















































软件

产品


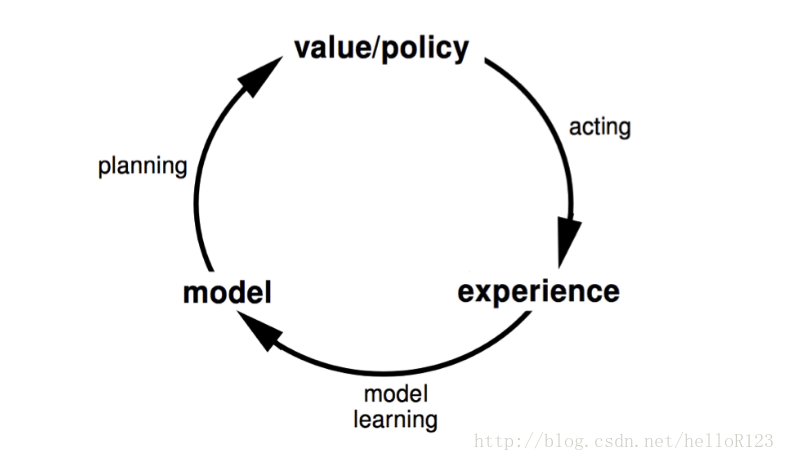
前面说的value-base方法(除了动态规划)也好,policy-base的方法也好,都是假设没有模型而直接与实际环境 交互 来学习的,我们把没有用到模型的方法叫做model-free方法,但并不是说value-base和policy-base方法都是model-free的方法,value-base和policy-base是根据方法学习策略的角度划分的,model-base和model-free是根据方法有没有关于model的学习来划分的,两者划分的角度不同,只不过前面在讲value-base和policy-base方法是都是假设没有模型来说的,所以它们也是model-free的方法,下面就讨论下各类型的方法。简要说明下,model-free方法是指没有用到模型,直接与实际环境交互来学习到最优策略;planning是指已经有了模型,然后怎样使用模型来得到最优的策略;model-base是指根据环境中的经验学习模型,然后用这个模型做planning;dyna在model-base的基础上再加上直接的model-free学习。
下面的很多内容都有蛮大一部分是自己对视频的理解和总结,优缺点后面的括号是对该点为什么存在的解释,可能有很多不对或不准确的地方,如果有不同的看法或者不赞同的意见欢迎指出~


forward search + samle相当于用model-free的方法解决一个部分MDP的问题,它所关注的是在当前状态下应该采取什么动作是最好的,而不是关注整个状态空间中应该采取什么 策略 是最优的。 

它们的过程 类 似于也是在部分MDP问题中采用策略迭代。
对于蒙特卡罗搜索 : 
先是估计一个随机策略的价值函数 (也就是simulation policy),注意的是不管其他状态这个价值函数是否准确,但当前状态上是一定准的,这个部分MDP关注的是当前状态,然后做一次策略提升,也就是greedy的操作选择最好的动作,可以想象新的策略对当前状态来说只是做了一次更新,所以在当前状态上就比simulation policy好一些,如果simulation policy不好的话,那么更新后的策略效果也不会很好因为只做了一次更新,如果simulation policy在当前状态上本来就比较好的话,那么更新后的策略在当前状态上也会更好。所以simulation policy的选择很重要。
对于蒙特卡罗树搜索 : 


它更像是蒙特卡罗搜索中做策略更新做多几次,selection相当于在做策略提升,而expansion,simulation 和backpropation则是在做策略估计。随着策略迭代的进行,树上的节点的值越来越趋向于当前策略的值函数。
感觉各种优缺点写的优点乱,可能把它们分解成各种机制好一些,顺便把之前的一些机制也总结下吧。
首先先有一些基本的 算法 :动态规划(DP),policy-gradient的公式(PG)
然后可以看成 :
MC = DP + sampling (+function approximation)
TD = DP +sampling + bootstrap (+function approximation)
MC-PG = PG + sampling
ActorCritic-PG = PG + sampling + bootstrap + function approximation
MCTS = forward search + sampling
使用哪一类的方法取决于具体的应用场景,要考虑几个因素:
1. 有没有真实的环境模型可用
2. 环境是否在不断变化的
3. 需不需要一边学一边做决策
4. 存不存在维数灾难问题
5. 计算耗时如何
6. 价值函数是否难得到
……
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















