















































软件

产品


众所周知的是,我们生活在一个充满“大数据”的社会生活当中,比如豆瓣图书,电影推荐等等。
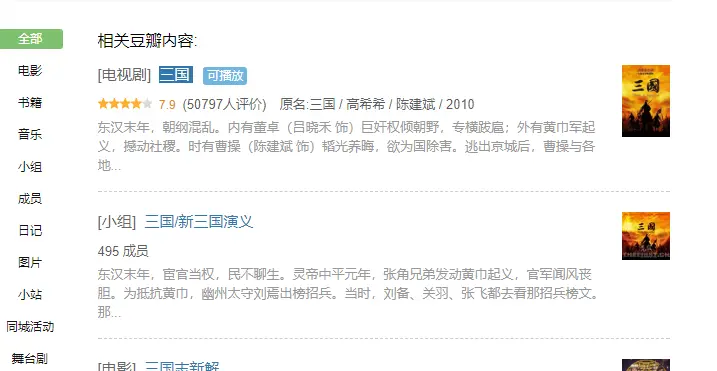
在豆瓣,我们可以看到我们想要观看的影视作品的豆瓣评分
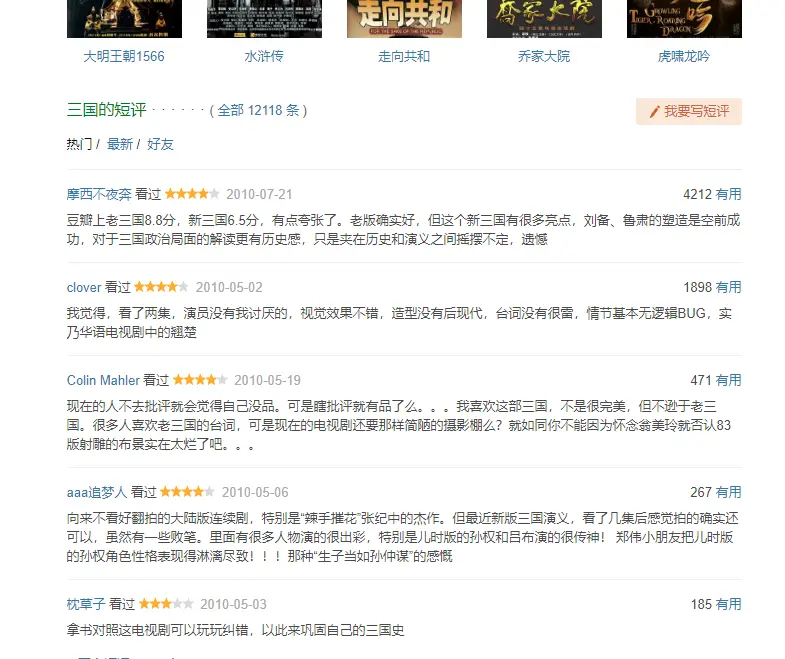
图上方是与新三国相类似的影视作品,下方是观看者对新三国的评价等等
针对于传统推荐,即基于内容,基于用户,以及基于商品的推荐,一种现有推荐算法,既融合协同过滤推荐,又包含用户,或者商品的推荐算法。
现在简单介绍基于基于用户的协同过滤推荐算法:
如图1所示,在推荐系统中,用m×n的打分矩阵表示用户对物品的喜好情况,一般用打分来表示用户对商品的喜好程度,分数越高表示该用户对这个商品越感兴趣,而数值为空表示不了解或是没有买过这个商品。
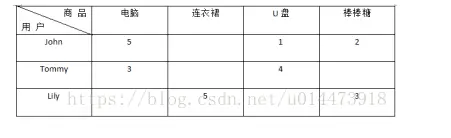
用于个性化推荐系统的打分矩阵
如图2所示,基于用户的协同过滤推荐算法是指找到与待推荐商品的用户u兴趣爱好最为相似的K个用户,根据他们的兴趣爱好将他们喜欢的商品视为用户u可能会感兴趣的商品对用户u进行推荐。
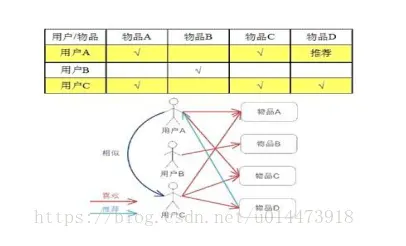
基于用户的协同过滤算法
从以上介绍可以看出,基于用户的协同过滤推荐算法主要分为两步,第一步是求出用户之间的相似度,第二步是根据用户之间的相似度找出与待推荐的用户最为相似的几个用户并根据他们的兴趣爱好向待推荐用户推荐其可能会感兴趣的商品。
用户之间的相似度的计算主要可以通过Jaccard公式和余弦相似度公式得到。
若有读者对上述内容感兴趣可以点击下方链接:
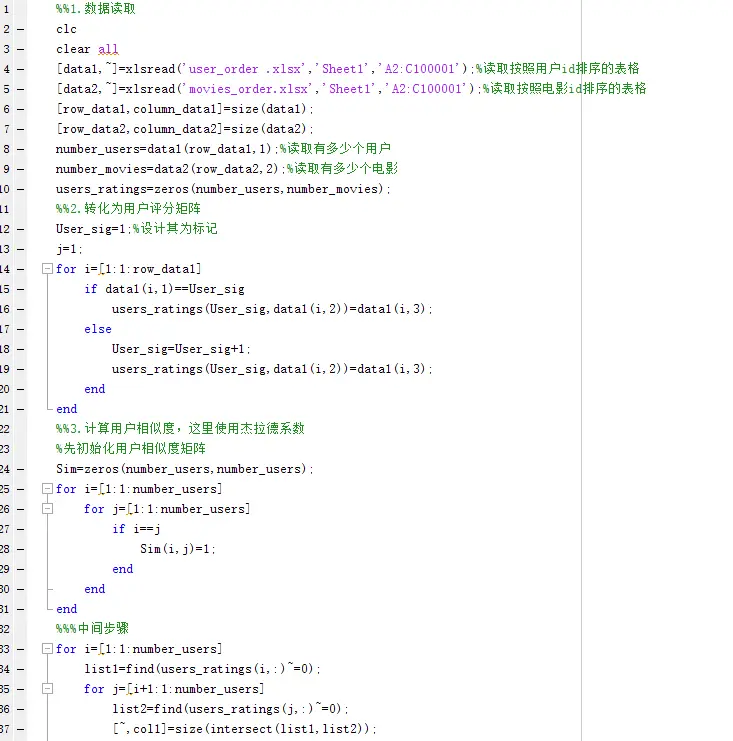
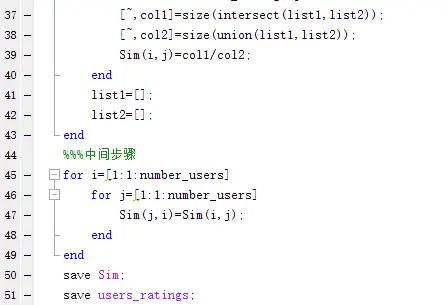
通过上述两步,我们可以得到用户相似度矩阵,如图:
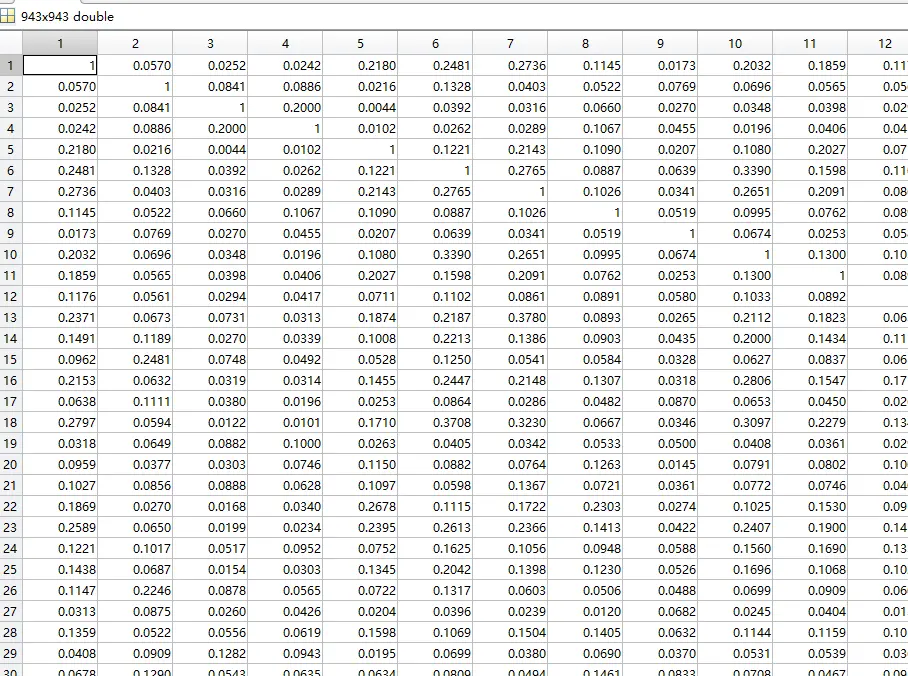
之后,我们再计算某用户对未给评分的电影预测分数,

之所以乘5,是因为评分最高分为5,在数据标准化之后,乘以最大额度就是预测分数
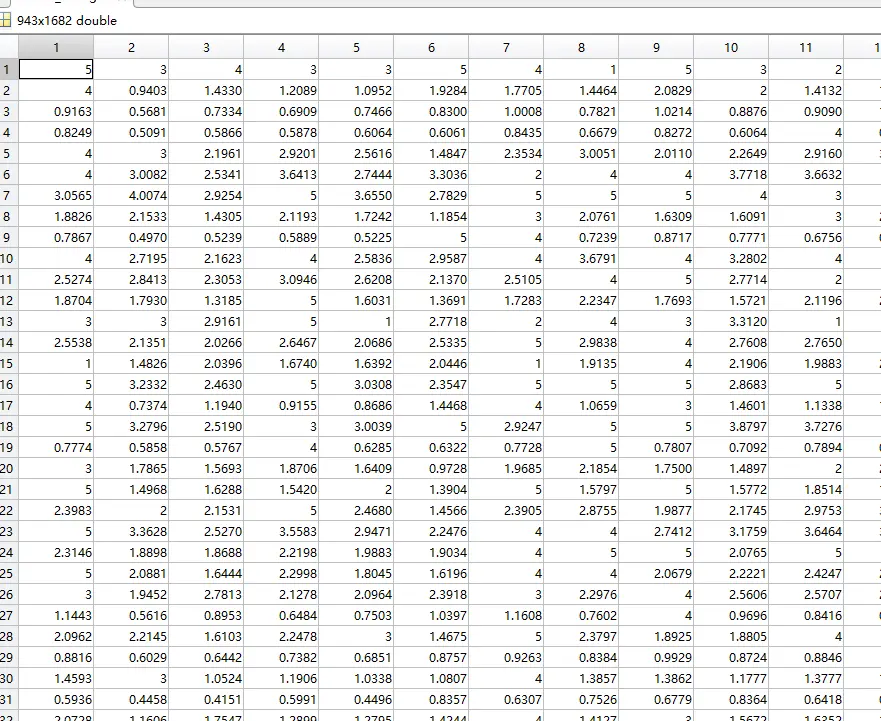
打开用户评分矩阵,即可得出完整的评分矩阵
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















