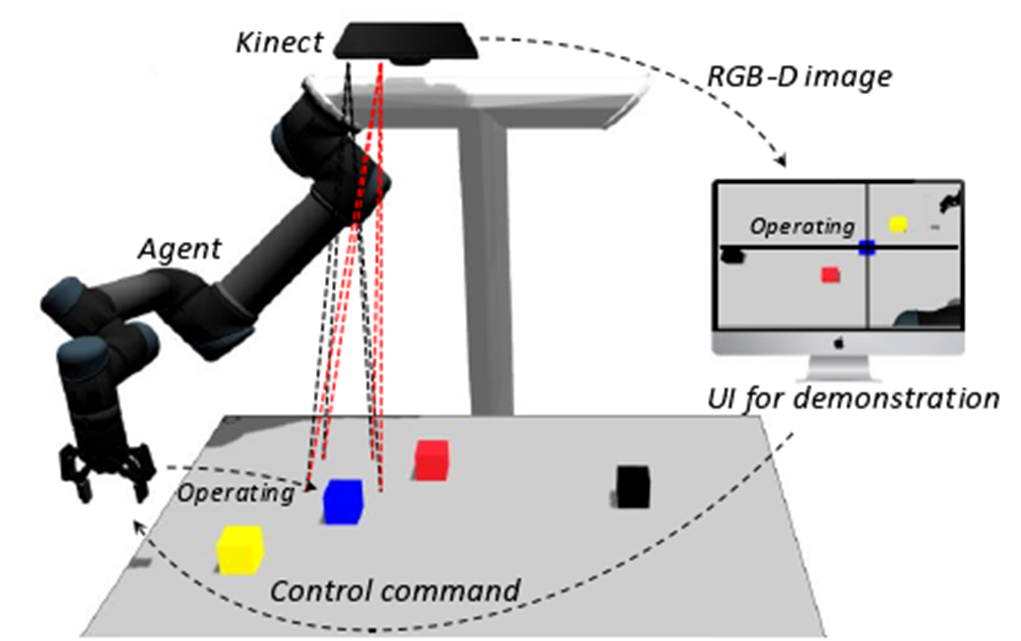
此文结合模仿学习和强化学习,对机器人在自主学习掌握新运动技能这一科学问题开展探索研究。首先,基于 RGB-D 图像能够映射三维空间信息的属性,提出了一种与 RGB-D 图像交互的机械臂示教方法,其结合智能交互思想并面向任务级示教。Kinect V2 作为视觉传感器实现物体识别和定位,基于 MoveIt!运动规划软件实现高层动作规划。将 RGB-D 图像作为示教平台,在图像中与一个物体交互并选择一个高阶动作,引导机械臂在实际工作空间操作对应的物体,多步的交互组成了一项运动技能的示教轨迹。
图1 RGB-D图像交互示教
然后,开展了从示教中学习技能的研究。根据人类技能获取行为和 RGBD-ID 方法每一步与一个物体和一个动作交互的特点,提出一种由目标物推理网络(Objects list network, OLN)和策略学习网络(Policy learning network, PLN)组成的模仿学习架构OPLN。OLN和 PLN 均由 LSTM 神经网络构建,其中OLN 学习了物体的操作顺序关系,PLN 学习了物体的状态属性,从而机器人能够在较高的认知水平上实现自主推理和技能获取。在无人为干预的情况下完成从示教中学习到策略。
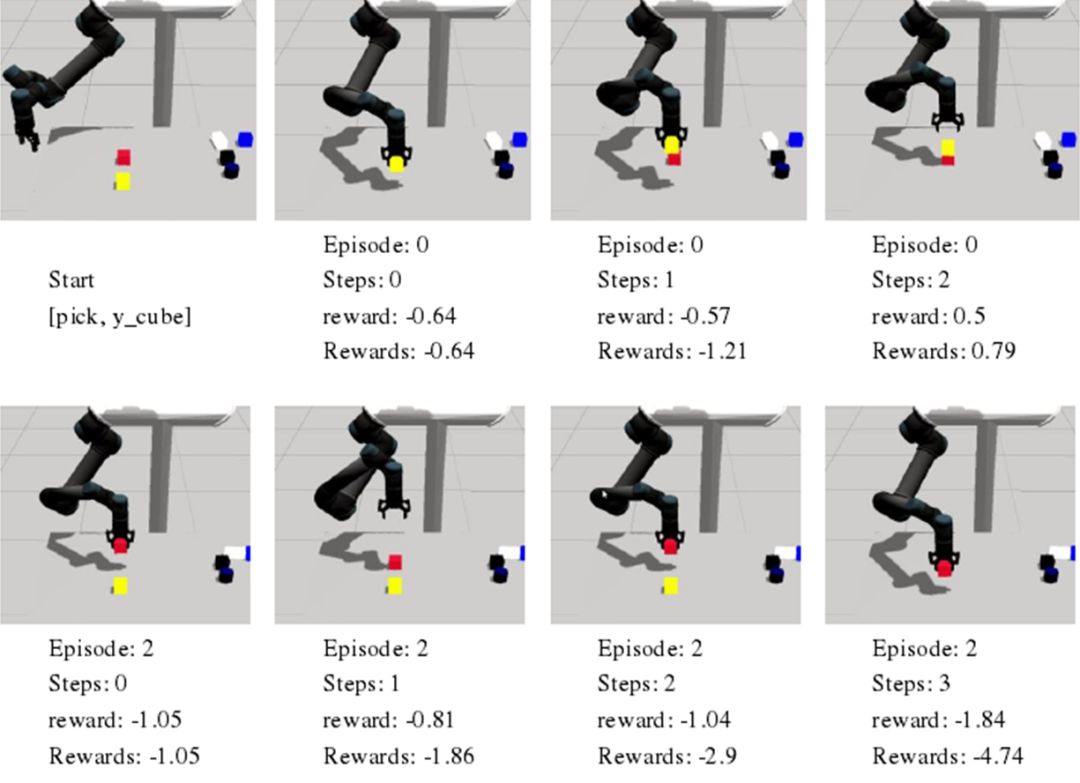
再次,进行了基于强化学习的机械臂运动技能获取研究,通过与环境交互自主学习策略。针对机器人操作任务,提出一种基于物体构形匹配(Objects configurationmatching)的通用的奖赏函数设计方法,根据向量相似性度量方法计算物体目标构形和当前构形的相似性,构建即时奖赏为关于该相似性的函数。以 Actor-Critic 算法为主体结构搭建了机械臂强化学习模型,结合设计的奖赏函数学习优化技能策略。
图2 强化学习部分训练过程
最后,针对上述方法搭建了相应的实验平台。实验平台的硬件系统包括 UR5 机械臂、气动二指手抓、Kinect V2 深度摄像头等;软件系统由ROS 机器人操作系统、MoveIt!运动规划库、Matlab、pytorch神经网络框架等组成。设置了堆叠积木任务和 Pick and Place任务,验证了本文RGBD-ID 方法、模仿学习模型和强化学习模型用于机械臂获取运动技能的有效性和可行性。
图3 机器人堆积木模仿学习过程
3、研究结论
针对机器人智能化的需求,进行了基于模仿学习和强化学习的机械臂运动技能获取的研究。提出了一种人-图像交互式示教方法,一种基于 LSTM 神经网络的模仿学习框架,开展了机械臂强化学习获取技能的工作。针对工作过程中出现的问题,不断递进的提出解决方案。最终,通过堆叠积木任务和 Pick and Place 任务验证了方法的有效性,提高了机械臂的学习能力。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020