















































软件

产品


线性模型:
逻辑回归LR:
优势:简单、可解释、易扩展、易并行;
缺点:难以捕获特征组合。
CTR早期用的LR最多,采用【线性模型】+【人工特征组合引入非线性】模式。后面为了解决LR需要人工特征工程的缺陷,大佬们想办法把特征组合能力体现在模型中,如下式子,最后一项是两两特征组合(类似多项式核SVM),。但是这样组合特征泛化能力较弱——尤其是在大规模稀疏特征存在的场景,如CTR预估和推荐排序时:
为了解决刚才说的组合特征泛化能力弱的问题,FM的式子出现(如下),前两项即LR部分,后两项是Dense化的两两特征组合,特征组合的权重计算方式是亮点:为每个特征学习一个大小为k的一维向量,如为两个特征和分别学习到和向量,那么这两个特征组合的权重值,就是两个向量的内积,在2010年时FM这么做,其实和今天的对特征进行embedding化表征是差不多的意思:
机器学习模型因子分解机模型(Factorization Machine)即FM的结构如下图:
1)类别型特征转为one-hot向量
2)将one-hot向量通过embedding层转为稠密的embedding层
3)独特的是这里,使用一个单独的FM层处理特征之间的交叉问题:这里是多个内积操作单元对不同特征向量两两组合
4)将(3)的内积操作结果输入到输出神经元,完成预测
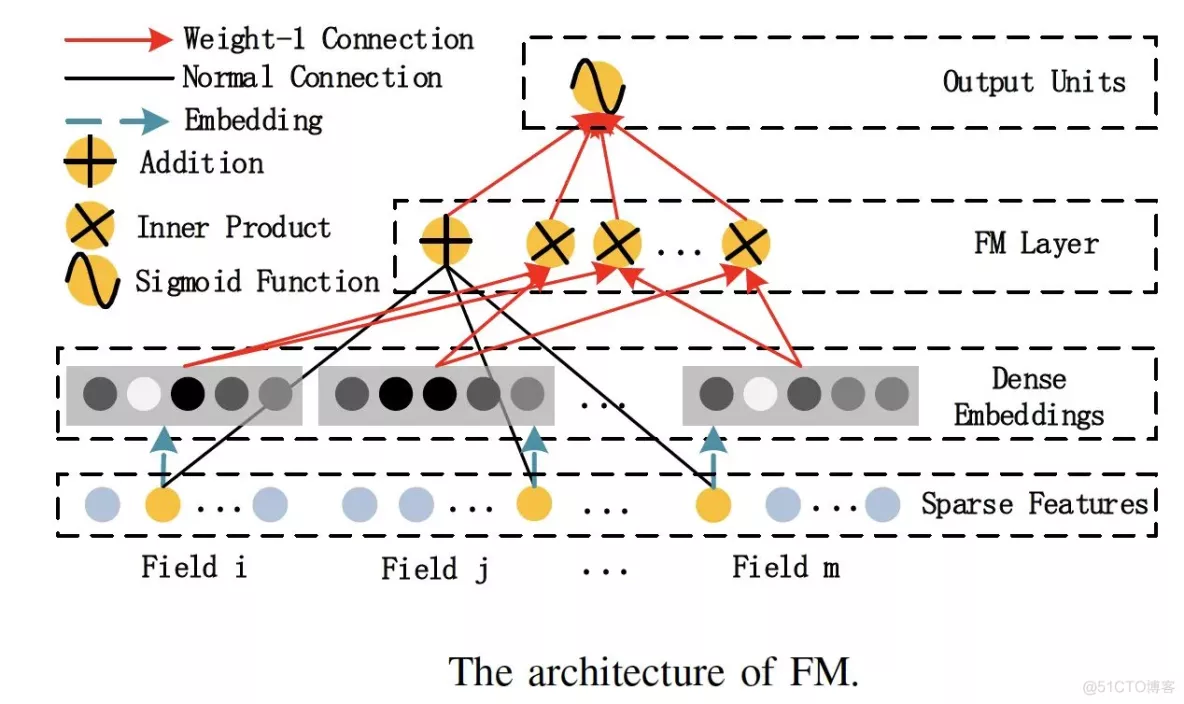
图1 FM的神经网络化结构 (出自论文 DeepFM: A Factorization-Machine based Neural Network for CTR Prediction)
这样回到刚才的栗子,用户喜欢的电影风格和电影本身的风格,通过FM层的两两特征的内积操作,使得特征进行充分的组合,不至于像embedding + MLP一样的MLP内部像黑盒子一样低效地交叉。
FM和DeepFM的特征交叉
逻辑回归模型表达能力不强,容易造成有效信息的损失。辛普森悖论就说明了多维度特征交叉的重要性:分组实验相当于使用【性别】+【视频id】的组合特征计算点击率,而汇总实验则使用【视频id】这一单一特征计算点击率。,即逻辑回归只是对单一特征做简单加权,,从而无法正确刻画数据模式。
算法工程师经验和精力有限,难以找到最优的特征组合,提出POLY2模型进行特征的暴力组合:上面模型中对所有特征都进行两两交叉(特征和),并且所有特征组合有权重W。其本质上还是线性模型。
缺点:
哈工大和华为一起提出DeepFM就是基于wide&deep组合模型的思想,我们可以将以往的FM和其他深度学习模型结合,成为一个全新的强特征组合能力的模型,并且也具有强拟合能力。
注意下图的FM层有个加操作:加操作是不进行特征交叉,直接把原先的特征接入输出层,相当于wide&deep模型中的wide层。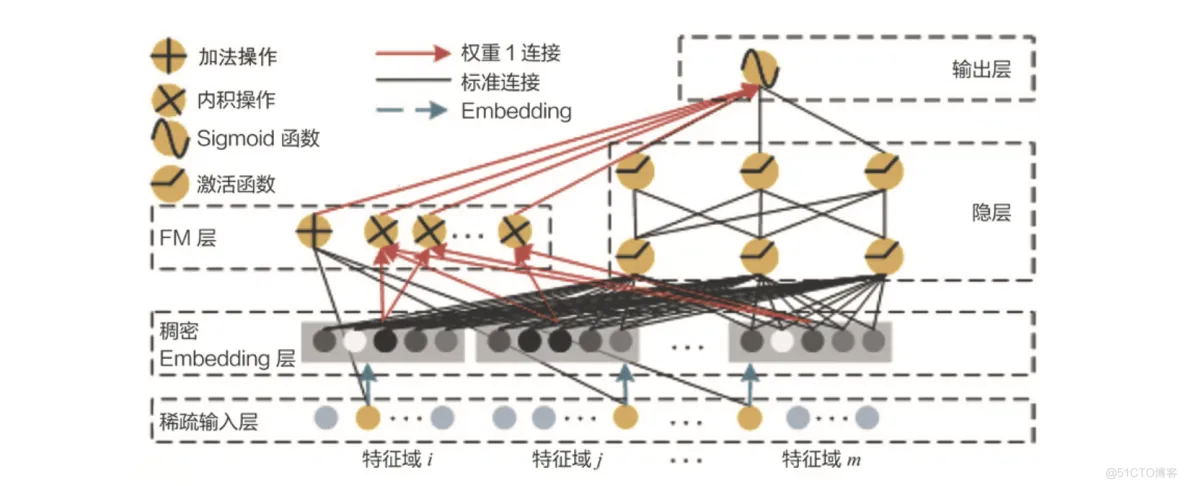
DeepFM模型架构图 (出自论文 DeepFM: A Factorization-Machine based Neural Network for CTR Prediction)
由上图的DeepFM架构图看出:
1)用FM层替换了wide&deep左边你的wide部分;
——加强浅层网络的特征组合能力。
2)右边保持和wide&deep一毛一样,利用多层神经元(如MLP)进行所有特征的深层处理
3)最后输出层将FM的output和deep的output组合起来,产生预估结果
通过get_dataset导入movielen数据集。
import tensorflow as tf"""Diff with DeepFM: 1. separate categorical features from dense features when processing first order features and second order features 2. modify original fm part with a fully crossed fm part"""# load sample as tf datasetdef get_dataset(file_path): dataset = tf.data.experimental.make_csv_dataset( file_path, batch_size=12, label_name='label', na_value="0", num_epochs=1, ignore_errors=True) return dataset# split as test dataset and training datasettrain_dataset = get_dataset('D:/wide&deep/trainingSamples.csv')test_dataset = get_dataset('D:/wide&deep/testSamples.csv')1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.# define input for keras modelinputs = { 'movieAvgRating': tf.keras.layers.Input(name='movieAvgRating',
shape=(), dtype='float32'), 'movieRatingStddev': tf.keras.layers.Input(name='movieRatingStddev', shape=(),
dtype='float32'), 'movieRatingCount': tf.keras.layers.Input(name='movieRatingCount', shape=(),
dtype='int32'
), 'userAvgRating': tf.keras.layers.Input(name='userAvgRating', shape=(), dtype='float32'),
'userRatingStddev': tf.keras.layers.Input(name='userRatingStddev', shape=(), dtype='float32'),
'userRatingCount': tf.keras.layers.Input(name='userRatingCount', shape=(), dtype='int32'),
'releaseYear': tf.keras.layers.Input(name='releaseYear', shape=(), dtype='int32'),
'movieId': tf.keras.layers.Input(name='movieId', shape=(), dtype='int32'),
'userId': tf.keras.layers.Input(name='userId', shape=(), dtype='int32'),
'userRatedMovie1': tf.keras.layers.Input(name='userRatedMovie1', shape=(), dtype='int32'),
'userGenre1': tf.keras.layers.Input(name='userGenre1', shape=(), dtype='string'),
'userGenre2': tf.keras.layers.Input(name='userGenre2', shape=(), dtype='string'),
'userGenre3': tf.keras.layers.Input(name='userGenre3', shape=(), dtype='string'),
'userGenre4': tf.keras.layers.Input(name='userGenre4', shape=(), dtype='string'),
'userGenre5': tf.keras.layers.Input(name='userGenre5', shape=(), dtype='string'),
'movieGenre1': tf.keras.layers.Input(name='movieGenre1', shape=(), dtype='string'),
'movieGenre2': tf.keras.layers.Input(name='movieGenre2', shape=(), dtype='string'),
'movieGenre3': tf.keras.layers.Input(name='movieGenre3', shape=(), dtype='string'),}
# movie id embedding featuremovie_col = tf.feature_column.categorical_column_with_identity(key='movieId',
num_buckets=1001)movie_emb_col = tf.feature_column.embedding_column(movie_col, 10)movie_ind_col = tf
.feature_column.indicator_column(movie_col) # movid id indicator columns
# user id embedding featureuser_col = tf.feature_column.categorical_column_with_identity(key='userId',
num_buckets=30001)user_emb_col = tf.feature_column.embedding_column(user_col, 10)user_ind_col = tf
.feature_column.indicator_column(user_col) # user id indicator columns# genre features
vocabularygenre_vocab
= ['Film-Noir', 'Action', 'Adventure', 'Horror', 'Romance', 'War', 'Comedy', 'Western', 'Documentary',
'Sci-Fi', 'Drama', 'Thriller', 'Crime', 'Fantasy', 'Animation', 'IMAX',
'Mystery', 'Children', 'Musical']# user genre embedding featureuser_genre_col = tf
.feature_column.categorical_column_with_vocabulary_list(key="userGenre1",
vocabulary_list=genre_vocab)user_genre_ind_col = tf.feature_column.indicator_column(user_genre_col)
user_genre_emb_col = tf.feature_column.embedding_column(user_genre_col, 10)
# item genre embedding featureitem_genre_col = tf
.feature_column.categorical_column_with_vocabulary_list(key="movieGenre1",
vocabulary_list=genre_vocab)item_genre_ind_col = tf.feature_column
.indicator_column(item_genre_col)item_genre_emb_col = tf.feature_column
.embedding_column(item_genre_col, 10)
1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.
38.39.40.41.42.43.44.45.46.47.48.49.50.同样回顾下tensorflow提供的特征列类型:
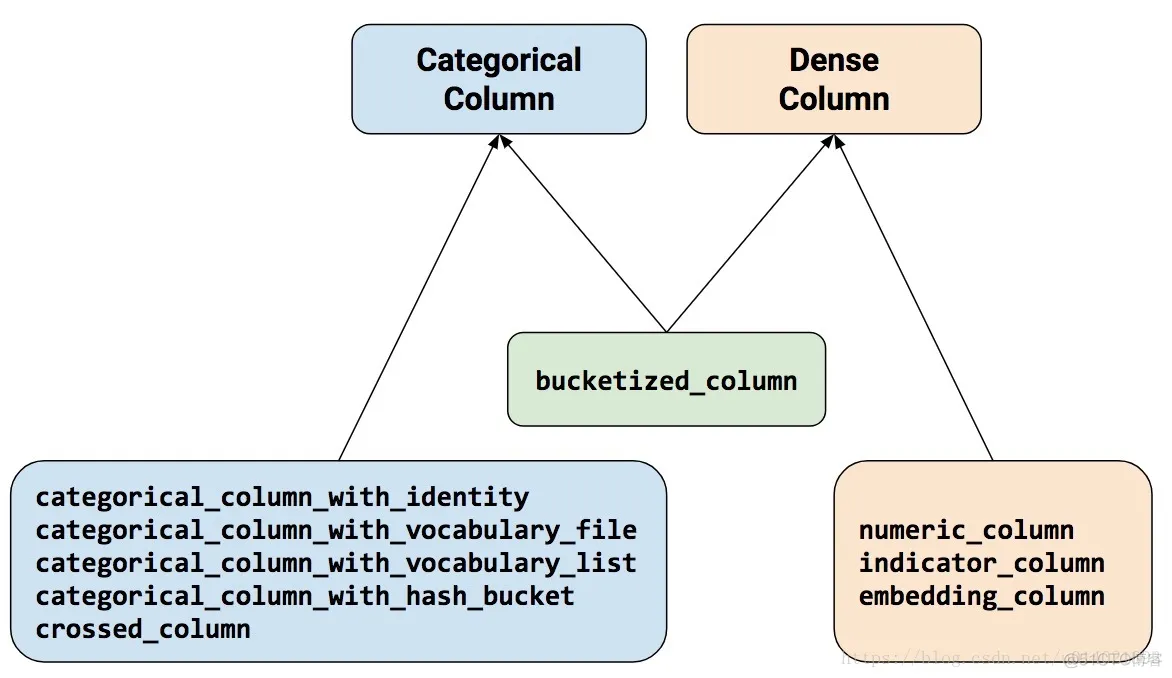
常见的特征预处理方法包括:连续变量分箱化、离散变量one-hot、离散指标embedding等,tensorflow给我们提供了一个功能强大的特征处理函数tf.feature_column,它通过对特征处理将数据输入网络并交由estimator来进行训练:
tf.feature_column.categorical_column_with_identity()函数:把numerical data转乘one hot encoding,只适用于值为整数的类别型变量。key:特征名num_buckets:离散特征的离散取值规模default_value=None:出现新值的默认填充值tf.feature_column.indicator_column能够得到类别特征的multi-hot embedding。在tensorflow中,tf.keras.layers.Dense和tf.keras.layers.DenseFeatures意思不同,前者即常规的全连接层,后者如字面意思,根据feature_columns生成稠密的张量。
# fm first-order categorical itemscat_columns = [movie_ind_col, user_ind_col, user_genre_ind_col,
item_genre_ind_col]deep_columns = [tf.feature_column.numeric_column('releaseYear'),
tf.feature_column.numeric_column('movieRatingCount'),
tf.feature_column.numeric_column('movieAvgRating'),
tf.feature_column.numeric_column('movieRatingStddev'),
tf.feature_column.numeric_column('userRatingCount'),
tf.feature_column.numeric_column('userAvgRating'),
tf.feature_column.numeric_column('userRatingStddev')]first_order_cat_feature = tf.keras.layers
.DenseFeatures(cat_columns)(inputs)first_order_cat_feature = tf
.keras.layers.Dense(1, activation=None)(first_order_cat_feature)first_order_deep_feature = tf
.keras.layers.DenseFeatures(deep_columns)(inputs)first_order_deep_feature = tf.keras
.layers.Dense(1, activation=None)(first_order_deep_feature)## first order featurefirst_order_feature = tf
.keras.layers.Add()([first_order_cat_feature, first_order_deep_feature])1.2.3.4.5.6.7.8.9.10.11.12.13.14.
15.16.17.18.tf.keras.layers.multiply是向量之间的element-wise乘积运算。
second_order_cat_columns_emb = [tf.keras.layers.DenseFeatures([item_genre_emb_col])(inputs),
tf.keras.layers.DenseFeatures([movie_emb_col])(inputs),
tf.keras.layers.DenseFeatures([user_genre_emb_col])(inputs),
tf.keras.layers.DenseFeatures([user_emb_col])(inputs)
]second_order_cat_columns = []for feature_emb in second_order_cat_columns_emb:
feature = tf.keras.layers.Dense(64, activation=None)(feature_emb)
feature = tf.keras.layers.Reshape((-1, 64))(feature)
second_order_cat_columns.append(feature)second_order_deep_columns = tf.keras.layers
.DenseFeatures(deep_columns)(inputs)second_order_deep_columns = tf.keras.layers
.Dense(64, activation=None)(second_order_deep_columns)second_order_deep_columns = tf.keras
.layers.Reshape((-1, 64))(second_order_deep_columns)second_order_fm_feature = tf.keras.layers
.Concatenate(axis=1)(second_order_cat_columns + [second_order_deep_columns])#
# second_order_deep_featuredeep_feature = tf.keras.layers.Flatten()(second_order_fm_feature)deep_feature = tf
.keras.layers.Dense(32, activation='relu')(deep_feature)deep_feature = tf
.keras.layers.Dense(16, activation='relu')(deep_feature)1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.在tensorflow2.0中,如果需要自定义一个layer类,则需要理解清楚__init__()、bulid()、call()函数,似乎__init__()和build()函数都在对Layer进行初始化,都初始化了一些成员函数,而call()函数则是在该layer被调用时执行。
【tensorflow官方推荐】
凡是tf.keras.layers.Layer的派生类都要实现__init__(),build(), call()这三个方法:
__init__():参数初始化,如初始化卷积的一些参数;build():在call()函数第一次执行时会被调用一次,这时候可以知道输入数据的shape。返回去看一看,果然是__init__()函数中只初始化了输出数据的shape,build(),这也解释了为什么在有__init__()函数时还需要使用build()函数call(): 当其被调用时会被执行。class ReduceLayer(tf.keras.layers.Layer): def __init__(self, axis, op='sum', **kwargs): super().__init__() self.axis = axis self.op = op assert self.op in ['sum', 'mean'] def build(self, input_shape): pass def call(self, input, **kwargs): if self.op == 'sum': return tf.reduce_sum(input, axis=self.axis) elif self.op == 'mean': return tf.reduce_mean(input, axis=self.axis) return tf.reduce_sum(input, axis=self.axis)second_order_sum_feature = ReduceLayer(1)(second_order_fm_feature)second_order_sum_square_feature = tf.keras.layers.multiply([second_order_sum_feature, second_order_sum_feature])second_order_square_feature = tf.keras.layers.multiply([second_order_fm_feature, second_order_fm_feature])second_order_square_sum_feature = ReduceLayer(1)(second_order_square_feature)## second_order_fm_featuresecond_order_fm_feature = tf.keras.layers.subtract([second_order_sum_square_feature, second_order_square_sum_feature])1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.拼接三个模块:first_order_feature、second_order_fm_feature、deep_feature,将拼接得到的向量送到最后的sigmoid函数中,进行预测:
concatenated_outputs = tf.keras.layers.Concatenate(axis=1)([first_order_feature, second_order_fm_feature,
deep_feature])output_layer = tf.keras.layers.Dense(1, activation='sigmoid')(concatenated_outputs)model = tf
.keras.Model(inputs, output_layer)# compile the model, set loss function, optimizer
and evaluation metricsmodel
.compile( loss='binary_crossentropy', optimizer='adam', metrics=['accuracy', tf.keras
.metrics.AUC(curve='ROC'), tf.keras.metrics.AUC(curve='PR')])# train the modelmodel
.fit(train_dataset, epochs=5)# evaluate the modeltest_loss, test_accuracy, test_roc_auc, test_pr_auc = model
.evaluate(test_dataset)print('\n\nTest Loss {}, Test Accuracy {}, Test ROC AUC {}, Test PR AUC {}'
.format(test_loss, test_accuracy,
test_roc_auc, test_pr_auc))# print some predict resultspredictions = model
.predict(test_dataset)for prediction, goodRating in zip(predictions[:12], list(test_dataset)[0][1][:12]):
print("Predicted good rating: {:.2%}".format(prediction[0]), "
| Actual rating label: ", ("Good Rating" if bool(goodRating) else "Bad Rating"))1.2.3.4.5.6
.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.2022-03-27 20:34:51.550267: I tensorflow/core/platform/cpu_feature_guard.cc:142] This
TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN)to use the
following CPU instructions in performance-critical operations: AVX AVX2To enable them in other operations,
rebuild TensorFlow with the appropriate compiler flags
.Epoch 1/5D:\anaconda1\envs\tensorflow\lib\site-packages\tensorflow\python\keras\engine\functional.py:540:
UserWarning: Input dict contained keys ['rating', 'timestamp', 'userRatedMovie2', 'userRatedMovie3',
'userRatedMovie4', 'userRatedMovie5', 'userAvgReleaseYear', 'userReleaseYearStddev'] which did not match
any model input. They will be ignored by the model. warnings.warn(7403/7403 [==============================]
- 50s 7ms/step - loss: 7.5576 - accuracy: 0.5619 - auc: 0.5690 - auc_1: 0.6180Epoch 2/57403/7403
[==============================] - 45s 6ms/step - loss: 0.7450 - accuracy: 0.6289 - auc: 0.6625 - auc_1:
0.7007/7403 [======>.......................] - ETA: 34s - loss: 0.9516 - accuracy: 0.5969 - auc: 0.6269
- auc_1: 0.6854Epoch 3/57403/7403 [==============================] - 46s 6ms/step - loss: 0.6031 -
accuracy: 0.6795 - auc: 0.7342 - auc_1: 0.7610Epoch 4/57403/7403 [==============================]
- 46s 6ms/step - loss: 0.5639 - accuracy: 0.7133 - auc: 0.7753 - auc_1: 0.8006Epoch 5/57403/7403
[==============================] - 45s 6ms/step - loss: 0.5255 - accuracy: 0.7410 - auc: 0.8112 - auc_1: 0
.83561870/1870 [==============================] - 5s 3ms/step - loss: 0.6117 - accuracy: 0.6695 -
auc: 0.7239 - auc_1: 0.7510Test Loss 0.611655592918396, Test Accuracy 0.6694741249084473, Test ROC AUC
0.7239346504211426, Test PR AUC 0.7510392069816589Predicted good rating: 75.24% | Actual rating label:
Good RatingPredicted good rating: 60.70% | Actual rating label: Bad RatingPredicted good rating: 89.65%
| Actual rating label: Bad RatingPredicted good rating: 90.05% | Actual rating label:
Bad RatingPredicted good rating: 46.65% | Actual rating label: Bad RatingPredicted good rating: 57.64%
| Actual rating label: Good RatingPredicted good rating: 52.52% | Actual rating label:
Good RatingPredicted good rating: 24.43% | Actual rating label: Bad RatingPredicted good rating: 79.91%
| Actual rating label: Good RatingPredicted good rating: 25.34% | Actual rating label:
Bad RatingPredicted good rating: 71.32% | Actual rating label: Good RatingPredicted good rating: 67.41%
| Actual rating label:1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.除了点积和元素积这两个操作外,还有没有其他的方法能处理两个 Embedding 向量间的特征交叉?
(1)DeepFM的图示中,输入均是类别型特征的one-hot或embedding,请问是因为特征交叉仅适用于类别型特征的交叉吗?数值型特征之间,数值型与类别型特征之间能否进行交叉呢?另外,在DeepFM的wide部分中一阶交叉项是否可以包含未参与特征交叉的数值型特征呢?
【答】按照DeepFM原论文,数值型特征是不参与特征交叉的,因为特征交叉的操作是在两个embedding向量间进行的。但是如果可以,就可以让数值型特征也参与特征交叉。
因为要变成同一维度才能做内积,categorical feature embedding 到 embedding_dim 维, 需要数值型也映射到embedding_dim 维。数值型映射的方式可以是分箱也可以是乘以一个 embedding_dim 的向量。
2)原FM中二阶交叉项中隐向量的内积仅作为权重,但从sparrow代码看,。
问题:这样做是因为教程里所选的特征是one-hot格式,所以维度可能不一致,从而无法进行初始特征的交叉吗?
【答】原FM中内积作为权重,然后还要乘以特征本身的值。但在DeepFM中,所有的参与交叉的特征都先转换成了embedding,而且由于是one-hot,所以特征的值就是1,参不参与交叉都无所谓。所以直接使用embedding的内积作为交叉后的值就可以了。
(3)按FM的交叉方式,不同特征的embedding 向量维度要相同,但实际不同离散特征的维度可能相差很大,如果想用不同的embedding 维度,那应该怎样做交叉,业界有没有这样的处理方式?
【答】几乎不可以。如果一定要做的话,也要在不同embedding层上再加上一层fc layer或者embedding layer,把他们变成一致的,然后交叉。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















