I. 摘要
主要创新与贡献:
- 采用了当前最新的目标提案技术,提取landmark
- 使用神经网络表示landmark,用于匹配
- 网络不需要专门训练
- 具有视点鲁棒性,外观变化的鲁棒性
- 引入了具有挑战性的数据集(在viewpoint和apperarance方面)
II. 相关工作
- 地点识别:逐渐从早期的对于没有外观变化的场景识别变为具有真实变化的场景识别。
处理地点识别的方法逐渐从对图像序列的变化转化成将图片转化成不变的场景(如移除阴影),学习环境随时间是如何变化的,并且在图像空间中预测这些变化。 - 文中强调的一点是:现有的方法大多需要在特定的数据集上进行训练才能取得较好的结果,从而凸出本文的无需训练的创新点。
- 通常来说,用ConvNet神经网络提取整幅图像的特征作为全局特征,在环境改变方面(如光照,季节)是优于现有的方法的,但是它经历着对视点变化的敏感。所以受启发于[1]的算法,本文提出了一种基于landmark的表示图像特征的方法,是region-based的ConvNet的方法。
III. 提出的系统
此系统主要包括五个关键成分:
- 从当前图像提取landmark
- 计算提取出landmark的ConvNet特征
- 将特征映射到一个更低维的空间
- 计算当前图像与之前所有图像的相似度
- 计算最好的匹配
如下图示为整个系统的workflow
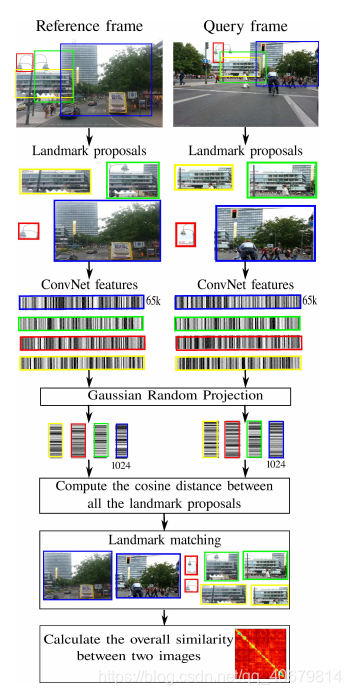
A. 自下而上的目标提案方法
- R-CNN[2]是这样一个系统的一个杰出的例子,该系统每幅图像提取大约2000个提案区域,并通过一个卷积网络分类器传递所有这些区域,这个分类器可以确定一个对象是否存在,以及它属于哪个已知的类。
- 为了提取Landmark我们应用了Edge Boxes[3], 边界框主要依赖于这样一种观察:一个边界框中全部包含的轮廓数表示包含一个对象的框的可能性。它通过比较每个边界框内的边的数量和通过边界框的边的数量来度量客观度分数
- 每张图片提取50或100个landmark
B. ConvNet 特征作为鲁棒的Landmark特征描述子
- 采用已经使用图像分类数据集训练好的AlexNet网络作为ConvNet,在作者之前的工作[4]中已经证实Conv3对于环境的改变更具不变性,所以这里也只利用前三层的AlexNet网络。
- landmark被调整为231×231×3像素的期望输入大小。(这里本人是保持疑惑的)
C. 为了降维进行随机Projections
- 当保持两点间pairwise欧式距离为一个固定倍数时,一系列高维空间中的点可以线性嵌入低维空间:
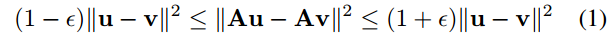
- 其中u,v是高维空间向量,A是从高维空间映射到低维空间的变化矩阵,这里采用的是Gaussian Random Projection
- 在我们的实验中,我们将64,896个原始维度投射到512、1024和4096个维度,并比较它们的相对性能
D. 图像匹配
- 提取完landmark后,再进行降维我们得到了固定长度的地标集合L(n),其中n是Landmark的数量,这时需要计算当前查询图片与之前图像的相似性。
- 第一步:利用NN搜索,计算query中一landmark L(i)和database一幅图像中任一landmark L(j)的余弦距离dij,找到L(i)匹配上的L(j)计算sij,其中wi,hi是query中landmark L(i)的宽度和高度(应该是输入网络之前的)
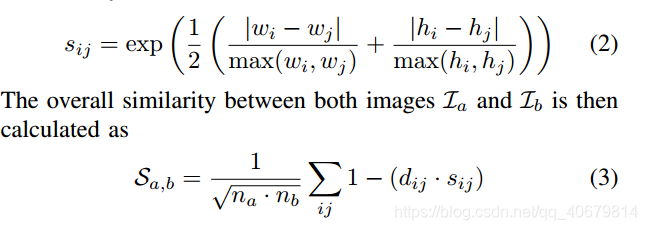
- 第二步: 计算整体图片之间的相似性,如公式(3)所示,n(a)是query image的landmark数,n(b)是数据库中一图像的landmark数,这里面包括没有匹配上的landmark数。
- 最后一步:形成相似矩阵,挑选最大相似度的对应图片作为匹配。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删















































 技术文档
技术文档
 热门文章
热门文章


 155-2731-8020
155-2731-8020




















 著作权
著作权





