















































软件

产品


最近研究mediapipe 这个东东,感觉有点意思,有点上瘾。如果实现了姿态检测,那么我们可以用这些姿态检测的坐标做一下项目了,比如说,如何检测健身举哑铃的动作检测,虽然功能十分简单,但是要用Python 去实现一个动作的检测,在代码层次来讲还是很繁琐的。 下面讲解一下如何使用python+opencv+mediapipe实现姿态检测,并对举哑铃这个动作进行识别。
要实现上面所说的功能,需要实现以下步骤,下面我们一步一步的实现下面的步骤,以完成整个的功能。
首先是运行环境的检测, 要看下你的mediapipe 与opencv-python 依赖是成功安装,并且 摄像头 能成功的采集到你的那张帅脸,如果这些都没有问题,那么就可以进行下面的操作了。
pip install mediapipe opencv-python
import cv2
import mediapipe as mp
import numpy as np
mp_drawing = mp.solutions.drawing_utils
mp_pose = mp.solutions.pose
# VIDEO FEED
cap = cv2.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
cv2.imshow('Mediapipe Feed', frame)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
cap = cv2.VideoCapture(0)
## Setup mediapipe instance
## 开启我们的姿态检测进程函数,这里有两个指标检测置信度和跟踪置信度,作用是控制模型检测的准确度和灵敏度
with mp_pose.Pose(min_detection_confidence=0.5, min_tracking_confidence=0.5) as pose:
while cap.isOpened():
ret, frame = cap.read()
# Recolor image to RGB
## 摄像投的数据都是以BGR的形式,但是模型处理要以RGB,所以这里的颜色空间要进行转换
image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
image.flags.writeable = False
# Make detection
results = pose.process(image)
# Recolor back to BGR
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
# Render detections
##然后进行画点和连线的操作了
mp_drawing.draw_landmarks(image, results.pose_landmarks, mp_pose.POSE_CONNECTIONS,
mp_drawing.DrawingSpec(color=(245,117,66), thickness=2, circle_radius=2),
mp_drawing.DrawingSpec(color=(245,66,230), thickness=2, circle_radius=2)
)
cv2.imshow('Mediapipe Feed', image)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
代码的功能我基本上已经在注释中阐述明白了, 完成了上面的步骤,那么基本上就能够检测到你的姿态的模型了。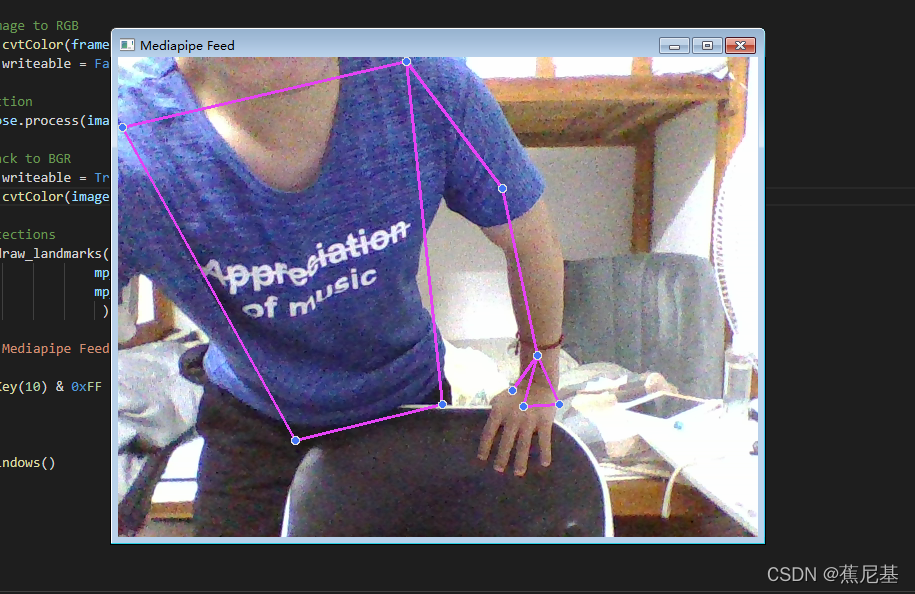
下图是姿态检测模型中的33个关节点,我们会获取所需要的关节点的坐标,然后进行 算法 的计算,以达到我们所需的功能需求。下面我会获取我们的其
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















