

































































 著作权
著作权

Monarch是Google的大规模监控系统,服务于Google全球大规模实时业务监控,其实现为超大规模时序数据库集群,被公认为当今全球最大规模的时序数据库。Monarch本身没有开源,主要信息来源于Google在2020年8月份发表在PVLDB上的一篇论文:Monarch: Google’s Planet-Scale In-Memory Time Series Database。这篇文章是Medium上一篇介绍Google Monarch的文章的中文翻译,原文链接:Understanding Monarch, Google’s Planet-Scale Monitoring System。
以下为正文,斜体字是我加的备注:
Monarch是Google开发的大规模内存时序数据库,用于Google的大部分内部系统(如Spanner, BigTable, Colossus, BlobStore)的可靠监控系统。
与任何其他的Google服务一样,它必须被设计为大规模、高可用并且支持区域局域性。但与其他服务不同的是,Monarch需要尽可能少的依赖其他Google服务,这一点非常重要,因为其他服务都在使用Monarch对自己进行监控,因此如果有相互依赖关系,任何一方的服务中断都会影响到另一方。
Monarch是一种必须支持高可用性和分区性的服务,因此在最终一致性有延迟的情况下,它通过向客户服务提供一定的提示来解决低一致性的问题。
这意味着Monarch是AP系统,支持最终一致性而不是强一致性,这也是大规模分布式系统设计的普遍做法。
Monarch的数据存储
数据以两种格式存储:
- Leaves(叶子)组件在内存中存储实际的监控数据
- Logs(日志)是持久化存储,可用于在组件失败时重放事件
Leaf是内存中的缓存存储模块,Log用来做持久化和高可用,在服务失效的时候可用于快速恢复数据。
Monarch的数据获取
Data Ingestion Pipeline(数据接收管道)遵循如下原则:
- 将客户端服务的数据存储在距离服务运行的zone越近越好,从而减少网络延迟
- 将客户服务的数据存储在同一个Leaf中,因为数据查询很有可能被集中在该Leaf上,以获得更快的查询响应
就近原则和内聚原则,从而尽可能提高访问性能。
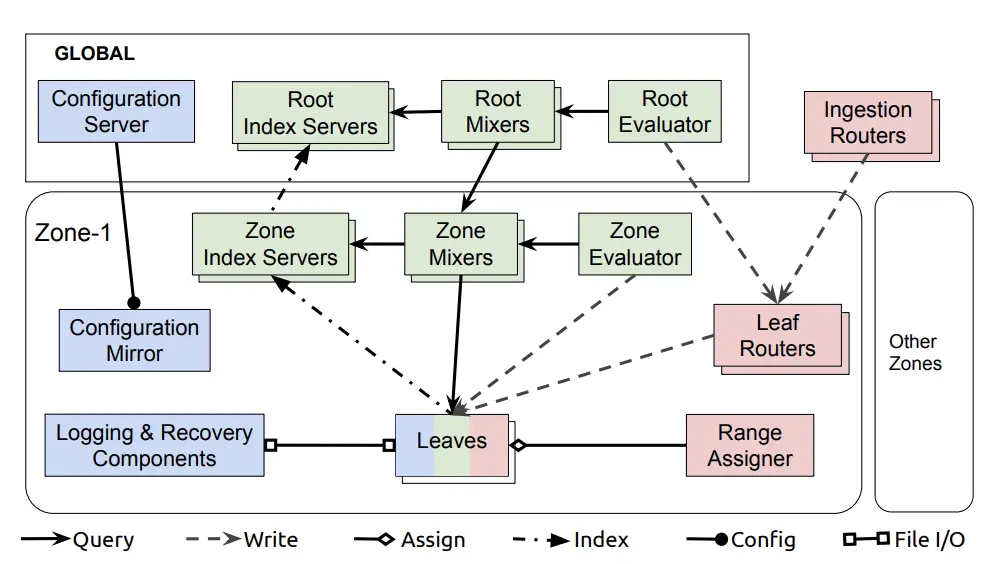
以下情况将触发数据传输:
- Ingestion Router(数据接收路由器)将数据发送给叶子路由器
- Leaf Router(叶子路由器)将数据发送给叶子
- Range Assigner(分配器)决定存储数据的叶子
数据接收路由器根据位置字段将时间序列数据分区,叶子路由器根据分配器的决定将数据分布在叶子上。
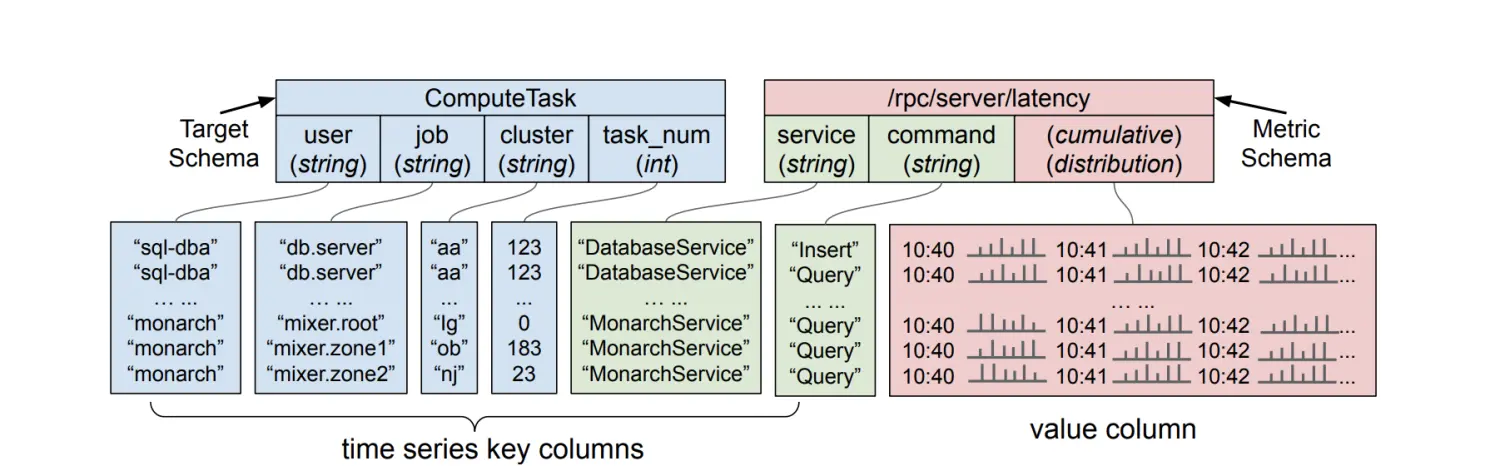
接收到的数据包含以下几类:
Targes(目标)用于识别数据生成的节点/服务/组件。以上图为例,目标字符串ComputeTask::sql-dba::db.server::aa::0876表示数据库服务器的Borg任务。目标字符串的格式对于决定数据在叶子之间的存储位置很重要,因为目标范围用于决定叶子之间的字典分片和负载均衡。
Metrics(指标)以key-value(键值对)的格式包含指标信息,其中键是目标的指标类型,值是基于时间序列的数据点。支持的度量类型有boolean、int64、double、string、distribution或tuple。度量值可以是cumulative(累计值),也可以是gauge(测量值)。使用累计值的优点是偶尔的数据丢失对统计分布的影响不大。
distribution实际上是一个double list,由许多个 bucket组成,每个bucket里有一个double值,用于表示数据分布范围的统计。举个栗子:
有一个访问延迟的distribution定义了4个bucket: 0-10ms, 10-20ms, 20-30ms, 30ms以上,每个bucket里的double数值定义了在这个延迟范围内的访问次数。
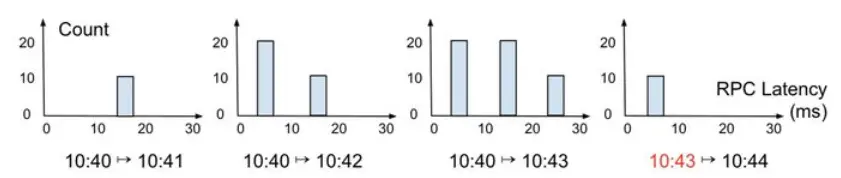
数据可以以Delta Time Series(增量时间序列)的格式发送,这样只需要发送时间序列数据中的增量,而不是整个指标数据。这减少了数据的连续输入,并且只需要在数据有变化的时候进行处理。
Bucketing在将数据发送到数据接收管道之前的一段时间内负责聚合数据,从而减少网络处理,并且可以实现批量插入。
Admission windows用于丢弃在一定时间后接收到的数据,从而避免处理过期数据的压力。
因为Bucketing会在一定时间内聚合数据,然后存到叶子并且持久化,这样如果有数据来晚了,对应的Bucket已经完成了处理,就需要将迟到的数据丢弃。
数据查询
Monarch提供了一个全局联合查询引擎,所有查询都可以在全局级别启动,Monarch负责将查询路由到存储相关数据的叶子,并整合来自叶子的响应。
上面的模块图显示了查询相关的模块:
- Mixers将查询分解为子查询,并合并来自子查询的响应。根Mixer接收查询并将它们发送到zone mixer,zone mixer进一步将其发送到叶子,从而形成查询树。Mixers还查询索引服务器,将查询限制在数据所在的zone或叶子。
- Index servers(索引服务器)索引每个zone和叶子的数据,这些数据可用于确定查询针对哪些叶子。
- Evaluators从standing query生成响应,并将数据写回叶子。
Standing query类似SQL中的View(视图)的概念,用户可以自定义standing query,evaluator会定期查询standing query的结果,并写回对应的叶子,从而可以加快查询速度。
Monarch支持如下查询语义:
- Fetch
- Filter
- Join
- Align
- GroupBy
Ad-hoc queries是来自系统外部用户的查询。
Standing queries是类似于其他数据库系统中的视图的查询,定期计算并存储到Monarch中,以获得更快的查询响应。根据查询的广度,standing query可以在zone或root级别进行评估,将查询空间最小化到特定zone的叶子,从而获得更好的性能。
Level analysis用于对查询进行级别分析,基于不同的级别将查询打破重组,用以进行认证和获得更好的查询局部性。查询级别可以根据上面提到的查询树进行定义。
Replica Resolution用于找出响应查询的最佳副本。因为查询负载、系统配置、数据完整性等方面可能存在差异,因此某个副本可能更适合响应查询请求。
User Isolation用来限制任一用户在系统中可以使用的内存量,以便其他遵守规则的用户不受影响。
性能
- Monarch分布在横跨五大洲的38个zone,执行大约400,000个任务。
- 截至2019年7月,Monarch存储了近9500亿时间序列,其高度优化的数据结构消耗了约750TB内存。
- 2019年7月,Monarch的内部部署每秒接收约4.4TB的数据。
-
Monarch持续指数级增长,截至2019年7月,每秒服务超过600万次查询。
 性能
性能
 技术文档
技术文档
 热门文章
热门文章








 155-2731-8020
155-2731-8020