















































软件

产品


深度学习与TensorFlow
DNN(深度神经网络算法)现在是AI社区的流行词。最近,DNN 在许多数据科学竞赛/Kaggle 竞赛中获得了多次冠军。
自从 1962 年 Rosenblat 提出感知机(Perceptron)以来,DNN 的概念就已经出现了,而自 Rumelhart、Hinton 和 Williams 在 1986 年发现了梯度下降算法后,DNN 的概念就变得可行了。直到最近 DNN 才成为全世界 AI/ML 爱好者和工程师的最爱。
主要原因在于现代计算能力的可用性,如 GPU 和 TensorFlow 等工具,可以通过几行代码轻松访问 GPU 并构建复杂的神经网络。
作为一名机器学习爱好者,必须熟悉神经网络和深度学习的概念,但为了完整起见,将在这里介绍基础知识,并探讨 TensorFlow 的哪些特性使其成为深度学习的热门选择。
神经网络是一个生物启发式的计算和学习模型。像生物神经元一样,它们从其他细胞(神经元或环境)获得加权输入。这个加权输入经过一个处理单元并产生可以是二进制或连续(概率,预测)的输出。
人工神经网络(ANN)是这些神经元的网络,可以随机分布或排列成一个分层结构。这些神经元通过与它们相关的一组权重和偏置来学习。
下图对生物神经网络和人工神经网络的相似性给出了形象的对比:
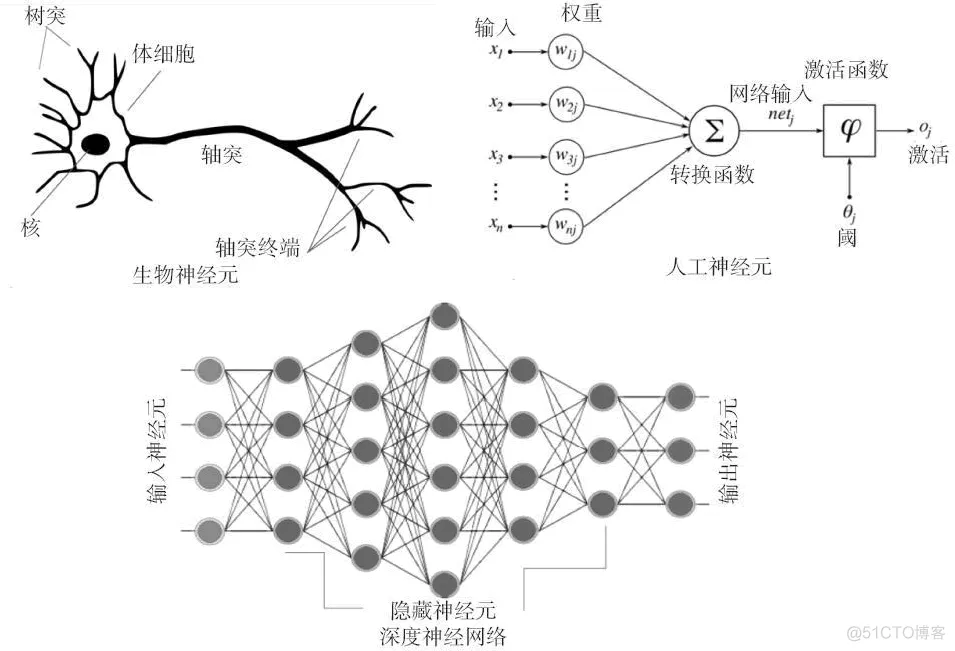
图 1 生物神经网络和人工神经网络的相似性
根据 Hinton 等人的定义,深度学习
( https://www.cs.toronto.edu/~hinton/absps/NatureDeepReview.pdf)是由多个处理层(隐藏层)组成的计算模型。层数的增加会导致学习时间的增加。由于数据量庞大,学习时间进一步增加,现今的 CNN 或生成对抗网络(GAN)的规范也是如此。
因此,为了实际实现 DNN,需要高计算能力。NVDIA 公司 GPU 的问世使其变得可行,随后 Google 的 TensorFlow 使得实现复杂的 DNN 结构成为可能,而不需要深入复杂的数学细节, 大数据集的可用性为 DNN 提供了必要的数据来源。
TensorFlow 成为最受欢迎的深度学习库,原因如下:
DNN 依赖于大量的数据。可以收集或生成数据,也可以使用可用的标准数据集。TensorFlow 支持三种主要的读取数据的方法,可以在不同的数据集中使用;本教程中用来训练建立模型的一些数据集介绍如下:
在 TensorFlow 中可以通过三种方式读取数据:
本文使用这三种方式来读取数据。
接下来,将依次学习每种数据读取方式。
在这种情况下,运行每个步骤时都会使用 run() 或 eval() 函数调用中的 feed_dict 参数来提供数据。这是在占位符的帮助下完成的,这个方法允许传递 Numpy 数组数据。可以使用 TensorFlow 的以下代码:
这里,x 和 y 是占位符;使用它们,在 feed_dict 的帮助下传递包含 X 值的数组和包含 Y 值的数组。
当数据集非常大时,使用此方法可以确保不是所有数据都立即占用内存(例如 60 GB的 YouTube-8m 数据集)。从文件读取的过程可以通过以下步骤完成:
files=tf.train.match_filenames_once('*.JPG') 函数创建。
这个函数还提供了一个选项来排列和设置批次的最大数量。整个文件名列表被添加到每个批次的队列中。如果选择了 shuffle=True,则在每个批次中都要重新排列文件名。

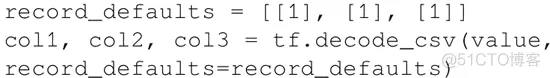
当数据集很小时可以使用,可以在内存中完全加载。因此,可以将数据存储在常量或变量中。在使用变量时,需要将可训练标志设置为 False,以便训练时数据不会改变。预加载数据为 TensorFlow 常量时: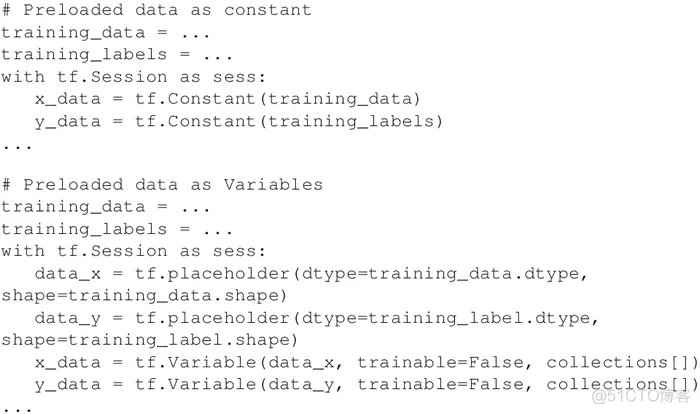
一般来说,数据被分为三部分:训练数据、验证数据和测试数据。
建立描述网络结构的计算图。它涉及指定信息从一组神经元到另一组神经元的超参数、变量和占位符序列以及损失/错误函数。
在 DNN 中的学习通常基于梯度下降算法(后续章节将详细讨论),其目的是要找到训练变量(权重/偏置),将损失/错误函数最小化。这是通过初始化变量并使用 run() 来实现的:
评估模型
一旦网络被训练,通过 predict() 函数使用验证数据和测试数据来评估网络。这可以评价模型是否适合相应数据集,可以避免过拟合或欠拟合的问题。一旦模型取得让人满意的精度,就可以部署在生产环境中了。
在 TensorFlow 1.3 中,增加了一个名为 TensorFlow Estimator 的新功能。 TensorFlow Estimator 使创建神经网络模型的任务变得更加容易,它是一个封装了训练、评估、预测和服务过程的更高层次的API。它提供了使用预先制作的估算器的选项,或者可以编写自己的定制估算器。通过预先制定的估算器,不再需要担心构建计算或创建会话,它会处理所有这些。
目前 TensorFlow Estimator 有 6 个预先制定的估算器。使用 TensorFlow 预制的 Estimator 的另一个优点是,它本身也可以在 TensorBoard 上创建可视化的摘要。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















