















































软件

产品



PyTorch或TensorFlow在训练和运行Tranformer模型时哪个更有效呢?
近日,Huggingface(AI初创企业)的团队成员通过一篇发表在Medium上的博文告诉我们:两者差不多!
Facebook 的首席Ai科学家Yan Lecun大神在社交媒体上对此结果进行了转发点赞。
自TensorFlow发布实施以来,Huggingface团队就致力于模型的产品化,并使它们在TPU上可用,从而逐步提高性能。
这篇文章比较了模型在几种环境下的性能,研究人员在PyTorch(1.3.0)和TensorFlow(2.0)的CPU和GPU上比较它们的推理性能。
以下是博文具体内容:
测试结果
具体结果显示在此下面的Google Spreadsheet中,可点击查看。
https://docs.google.com/spreadsheets/d/1sryqufw2D0XlUH4sq3e9Wnxu5EAQkaohzrJbd5HdQ_w/edit#gid=0
下表中显示了平均结果。结果将在讨论部分中详细介绍。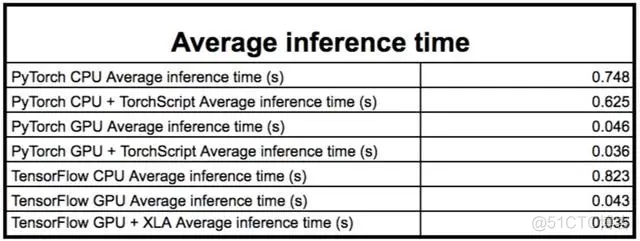
平均推理时间
电子表格中的N/A项表示内存不足错误或不适当的序列长度。Transformer-XL没有TorchScript结果,因为它目前不能被TorchScript序列化。
在大多数情况下,TensorFlow和PyTorch模型在GPU和CPU上都能获得非常相似的结果。
下面是关于结果的简短讨论,既可以作为PyTorch和TensorFlow之间的比较,也可以作为模型之间的比较。
推理时间测量
在将模型投入生产时,推理时间是一个重要的度量指标。为了评估我们的模型的推理时间,我们将它们与不同的批量大小和不同的序列长度进行比较。我们将合理的批大小[1、2、4、8]与序列长度[8、64、128、256、512、1024]进行比较。批处理大小仍然很小,因为我们只考虑推理设置。BERT和其他类似的模型最大序列长度为512或256(对于CTRL),因此不会测量最后的序列长度。
我们在两种不同的环境中测试结果:
实验详情和最佳实践
为了使性能最大化,需要进行进一步的优化:
讨论
PyTorch和TensorFlow
在大多数情况下,这两个库都能获得相似的结果,与PyTorch相比,TensorFlow在CPU上通常要慢一些,但在GPU上要快一些:
这些结果通过平均结果来比较所有模型的推断时间。因此,输入的大小越大,对最终结果的影响就越大。当输入大小过大时,PyTorch将耗尽内存;当求平均值时,这些结果将从所有度量中删除,因为这样会使结果偏向PyTorch。
PyTorch模型比TensorFlow模型更早耗尽内存:除了Distilled模型外,除了Distilled模型之外,当输入大小达到8的批处理大小和1024的序列长度时,PyTorch就会耗尽内存。
TorchScript
TorchScript是PyTorch创建可序列化模型的方法,该模型可以在不同的运行时运行,而无需Python依赖项,例如C ++环境。我们的测试是通过在Python中跟踪模型并在同一环境中重新使用该跟踪模型来完成的。我们通过预先执行前向遍历来确保在测量其推理之前跟踪模型。
免责声明:虽然在Python环境中,创建TorchScript似乎并不是为了加速,但是我们的结果表明,使用TorchScript跟踪模型可以产生性能改进。
TorchScript似乎非常依赖于模型和输入大小(批量大小*序列长度);例如,使用TorchScript可以在XLNet上产生永久的性能提升,而在XLM上使用它可能会有问题,因为在XLM上,它可以在较小的输入大小下提高性能,但在较大的输入大小下降低性能。
平均而言,使用TorchScript跟踪模型的推理要比使用相同的PyTorch非跟踪模型的推理快20%。
XLA
XLA是可以加速TensorFlow模型的线性代数编译器。我们仅在基于TensorFlow的自动聚类功能的GPU上使用它,该功能可编译一些模型的子图。
结果是提高了速度和内存使用率:启用XLA后,大多数内部基准测试的运行速度提高了约1.15倍。
启用XLA后,我们所有模型的性能都会提高。在某些极端情况下,我们的推理时间减少了70%,特别是在较小的输入大小下。
模型及其简化版本
Distilled模型在该测试中表现出色,因为它非常易于基准测试。这两种工程模型(DistilBERT和DistilGPT-2)与教师模型相比,其推理时间减少了一半。
下一步做什么?
对模型进行基准测试只是我们提高性能之路的第一步。我们认为,在比较模型的当前状态时,尤其是在查看PyTorch和TensorFlow之间的差异时,这篇介绍性文章可能会对您有所帮助。当我们深入研究的生产方面时Transformers,势必会进行面向性能的改进。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















