















































软件

产品


如果大家使用TOSCA-GUI(图形用户界面)进行优化分析,那么整个优化的流程基本可以认为是多个命令关键词组合的结果。了解那些经常使用的命令关键词,可以使大家使用TOSCA进行优化分析时更加得心应手。
每次进行TOSCA优化之前,我们都要读取一个有限元的结果文件,此时就需要-FEM_INPUT这个命令关键词。
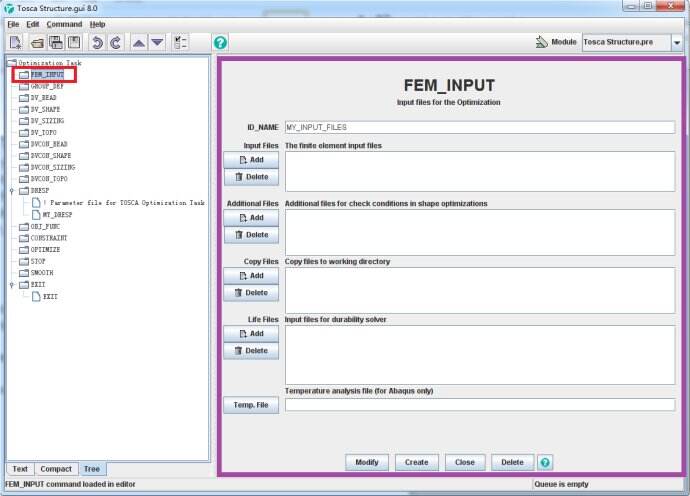
上图中,左侧的目录中是FEM_INPUT的位置,右侧是FEM_INPUT的具体填写内容。
使用GUI界面显示的只是部分功能,如果需要扩展功能,我们可以通过读取相应优化文件*.par的文本形式,并加以修改得到。
下面我们来看一下FEM_INPUT的填写内容。
首先,ID_NAME: 这个很好理解,就是需要填写有限元文件的名字,其文本形式为:
ID_NAME=
接下来,Input Files:就是要添加有限元文件的路径。如果,我们读入的有限元文件叫做my_model.inp,则记录为文本形式:
FILE = my_model.inp
第三部分,Additional Files:在此项中,我们可以添加的文件不是参与优化计算的,其内容一般为定义的相邻约束条件。 ADD_FILE可以重复数次。
例如:
FEM_INPUT
ID_NAME = my_finite_element_models
FILE = my_fe_model.bdf
ADD_FILE = restriction_elements_left.bdf
ADD_FILE = restriction_elements_right.bdf
END_
第四部分,Copy Files: 在此处添加的文件在优化开始阶段被复制。
第五部分,Life Files: 此处添加的文件只支持ONF 601-block格式的疲劳计算,该文件不会在优化过程中被修改,同时也可多次重复。
第六部分,Temp Files:在TOSCA优化过程中也可以提供温度预分析,但是此功能现阶段的版本只支持ABAQUS求解器。
下面是一个例子:如果我们要进行三个Abaqus的job的计算,其中第一个是一个预加载步,它是需要在其他两个job中使用。此外,第一个job是运行24个CPU,其他两个job调用12个CPU。最终的文本形式如下所示:
FEM_INPUT
ID_NAME = model
FILE = input1.inp
FILE_ADD_CALL = cpus=24
FILE = input2.inp
FILE_ADD_CALL = cpus=12 globalmodel=input1.odb
FILE = input3.inp
FILE_ADD_CALL = cpus=12 globalmodel=input1.odb
END_
掌握文件输入的结构,可以使我们更好地进行优化计算,也使得结果更加真实可靠。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















