















































软件

产品


主要内容
(一)有限元分析介绍
有限元分析(FEA)借助高性能计算机工具,用“数值近似”和“离散化”方法对真实物理系统(几何和载荷工况)进行模拟,如求解结构、热传导、电磁场、流体力学等连续性问题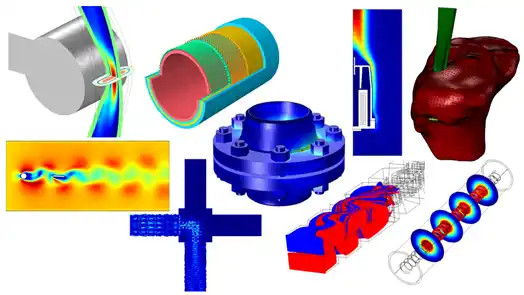
有限元法在工程设计和科研领域得到了广泛的应用,已经成为解决复杂工程分析计算问题的有效途径,从汽车到航天飞机几乎所有的设计制造都已离不开有限元分析计算,其在机械制造、材料加工、航空航天、汽车、土木建筑、电子电器、国防军工、船舶、铁道、石化、能源和科学研究等各个领域的应用普及,已使设计水平发生了质的飞跃。
主要仿真计算专业领域
瞬态结构仿真、静态仿真计算、流体仿真计算(CFD) 、电磁仿真计算(EM)、多物理场仿真仿真、热分析、声波仿真计算等
(二)有限元仿真计算特点分析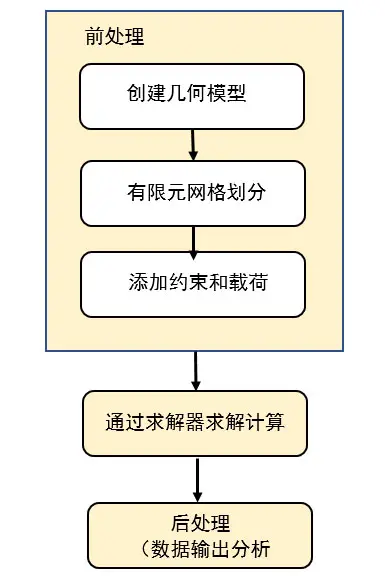
2.1 有限元分析各个环节计算过程分析
第一阶段 前后处理器计算过程分析
有限元前处理器是从几何模型形成物理模型的物理建模(几何建模)、由物理模型形成数学模型(网格划分)的数学建模两个过程,
常见有限元分析前处理软件:
ANSYS SpaceClaim,Meshing,ICEM CFD
Altair HyperMesh
MSC Patran
ANSA
Abaqus /CAE
Siemens Femap
一般来说,CAE分析工程师大部分时间都花费在了有限元模型的建立和修改上,真正的分析求解时间也消耗在了工作站或集群上,所以一个适合自己应用功能强大有限元前处理软件和一部高性能建模工作站是非常必要的。
常见问题:
1) 复杂、大型三维模型在读取和编辑过程,模型卡顿
2) 因精度过高,网格划分处理时间过长
造成上述问题的原因主要在三个方面:
1) 模型自身问题,精度太高,计算量过大,计算机无法承受
2) 前处理软件自身算法问题,网格划分软件的处理模式,计算不过来
3) 工作站硬件配置不足或配置不合理,计算性能不够
建模计算特点
硬件因素更关键,建模过程是人机交互模式下,对模型移动、缩放、删减等操作,为了保证流畅,每秒生成24帧画面,这样模型移动流畅,图形的几何顶点数据的计算,都是由CPU计算承担的,多核在这个过程不重要,主要靠单核,图卡任务得到图形的几何顶点数据生成图形,因此要让复杂模型流畅,显卡任务很轻松,只有提升CPU频率解决
网格划分计算特点
模型建立好后,要对三维模型的网格空间离散化过程,就是网格划分,通常网格划分密度越高,求解的结果越接近真实解,精度提高,网格划分计算量随之增大,常规工作站计算性能可能不够,因此对于碰撞、冲击、爆炸、波传播仿真分析来说,在计算效率、内存容量、精确度这三个方面要有所权衡,在满足求解精度的条件下,尽量使得计算量不要太大、存储空间小,另外不同的网格划分软件算法差异,网格生成数据规模有所不同,网格划分过程大部分软件是单核计算模式,个别软件是有限多核并行模式(如 Ansys Meshing),当然工作站硬件更重要,性能一定要最大化
第二阶段 求解计算特点与硬件配置分析
需要根据求解类型(运动学/动力学、静平衡、特征值分析等)选择相应的求解器进行数值运算和求解。求解问题归类:
2.1结构力学(动态类)仿真求解计算分析
求解问题 对碰撞、爆炸、冲击等仿真分析
主要软件:ANSYS LS-DYNA,ANSYS AUTODYN, ABAQUS/Explicit ,MSC Dytran,Altair RADIOSS,
主要算法 有限元法为主(中心差分法),显式计算模式,无需迭代
硬件特点:CPU多核并行度高,内存相对小,无硬盘io要求
2.2结构力学(静态类)仿真求解计算分析
求解问题 对应力、强度、疲劳、耐久仿真分析
主要软件:ABQAQUS /Standard, MSC MARC,Ansys Mechanicl,ADINA,MSC Fatigue
主要算法 有限元法为主(Newton-Raphson法),隐式计算模式,迭代密集
硬件配置特点:CPU多核并行度较高,内存相对大,硬盘io要求高
2.3流体力学仿真求解计算分析
求解问题 计算流体动力学仿真分析
主要软件:ANSYS Fluent,ANSYS CFX,西门子 STAR CCM+
主要算法 有限体积法为主(显式/隐式或混合模式计算模式)
硬件配置特点:CPU多核并行度高,部分支持GPU加速,内存相对小,无硬盘io要求
2.4多物理场耦合仿真计算分析
求解问题 结构、流体、热等耦合仿真分析
主要软件:Comsol Multiphysics ,ANSYS Multiphysics
主要算法 有限元法分析、有限体积法、边界元法和粒子追踪方法等(混合模式)
硬件配置特点:CPU多核并行度高,内存容量大,硬盘io一般,无GPU加速
2.5电磁仿真仿真计算特点与硬件配置分析
求解问题 电磁场及耦合仿真分析
主要算法 有限元法,时域与频域全波求解(MoM、FDTD、FEM 和 MLFMM)等
主要软件:ANSYS HFSS ,Maxwell,Feko,CST,
硬件配置特点:CPU多核并行度高,GPU加速显著,内存容量相对大,硬盘io一般
3)后处理计算特点
后处理模块可将计算结果以彩色等值线显示、梯度显示、矢量显示、粒子流迹显示、立体切片显示、透明及半透明显示(可看到结构内部)等图形方式显示出来,也可将计算结果以图表、曲线形式显示或输出
图形生成:基于OpenGL图形接口
软件:与前处理软件一体,见不同CAE软件商家
(三) 有限元建模与求解计算工作站硬件配置
3.1 仿真计算硬件配置归纳
1)有限元分析建模和求解、后处理
| NO | 计算环节 | 解释 | 计算特点 |
| 1 | 前处理 | 几何模型的建立 | 单核计算模式 |
| 网格生成 | 单核或有限多核计算模式 | ||
| 2 | 求解 | 结构、流体等问题求解 | 多核计算模式 |
| 3 | 后处理 | 计算结果输出,分析 | 单核计算模式 |
2)工作站单核计算与几何建模规模参考
| NO | 运行核数 | CPU频率 (单位:GHz) | 单核浮点速度 (单位:亿次/秒) | 网格规模估算 (单位:万) | 备注 |
| 1 | 1 | 2.0 | 320 | 6000 | 单核模式 |
| 2 | 1 | 2.2 | 352 | 6600 | |
| 3 | 1 | 2.4 | 384 | 7200 | |
| 4 | 1 | 2.6 | 416 | 7800 | |
| 5 | 1 | 2.8 | 448 | 8400 | |
| 6 | 1 | 3.0 | 480 | 9000 | |
| 7 | 1 | 3.2 | 512 | 9600 | |
| 8 | 1 | 3.3 | 528 | 9900 | |
| 9 | 1 | 3.5 | 560 | 10500 | |
| 10 | 1 | 3.6 | 576 | 10800 | |
| 11 | 1 | 3.8 | 608 | 11400 | |
| 12 | 1 | 4.0 | 640 | 12000 | |
| 13 | 1 | 4.3 | 688 | 12900 | |
| 14 | 1 | 4.6 | 736 | 13800 | |
| 15 | 1 | 4.8 | 768 | 14400 | |
| 16 | 4 | 4.8 | 3072 | 23040 | 多核模式 |
| 17 | 6 | 4.4 | 4224 | 23760 | |
| 18 | 8 | 4.3 | 5504 | 30960 |
3)CAE仿真计算规模与硬件配置参考
| NO | 网格节点 规模 (单位:万) | 自由度 规模测算(单位:万) | 动态结构 /流体仿真类 | 静态结构 /多物理场 耦合/电磁仿真类 | 工作站CPU最低核数测算 | GPU 测算 |
| 占用内存容量测算 (单位:GB) | ||||||
| 1 | 100 | 600 | 2 | 4 | 4 | 可算 |
| 2 | 200 | 1200 | 4 | 8 | 4 | 可算 |
| 3 | 400 | 2400 | 8 | 16 | 4 | 可算 |
| 4 | 800 | 4800 | 16 | 32 | 6 | 可算 |
| 5 | 1600 | 9600 | 32 | 64 | 8 | 困难 |
| 6 | 3200 | 19200 | 64 | 128 | 16 | 不可算 |
| 7 | 6400 | 38400 | 128 | 256 | 32 | 不可算 |
| 8 | 12800 | 76800 | 256 | 512 | 64 | 不可算 |
备注:(1)自由度是以六自由度网格粗算 (2)GPU以Nvidia双精度计算卡为主
3.2 与有限元仿真计算相关工作站机型介绍
1)用于前后处理机型

硬件配置特点:
CPU 4核*5.2GHz,6核5.0GHz,8核4.8GHz…
图卡:超高端图卡
系统盘:PCIE-SSD架构
是常规工作站所不具备的,
主要用途:满足大型复杂三维建模和网格划分
2)用于中大规模仿真计算机型

硬件配置特点:
CPU 双Xeon Scahlabe 处理器(最大56核,自动超频加速)
内存 最大1TB
图卡 双GPU超算,
硬盘:PCIe-SSD+8个盘位并行读写(限EX620)
比同类架构工作站,配置更强大,速度更快
主要定位 : 显式计算为主(H610),显式隐式计算通吃(EX620)
3)超大规模仿真计算机

硬件配置特点:
CPU 四颗Xeon E7v4(最大96核,自动超频加速)
内存 最大2TB
图卡 双GPU超算,
硬盘:PCIe-SSD+16个盘位并行读写
目前市场上所有图形工作站产品中,拥有最强大计算架构的计算机
主要用途
主要定位 :所有应用类的超大规模的CAE工程仿真计算,显式、隐式算法通吃
3.3 有限元分析仿真工作站硬件配置推荐
ANSYS有限元分析多核并行计算碰到很多问题:
情况1 机器核数不断增加,但求解速度不理想
情况2 机器越贵性能并不高
情况3 机器核数增加,求解时间反倒下降
问题分析:
首先 不同算法有不同的计算特点,另外整个求解过程,数据预处理与并行求解交叉推进,CPU很多计算过程不是全部100%的运行,
其次, 传统工作站通常是 (1)核数少频率高、 (2)核多频率低、 (3)核数严重不足、(4)核数太多,(5)仅有CPU计算架构,没有GPU超算配置,
上述机器和算法计算要求,严重不匹配,这样性能上不去,求解效率很低,怎么办,是否有那种理想的配置架构?
本文给出高频+多核的理想架构,完美解决上述问题
1) 基于结构仿真计算(隐式算法)工作站配置方案
隐式算法计算特点:
对CPU核数线性加速比有限,内存容量和硬盘io 要求高
完美理想的硬件配置原则:
1)高速计算架构:CPU具备高频(自动网格划分)+多核(并行求解),
2)内存:CPU核数:内存容量 1:8,
3)高IO读写
推荐配置:(此处省略配置表格)
2) 基于流体仿真计算(显式算法)工作站配置方案
显式算法计算特征:
CPU核数线性加速理想,核数越多越好,对内存容量、硬盘io要求不高,整个计算过程是同时单核与多核交替进行
完美理想的硬件配置原则:
1)高速计算架构:CPU具备高频(自动网格划分)+多核(并行求解),
2)内存:CPU核数:内存容量 1:4,
推荐配置:(此处省略配置表格)
3)基于电磁仿真、多物理场耦合工作站配置方案
该类型求解计算特征:
CPU核数线性加速理想,核数越多越好,对内存容量要求高,整个计算过程是同时单核与多核交替进行
完美理想的硬件配置原则:
1)高速计算架构:CPU具备高频(自动网格划分)+多核(并行求解)
2)内存:CPU核数:内存容量 1:8,
推荐配置:(此处省略配置表格)
以上为公司技术专家多次测试后作出的技术总结,不完整和纰漏之处也请技术邻的专家指正。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















