















































软件

产品


导读
一个Tensorflow训练后量化的工具,不用再单独训练一个低精度模型了,原来的全精度模型直接就可以转换。
我们非常激动地添加训练后float16量化作为模型优化工具包的一部分。这是一套工具,包括:混合量化,全整数量化和剪枝。
训练后的float16量化减少了TensorFlow Lite模型的尺寸(高达50%),同时牺牲了很少的精度。它量化模型常量(如权重和偏差值)从全精度浮点数(32位)到降低精度浮点数数据类型(IEEE FP16)。
训练后的float16量化是量化TensorFlow Lite模型的一个很好的起点,因为它对精度的影响很小,而且模型大小显著减小。你可以查看我们的文档:https://www.tensorflow.org/lite/performance/posttrainingquantization (包括一个新的浮点图!),以帮助您了解不同的量化选项和场景。

降低精度有很多好处,特别是当部署到边缘设备时:
减少2倍的模型大小。模型中的所有常量值都存储在16位浮点数中,而不是32位浮点数。由于这些常量值通常控制整个模型大小,因此通常会将模型大小减少大约一半。
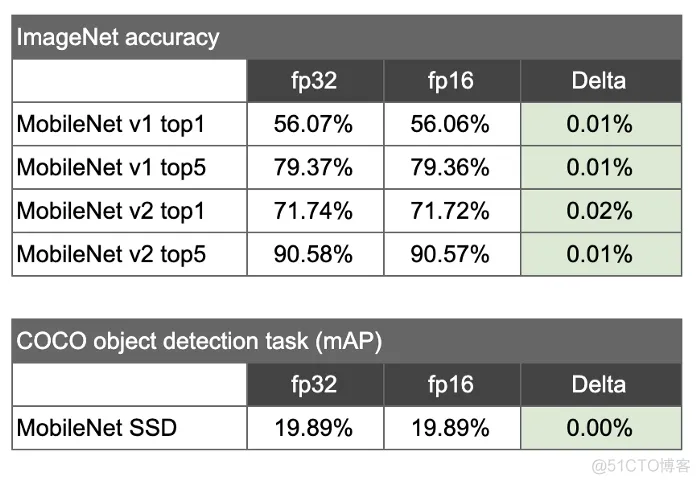
可忽略的精度损失。深度学习模型通常能够在使用比最初训练时更少的精度的情况下产生良好的推理结果。在我们对几个模型的实验中,我们发现推理质量几乎没有损失。例如,下面我们展示了MobileNet V2的Top 1精度降低了<0.03%。(见下面的结果)。
训练后float16量化对深度学习模型的精度影响最小,并可使模型的尺寸缩小约2倍。例如,以下是MobileNet V1和V2模型以及MobileNet SSD模型的一些结果。MobileNet v1和v2的精度结果基于ImageNet图像识别任务。SSD模型是在COCO物体检测任务上评估的。
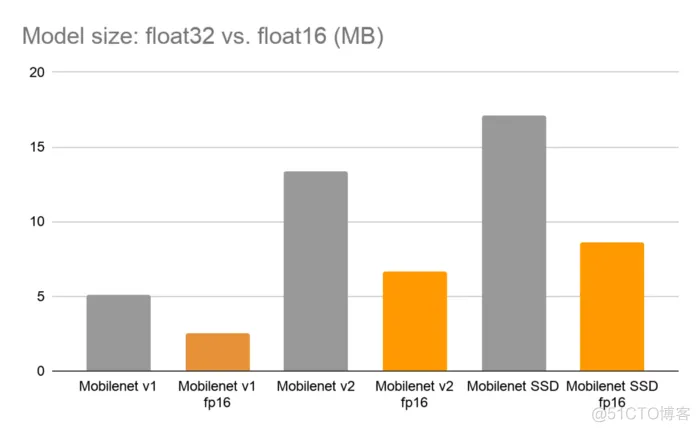
在[ILSVRC 2012图像分类任务上评估标准Mobilenet float32模型及其fp16变体,COCO物体检测任务上评估Mobilenet SSD float32模型及其fp16变体。
如何使用训练后float16量化
你可以在TensorFlow Lite转换器上指定训练后的float16量化,方法是使用你训练后的float32模型,将优化设置为默认,目标规范支持的类型设置为float16常量:
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.lite.constants.FLOAT16]
Tflite_quanit_model = converter.convert()
一旦转换了模型,就可以像其他TensorFlow Lite模型一样直接运行它。默认情况下,模型将在CPU上运行,将16位参数“上采样”到32位,然后执行标准的32位浮点运算。随着时间的推移,我们希望看到更多的硬件支持来加速fp16的计算,从而允许我们将upsample降低到float32,并直接计算这些半精度值。
你也可以在GPU上运行你的模型。我们增强了TensorFlow Lite GPU委托来接受降低的精度参数并直接运行它们(而不是像在CPU上那样转换为float32)。在你的应用中,你可以通过 TfLiteGpuDelegateCreate函数创建GPU委托。当为委托指定选项时,请确保将 precision_loss_allowed设置为1,以便在GPU上使用浮点16操作:
//Prepare GPU delegate.
const TfLiteGpuDelegateOptions options = {
.metadata = NULL,
.compile_options = {
.precision_loss_allowed = 1, // FP16
.preferred_gl_object_type = TFLITE_GL_OBJECT_TYPE_FASTEST,
.dynamic_batch_enabled = 0, // Not fully functional yet
},
};
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















