















































软件

产品


如果我们用C++编写程序只能应用在单个CPU核心上,当需要并行运行在多个GPU上时,我们需要从头开始重新编写程序。但是Tensorflow并非如此。因其具有符号性,Tensorflow可以隐藏所有这些复杂性,可轻松地将程序扩展到多个CPU和GPU。
例如在CPU上对两个向量相加示例。
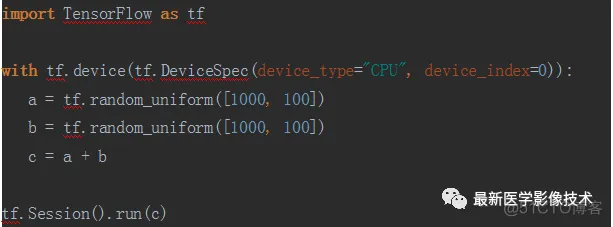
同样也可以在GPU上完成。
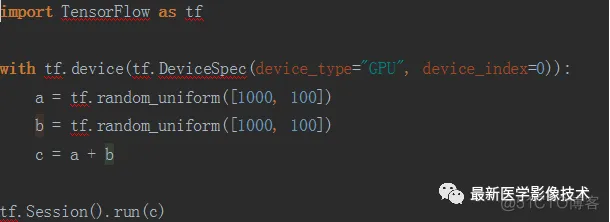
但是如果我们有两块GPU并且想要同时使用它们,该怎么办呢?答案就是:将数据进行等份拆分,并使用单独GPU来处理每一份拆分数据。
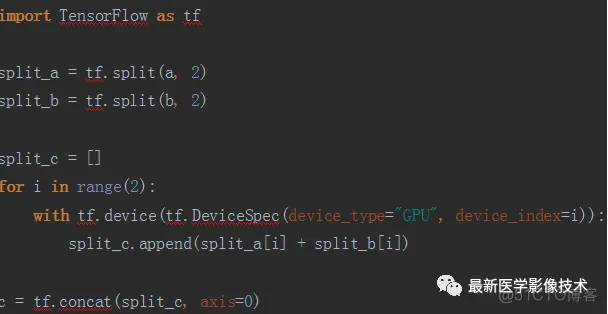
让我们以更一般的形式重写它。
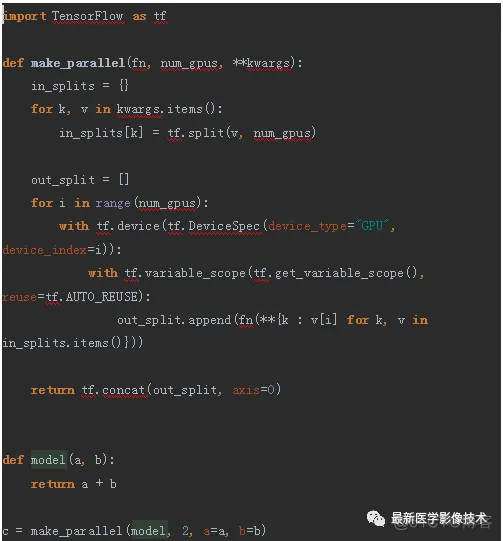
make_parallel函数是将任何一组张量作为输入的函数来替换模型,并在输入和输出均为批处理的情况下返回张量。还添加了一个变量作用域并将其重用设置为true。这确保使用相同的变量来处理两个分支。
我们来看一个更实际的例子。我们想要在多个GPU上训练神经网络,在训练期间,我们不仅需要计算正向传播,还需要计算反向传播(梯度),但是我们如何并行梯度计算呢?事实证明,这很容易,我们对每个GPU上算出的梯度求平均。具体代码如下。
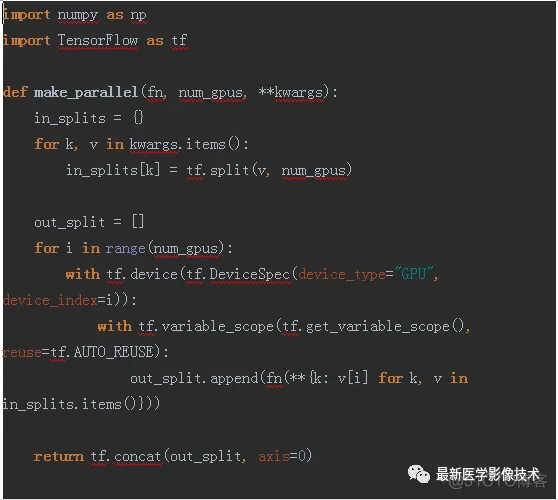
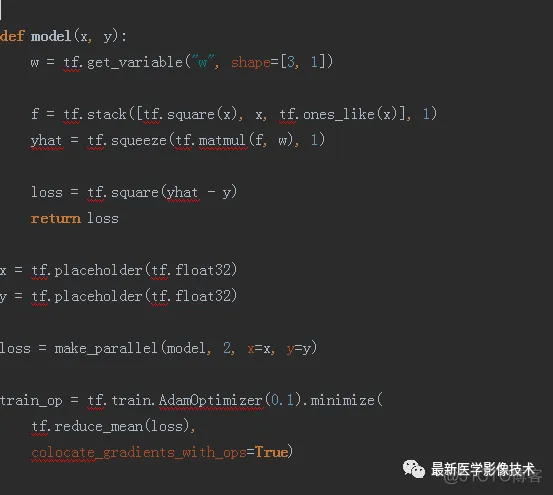

上面就是用2块GPU并行训练来拟合一元二次函数。注意:当用多块GPU时,模型的权重参数是被每个GPU同时共享的,所以在定义的时候我们需要使用tf.get_variable(),它和其他定义方式区别,我在之前文章里有讲解过,在这里我就不多说了。大家自己亲手试试吧。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















