软件

产品


"本文主要对fluent-bit 1.3版本指令做详细介绍
1、回顾
随着集群规模不断扩大,日志收集问题将一直萦绕在我们耳边,前段时间我用四篇文章安利了使用fluentd及fluent-bit好处,具体可以参考如下链接:
下面我就直接介绍fluent-bit整体收集架构和插件,如果对整体有不理解的部分,可以参考如上链接。
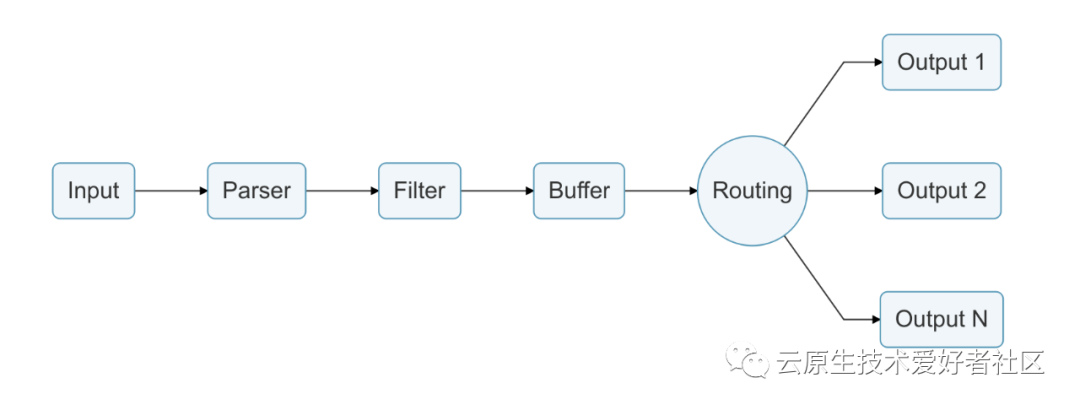
2、插件介绍
整体功能流程如下图所示:
| 插件 | 描述 |
| Input | 数据入口点,通过输入插件实现,此接口允许收集和接收数据,比如日志文件、TCP上报数据等。 |
| Parser | Parser能够把从input接口获取的非结构化数据进行格式化操作,Parser是可选的,具体取决于Input输入插件。 |
| Filter | Filter是过滤器插件,它允许修改input插件提取的数据。 |
| Buffer | 默认情况下,Buffer把Input插件的数据缓存在内存当中,直到路由并传递到output接口为止。 |
| Routing | 用于标记Input接口获取的数据,根据规则匹配把数据路由到什么位置。 |
| OutPut | OutPut用于定义数据目的地和目的地输出插件,注意:借助于Routing插件可以把数据输出到多个目的地。 |
3、fluent-bit插件详细介绍
3.0、Input
fluent-bit提供了各种各样的日志插件来收集不同来源的日志文件,比如可以从日志文件收集、操作系统收集一些度量数据。当Input插件被加载以后,fluent-bit会在内部创建一个实例,每个实例都有自己独立的配置,这些配置我们通常称作它的属性。
Input定义了输入源信息,如下所示Input相关配置信息,注意每个Input插件都可以定义自己的配置键。
| key | value |
| Name | Input输入标签名称 |
| Tag | Input插件产生记录标签名称 |
Name是必填项,它使Fluent-bit知道应该加载那个输入插件,除输入和转发插件外,其它插件Name都是必填项。使用示例如下所示:
[INPUT] Name cpu Tag my_cpu3.1、Parser
实际情况下,原始字符串的使用是一件很痛苦的事情,通常情况下,我们期望在收集到输入数据后立刻转换为结构化的数据,默认可以处理Apche、Nginx、Docker等日志。
通过以下实例(Apache HTTP服务器)可以看出非结构化的数据转换为结构化数据的过程:
192.168.2.20 - - [28/Jul/2006:10:27:10 -0300] "GET /cgi-bin/try/ HTTP/1.0" 200 3395
上面的日志行是没有经过任何处理的原始日志,理想情况下我们可以把它转换为日后可以轻松处理的结构化数据,如果使用正确的配置,我们可以把日志转换为如下格式:
{ "host": "192.168.2.20", "user": "-", "method": "GET", "path": "/cgi-bin/try/", "code": "200", "size": "3395", "referer": "", "agent": "" }解析器是完全可以配置的,并且可以由每个输入插件独立且可选的方式进行处理。
具体配置使用示例,如下所示:
[PARSER] Name docker Format json Time_Key time Time_Format %Y-%m-%dT%H:%M:%S.%L Time_Keep On [PARSER] Name syslog-rfc5424 Format regex Regex ^\<(?<pri>[0-9]{1,5})\>1 (?<time>[^ ]+) (?<host>[^ ]+) (?<ident>[^ ]+) (?<pid>[-0-9]+) (?<msgid>[^ ]+) (?<extradata>(\[(.*)\]|-)) (?<message>.+)$ Time_Key time Time_Format %Y-%m-%dT%H:%M:%S.%L Time_Keep On Types pid:integer3.2、Filter
生产环境中,我们要完全控制我们需要收集的数据,Filter是一个很重要的特性,它能够保证数据在没有到达目的地之前对其进行修改。Filter是通过插件进行实现的,因此每个可用的标记都可以用来匹配,过滤或丰富特定元数据的日志。
Filter和Input非常类似,它在实例上下文中运行,有着自己独立的配置,如下所示是Filter相关配置信息:
| key | desc |
| Name | 过滤器名称 |
| Match | 与传入记录标签匹配的模式,它区分大小写,并可以用 * 作为通配符。 |
| Match_Regex | 与传入记录标签匹配的正则表达式,如果要使用完整的正则表达式语法,请使用此选项。 |
Name是必填项,它使fluent-bit知道应该加载那个插件,Match和Match_Regex是匹配模式插件,如果两者同时定义,以Match_Regex优先。使用示例如下所示:
[FILTER] Name stdout Match *3.3、Buffer
Buffer在fluent-bit中是一个可供选择的缓冲机制,该机制能够充当数据备份系统,以避免系统故障导致的数据丢失。
fluent-bit最终目标是收集、解析、过滤、最终把日志发到中心位置,在此过程中存在多个阶段,而关键的功能之一就是缓冲的能力,即把处理后的数据存放在临时位置,随时可以发送到最终位置。默认情况下,fluent-bit在处理数据时,使用内存进行存储记录和临时位置,但是在理想情况下,是在文件系统中提供持久化存储机制,以保证数据的聚合和安全功能。
从fluent-bit 1.0开始,fluent-bit提供了新的存储层,该存储层可以是内存也可以是文件系统,可以在输入插件中进行配置启用。
注意:缓存的数据不在是默认的日志数据格式,而是fluent-bit内部二进制表示形式。
Buffer有两个区域需要配置,如下:
可以在Service Section配置一个全局存储变量,在Input Section定义使用什么机制。
Service相关的配置信息如下所示:
| Key | Description | Default |
| storage.path | 在文件系统中配置一个可选位置用于存储数据流和数据块,如果未设置此参数,那么只能使用内存作为缓存。 | |
| storage.sync | 开启数据同步到文件存储系统,可以配置normal和full两种配置。 | 正常 |
| storage.checksum | 从文件系统中读取或写入数据时启用完整性检查,存储层使用CRC32算法。 | 关闭 |
| storage.backlog.mem_limit | 如果设置了storage.path,fluent-bit会查找尚未分发出去的数据块,这些数据块称之为积压数据,此配置用来控制处理这些积压数据时占用系统内存大小。 | 5M |
Service部分示例如下:
[SERVICE] flush 1 log_Level info storage.path /var/log/flb-storage/ storage.sync normal storage.checksum off storage.backlog.mem_limit 5M如上所示配置了一个缓冲机制,缓冲区路径/var/log/flb-storage/,它将使用正常的同步模式,没有校验和,并且在处理积压数据时最大可以使用5M内存。
Input部分配置信息如下所示:
Input插件可以配置如下可选存储配置项,下表描述了可选的配置:
| Key | Description | Default |
| storage.type | 指定要使用的缓冲机制,内存或者文件系统 | 内存 |
如下所示配置了一个缓冲服务的功能,两个Input插件,第一个文件系统,第二个内存。
[SERVICE] flush 1 log_Level info storage.path /var/log/flb-storage/ storage.sync normal storage.checksum off storage.backlog.mem_limit 5M [INPUT] name cpu storage.type filesystem [INPUT] name mem storage.type memory3.4 、Routing
它是一项核心功能,可以通过过滤器把数据路由到一个或者多个目的地。
路由中有两个重要概念:
Tag:当数据由输入插件生成时,它会附带一个标签(大多数情况下是人为手动配置该标签),该标签是用户可读的指示器,有助于识别数据源。
Match:它在输出插件中指定,主要用于定义当前数据路由目的地。
参考以下示例,该示例旨在把CPU信息路由到ES数据仓库,内存信息传递到标准输出接口。
[INPUT] Name cpu Tag my_cpu [INPUT] Name mem Tag my_mem [OUTPUT] Name es Match my_cpu [OUTPUT] Name stdout Match my_mem路由会自动读取输入规则和输出匹配标签,如果一些数据输入标签和输出标签不匹配,那么该数据将被忽略。
路由具有足够的灵活性,以支持通配符的匹配模式。下面这个例子说明了两个数据源共同定义了一个目的地。
[INPUT] Name cpu Tag my_cpu [INPUT] Name mem Tag my_mem [OUTPUT] Name stdout Match my_*匹配规则设置成my_*,那么意味着,它将匹配所有以my_开头的数据。
3.5、OUTPUT
它用于定义数据的输出目的地。目的地可以是远程服务、本地文件系统、或其它可用的标准接口。OutPut有很多可用的输出插件实现。加载输出插件后,将创建一个独立的实例,每个实例都有自己独立的配置。OUTPUT支持以下属性配置:
| Key | Desc |
| Name | 输出插件的名称 |
| Match | 与传入记录标签匹配的模式,它区分大小写,并可以用 * 作为通配符。 |
| Match_Regex | 与传入记录标签匹配的正则表达式,如果要使用完整的正则表达式语法,请使用此选项。 |
如下所示是OUTPUT的使用示例:
[OUTPUT] Name stdout Match my*cpu如下所示是收集CPU指标示例:
[SERVICE] Flush 5 Daemon off Log_Level debug [INPUT] Name cpu Tag my_cpu [OUTPUT] Name stdout Match my*cpu4、Service
运行于整个数据链的输入和输出;比如可以配置为fluent-bit是否为守护进程、过滤日志记录、刷新间隔等。
Service定义了服务的全局属性,通过下表可以说明当前版本可用的属性:
| 键值 | 描述 | 默认值 |
| Flush | 设置flush时间(以秒为单位)每次超时,fluent-bit都会把数据刷新到输出插件中。 | 5 |
| Daemon | 一个布尔值,用于设置fluent-bit是否为守护进程(后台运行),允许使用yes, no, on 和 off | 否 |
| Log_File | 可选日志文件的绝对路径 | |
| Log_Level | 设置日志记录的详细程度,允许使用error, warning, info, debug 和 trace. 注意只有WITH_TRACE启用的情况下trace模式才可用。 | |
| Parsers_File | Parsers配置路径,可使用多个Parsers_File路径 | |
| Plugins_File | 插件配置路径,可以配置外部插件 | |
| Streams_File | 流处理器配置文件路径 | |
| HTTP_Server | 启用内置Http服务器 | 否 |
| HTTP_Listen | 启用Http监听端口 | 0.0.0.0 |
| HTTP_Port | tcp端口 | 2020 |
| Coro_Stack_Size | 设置协程堆栈大小(以字节为单位)。该值应该大于允许系统页面大小,不要设置太小,否则协程可能会超出堆栈缓冲区 | 24576 |
使用示例如下:
[SERVICE] Flush 5 Daemon off Log_Level debug5、总结
本文主要详细介绍了fluent-bit从输入到输出过程中使用的插件。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020