首先是我读这篇论文的目的,我的研究方向是“基于面部表情的情感识别”,是偏向于计算机视觉的一个方向,这篇论文对深度面部表情识别(DFER)做了一个全面的介绍,包括数据集、DFER的基本流程、各个流程中使用的方法等,阅读这篇文章可以对DFER的一些基本情况做一个初步的了解。这是一个笔记,后面会有精简的总结。
摘要
摘要部分主要介绍了三个问题:
- 深度神经网络被越来越多的用于FER系统的原因:
- 当前的FER系统专注的两个重要的问题:
- 这篇论文主要结构(介绍了相关的数据集以及在特定问题下的相关算法):
- 关键字:Facial Expressions Recognition, Facial expression datasets, Affect, Deep Learning, Survey
一、引言
- 面部表情是人类表达自己情感状态、意图打算的最有效、最自然、最普遍的信号之一。
- 面部表情识别的应用场景:社交机器人(Sociable robotics)、医学治疗(Medical treatment)、驾驶员疲劳监测(Driver fatigue surveillance)以及其他人机交互场景
- 基本面部表情模型(6+1种表情): 早在20世纪初,Ekman and Friesen定义了六种的基本表情,并表示这六种基本表情在人类的各个种族中间具有普遍性。这六种基本表情分别是:生气(anger)、厌恶(disgust)、恐惧(fear)、幸福(happiness)、悲伤(sadness)、惊喜(surprise)。随后,鄙视(contempt)被加入基本表情之中。 但在最近的神经学和心理学研究中称,六种基本表情模型并不是普遍的,而是和具体的文化相关的。 虽然基于基本表情限制了我们对于表情复杂性和细微性的表示能力,也出现了其他的表情模型(the Facial Action Coding System (FACS)、使用影响维度的连续模型等考虑表示更广泛的情绪特征),但由于表情分类模型开拓性的调查以及对面部表情的直接和直观的定义,这种模型在FER中仍然比较受欢迎。
- FER系统根据特征表示方面的不同主要分为两种类型: 静态图像的FER(static image FER) 动态序列的FER(dynamic sequence FER)
- FER系统数据集和训练方法的描述: 2013年以前:传统的方法主要是手工特征或者浅层学习(如LBP(local binary patterns 局部二值模式)、LBP-Top(在三个正交平面上的LBP)、NMF(non-negative matrix factorization 非负矩阵分解)) 2013年以后:随着各种表情识别比赛(如FER2013、Emotion Recognition in the Wild (EmotiW))的举办,面部表情数据收集的越来越多、各种芯片的计算能力大幅增强,FER从实验室应用转向自然图像中的面部表情识别,深度学习系统也开始慢慢被应用到FER中。
- 深度学习应用在FER系统中时仍然存在问题: 深度神经网络的训练需要大量的数据,但现存的数据量不能满足深度神经网络的训练; 主体间的差异(如年龄、性别、种族、表情丰富程度等)的影响; 姿势变化、光照强度的变化等也会对训练造成影响;
- FER系统数据集以及方法变化
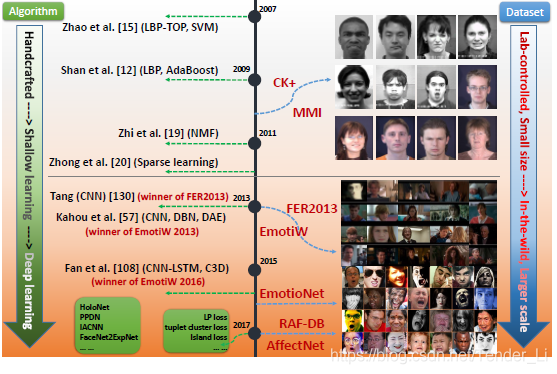
二、面部表情数据库(Facial Expression Databases)
使用足够多的数据进行深度神经网络的训练是非常重要的。
在这一部分,问斩给介绍了一些当前主流的面部表情数据库,现总结如下:
| 数据库 |
数据量 |
实验对象 |
采集环境 |
采集方式 |
表情分配 |
网址链接 |
备注 |
| CK+ |
593个视频序列 |
123个 |
实验室采集 |
摆拍&自然 |
6种基本表情和鄙视以及中性表情 |
http://www.consortium.ri.cmu.edu/ckagree/ |
|
| MMI |
326个视频序列(740 images and 2,900 videos) |
32个 |
实验室采集 |
摆拍 |
6种基本表情+中性表情 |
https://mmifacedb.eu/ |
|
| JAFFE |
213张图片 |
10个 |
实验室采集 |
摆拍 |
6种基本表情+中性表情 |
http://www.kasrl.org/jaffe.html(可下载) |
|
| TFD |
112234张图片 |
N/A |
实验室采集 |
摆拍 |
6种基本表情+中性表情 |
josh@mplab.ucsd.edu |
|
| FER2013(比赛) |
35,887张图片 |
N/A |
互联网采集 |
摆拍&自然 |
6种基本表情+中性表情 |
https://www.kaggle.com/c/challenges-in-representation-learning-facial-expression-recognition-challenge |
|
| AFEW 7.0(比赛) |
1809个视频序列 |
N/A |
电影采集 |
摆拍&自然 |
6种基本表情+中性表情 |
https://sites.google.com/site/emotiwchallenge/ |
|
| SFEW 2.0 |
1766张图片 |
N/A |
电影采集 |
摆拍&自然 |
6种基本表情+中性表情 |
https://cs.anu.edu.au/few/emotiw2015.html |
采集自AFEW数据集 |
| Multi-PIE |
755370张图片 |
337个 |
实验室采集 |
摆拍 |
厌恶、中性、尖叫、微笑、斜视、惊喜(disgust, neutral,scream, smile, squint and surprise) |
http://www.flintbox.com/public/project/4742/ |
|
| BU-3DFE |
2500张图片 |
100个 |
实验室采集 |
摆拍 |
6种基本表情+中性表情 |
http://www.cs.binghamton.edu/~lijun/Research/3DFE/3DFE_Analysis.html |
适用于3D面部表情分析 |
| Oulu-CASIA |
2880个图像序列 |
80个 |
实验室采集 |
摆拍 |
6种基本表情 |
http://www.cse.oulu.fi/CMV/Downloads/Oulu-CASIA |
|
| RaFD |
1608张图片 |
67个 |
实验室采集 |
摆拍 |
6种基本表情和鄙视以及中性表情 |
http://www.socsci.ru.nl:8180/RaFD2/RaFD |
|
| KDEF |
4900张图片 |
70个 |
实验室采集 |
摆拍 |
6种基本表情+中性表情 |
http://www.emotionlab.se/kdef/ |
|
| EmotioNet |
1,000,000张图片 |
N/A |
互联网采集 |
摆拍&自然 |
23 种基本表情或复合表情 |
http://cbcsl.ece.ohio-state.edu/dbform_emotionet.html |
规模较大 |
| RAF-DB |
29672张图片 |
N/A |
互联网采集 |
摆拍&自然 |
6种基本表情+中性表情+12种复合表情 |
http://www.whdeng.cn/RAF/model1.html |
|
| AffectNet |
450000张有标记的图片 |
N/A |
互联网采集 |
摆拍&自然 |
6种基本表情+中性表情 |
http://mohammadmahoor.com/databases-codes/ |
目前为止最大的提供两种表情模型标签的数据库 |
| ExpW |
91793张图片 |
N/A |
互联网采集 |
摆拍&自然 |
6种基本表情+中性表情 |
http://mmlab.ie.cuhk.edu.hk/projects/socialrelation/index.html |
|
每一个数据库都有其本身的特点,在选取训练数据的数据库时,需要注意所需数据的特性
三、面部表情识别的基本流程
这一部分,文章介绍了FER系统的基本流程:预处理->深度特征学习->深度特征分类
1. 预处理(Pre-processing)
由于与表情无关的因素(背景、光照、头部姿势等)会对DFER网络的训练产生影响,因此,在进行网络训练之前,需要对数据进行预处理,以尽可能消除无关因素的影响。包括面部对齐(Face aligned)、数据扩充(Data augmentation)和标准化(Normalize)。
(1)面部对齐
面部对齐是面部识别相关任务的触痛处理步骤,给出一系列的训练数据,第一步就需要去除无关的背景以及没有面部数据的区域。
- 面部对齐方法介绍:
(2)数据扩充
深度神经网络的训练需要使用大量的数据来确保训练模型的性能,而现存的数据库中数据相对有限,所以需要使用一些技术对数据库进行数据扩充。
(3)面部标准化
光照强度和头部姿势的变化可能会对图片特征造成重大影响,进而降低FER的性能。
2. 特征学习的深度网络
最近,深度学习已经成为一个热门的研究课题,并在各种应用中取得了最先进的性能
(1)卷积神经网络(CNN)–>基本结构
- CNN相对于多层感知机(MLP)在面部位置以及面部规模变化方面更具有鲁棒性。(文章[98]、[99])。
- 文章[100]使用CNN解决了面部表情识别中的主体独立性以及平移、旋转和比例不变性的问题。
- 卷积神经网络的组成: 由三种不同的层(layer)组成:卷积层、池化层、全连接层; 三个Layer的介绍: 卷积层(convolutional layer): 有一组可学习的过滤器,通过卷积整个输入图像,并产生各种特定类型的激活特征映射。 优点: 本地连通性 权值共享:在同一特征图中进行权值共享,极大地减少了需要学习的参数的数量; 物体位置的平移不变性 池化层(pooling layer) 在卷积层之后 作用:减少特征图的空间尺寸和网络的计算量 两种使用最多的池化方式: 平均池化(Average Pooling) 最大池化(Max Pooling) 全连接层(fully connected layer): 通常放在整个网络的最后 作用: 确保当前层的所有神经元都与前一层的激活神经元完全连接 将二维特征图转换为一维特征图,进行进一步的特征表示和分类。 熟知的几个卷积神经网络模型: 几个网络的结构: 其他比较出名的网络: R-CNN(region-based CNN)[103]: Faster R-CNN 3D CNN
(2)深度信任网络(Deep belief network----DBN)–>基本结构
- DBN由Hinton等人在[113]中提出,是一种学习提取训练数据深层层次表示的图形模型,传统的DBN是由一组受限玻尔兹曼机(RBMs)构建的,是由可见单元层和隐藏单元层组成的双层生成随机模型。
(3)深度自动编码器 (Deep autoencoder -----DAE)
- DAE首次提出是为了解决降维的有效编码问题的
- 与前面提到的经过训练可以预测目标值的网络相反,DAE通过最小化重构误差来优化其输入。
(4)递归神经网络(Recurrent neural network----RNN)
- RNN是一种捕获时间信息的连接主义模型,更适合于具有任意长度的顺序数据预测。除了以单一前馈方式训练深度神经网络外,RNN还包括跨越相邻时间步长并在所有步长上共享相同参数的递归边。经典的时间反向传播(BPTT)[124]用于训练RNN。Hochreiter&Schmidhuber [125]引入的长期短期记忆(LSTM)是传统RNN的一种特殊形式,用于解决训练RNN时常见的梯度消失和爆炸问题。LSTM中的细胞状态由三个门控制和控制:一个输入门允许或阻止输入信号改变细胞状态,一个输出门使细胞状态能够影响其他神经元,或阻止该状态影响其他神经元。 调制单元的自循环连接以累积或忘记其先前状态。 通过组合这三个门,LSTM可以按顺序对长期依赖性进行建模,并且已被广泛用于基于视频的表情识别任务。
(5)生成对抗网络(Generative Adversarial Network----GAN)
- GAN由Goodfellow等人[84]于2014年首次提出,该模型通过生成器G(z)之间的极小极大两人博弈训练模型,生成器G(z)通过将潜伏z映射到z p(z)的数据空间来生成合成输入数据鉴别器D(x)分配概率y = Dis(x)2 [0; 1] x是一个实际的训练样本,可以区分真实的输入数据和虚假的输入数据。生成器和鉴别器是交替训练的,它们都可以通过相对于D / G最小化/最大化二进制交叉熵LGAN = log(D(x())+ log(1D(G(z))))来提高自身。 x是训练样本,z p(z)。存在GAN的扩展,例如添加条件信息以控制发电机输出的cGAN [126],采用反卷积和卷积神经网络分别实现G和D的DCGAN [127],VAE / GAN [128] ](使用GAN鉴别器中学习到的特征表示作为VAE重建目标的基础)和InfoGAN [129](可以以完全无监督的方式学习纠缠的表示)。
3. 面部表情分类
- 与传统的特征提取步骤和特征分类步骤是独立的不同,深度网络可以以端到端的方式进行分类。具体地说,在网络端添加损耗层来调节反向传播误差;然后,网络可以直接输出每个样本的预测概率。
- 分类方式:
四、 当前的研究进展
这一部分是对当前提出的FER网络及其训练策略做了一个总结。
1. 用于静态图片FER系统的深度神经网络
(1)预训练和微调
- 因为使用现存的较少的数据直接训练神经网络容易出现过拟合的现象,所以一些研究者会使用额外的面向任务的数据(task-oriented data)来预训练他的神经网络。有研究者证明预训练确实可以帮助获取更高的识别率并避免过拟合现象。
- 预训练和微调的方式: 许多研究直接使用额外的任务导向的数据从零开始训练自己的搭建的网络,或者在已经预训练好的网络模型(AlexNet,VGG,VGG-face,GoogleNet)上进行微调。额外的任务导向的数据可以使用大型的人脸数据库或者其他较大的表情识别(FER)数据库。 举例算法:Paper[63]中提出的一种多阶段的训练策略算法:第一阶段微调使用FER2013数据库,第二阶段微调使用目标数据库的训练数据进行微调,使模型更切合目标数据库。如下图: 缺点: 预训练和微调的方式虽然可以提高FER系统的性能,但由于预训练网络独立于FER系统之外,面部主导的信息仍然会保留在学习到的特征里,这会影响FER网络的表情表示能力。 解决方法:在Paper[111]中,作者提出了一种两阶段训练算法—FaceNet2ExpNet,在这个网络中,微调的面部网络作为表情网络的一个比较好的初始化,以及仅仅引导卷积层的学习 网络结构:
(2)多样化网络输入(Diverse network input)
- **存在的问题:**网络的输入是整张图片,这样会丢失一些有效的特征(均匀或规则的纹理)。
- **解决方法:**一些方法使用各种手工制作的特性及其扩展作为网络输入来缓解这个问题(非深度学习的数据作为网络的输入)。
- 算法:论文Page9
(3)辅助层块(Auxiliary blocks & layers)
- 本文介绍的一些添加辅助块或层的网络是基于基础的CNN构建的
- 几种网络: 增强特征学习能力: HoloNet–>For FER Paper[90] Supervised Scoring Ensemble(SSE):在主流CNN的早期隐藏层中嵌入了三种类型的监督块,分别进行浅监督、中监督和深监督。 Feature Selection Network(FSN):在AlexNet中嵌入一个特征选择机构(Feature Selection Mechanism),能够自动的过滤不相干的特征以及加强相关特征 解决面部表情数据中高类间相似和高类内变化:Softmax在表情识别领域的表现不太理想 增加类间距离的island loss 减小类内距离的LP loss:将同一类的局部邻近特征拉在一起,从而使每个类的类内局部簇变得紧凑。 其他的损失函数:见Paper[10]
(4)网络集成(Network Ensemble)
- 网络集成需要考虑的两个关键因素: 足够的网络多样性,确保网络互补性 要有可靠的集成算法。 关于第一点,网络的多样性的产生有很多方法,不同的训练数据、不同的预处理方式、不同的模型、不同的特征都会产生不同的网络;关于第二点:特征集成和输出的决策集成 特征集成: 最常见的方法是将不同的网络模型的特征直接连接 还有如下图的方式: 决策集成 主要是使用投票的方式:多数表决、简单平均、加权平均; 下表是几种策略的表格: 由于加权平均规则考虑了每个人的重要性和置信度,因此提出了许多加权平均方法来找到网络集成的最佳权重集。[57]提出了一种随机搜索方法来对每种情绪类型的模型预测进行加权。[75]使用对数似然损失和铰链损失自适应地为每个网络分配不同的权值。[76]提出了基于验证精度的指数加权平均值来强调合格个体(见图)。[172]使用CNN学习每个单独模型的权值。
(5)多任务网络(Multitask network)
- 许多现存的FER网络都是致力于解决单一的表情问题,但在现实应用中,表情识别往往需要考虑更多的因素(光照、头部姿势、主体身份等(面部形态学))。因此多任务模型被引入到FER中。
- 面部姿势 Reed等[143]构造了一个学习表达式相关因子的流形坐标的高阶Boltzmann machine (disBM),并提出了解纠缠的训练策略,使与表达式相关的隐藏单元不受面部形态学的影响。 其他工作[58][175]提出与其他任务同时进行FER,如人脸地标定位和人脸AUs[176]检测,可以共同提高FER性能。
- 主体身份不变性: identity-aware CNN(IACNN) a multisignal CNN (MSCNN)
(6)级联网络(Cascsded Networks)
- 在级联网络中,针对不同任务的各个模块依次组合,构成一个更深层次的网络,其中前一个模块的输出被后一个模块利用。 相关研究提出通过组合不同的结构来学习特征层次,通过特征层次逐步过滤掉与表达无关的变异因素。
- 相关网络模型: Paper[178]:DBNs+autoencoder Paper[179]:multiscale contractive convolutional network(CCNET 多尺度压缩卷积网)+contractive autoencoder Paper[137] [138]:首先使用CNN架构学习过完备的表示,然后利用多层RBM(受限的玻尔兹曼机)学习FER的高级特征
(7)生成对抗网络(Generative adversarial networks—GANs)
- **作用:**能够生成逼真的面孔、数字等,对数据扩充(Data Augmentation)和识别相关任务有帮助
- **可以解决的问题:**数据单一、身份偏差、头部姿势等
- 数据单一问题:GANs可以生成逼真的面孔,能够实现数据扩充
- 姿势问题:
- 身份偏差问题:
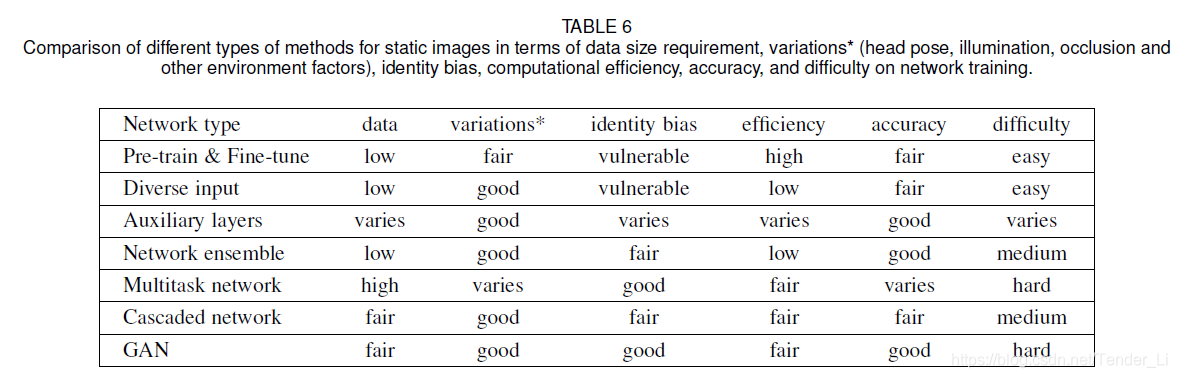
(8)不同网络的不同方面的表现总结
2. 动态图像序列的FER
(1)帧聚合技术
- 由于表情在不同时刻有不同的变化,但又不可能单独的统计每帧的结果作为输出,因此需要对一段帧序列给出一个识别结果,这就需要用到帧聚合。即用一个特征向量表示这一段时间序列。
- **分类:**决策级别的帧聚合技术和特征级别的帧聚合技术 决策级别的帧聚合技术 产生固定长度的帧序列:帧平均(Frame averaging 上图)和帧扩展(下图 Frame expansion); 不需要产生固定长度的帧序列:应用统计编码。可以使用平均、最大、平方的平均、最大抑制向量的平均等方法总结每个序列中每帧的概率。 特征级别的帧聚合技术:对序列中帧的学习特征进行聚合 Paper[88]:将所有帧的特征的均值、方差、最小值和最大值连接起来 Paper[186] [192]:基于矩阵的模型如特征向量、协方差矩阵、多维高斯分布等也可以用于聚集 Paper[193]:视频级表示还探索了多实例学习,其中从辅助图像数据中计算聚类中心,然后对每个视频帧进行词袋表示。
(2)强度表达网络
- 在视频中表情会有微妙的变化,而强度是指在视频中,所有帧表现某个表情的程度。一般在中间位置最能表达某个表情,即为强度峰值。这一部分主要是介绍几个深度网络,他们的输入是具有一定强度信息的样本序列,输出是某一个类表情中不同强度帧之间的相关性结果。
- 几种不同的网络: Paper[17]:Zhao等人提出一种由峰顶引导的深度网络(a peak-piloted deep network—PPDN),以来自同一主体、具有相同表情的一对峰和非峰图像作为输入,利用L2 -范数损失最小化两幅图像之间的距离。用以内在表情序列里帧之间相关性识别。 Paper[70]:基于PPDN,Yu等研究者提出了一种更深度的级联峰值引导网络,使用更深度、更大规模的网络进行训练。具有更深更强的识别能力
(3) 深度时空FER网络
- 虽然帧聚合可以集成视频序列中的帧,但没有明确地利用关键的时间依赖性。与此相反,时空FER网络在不事先知道表达式强度的情况下,将一个时间窗口中的一组帧作为单个输入,并同时利用结构和时间信息对更微妙的表达式进行编码。
- RNN&C3D:利用连续数据的特征向量在语义上是相连的,因此是相互依存的这一事实,RNN可以从序列中稳健地获得信息。即RNN能够利用“序列信息”,所以在视频FER中一般使用RNN模型。 RNN 改进版本LSTM可以灵活地处理可变长度的顺序数据,同时降低了计算成本。 Paper[195]:一种由ReLUs组成并由单位矩阵初始化的RNN (IRNN),用来提供一个更简单的机制来解决消失和爆炸梯度问题 Paper[196]:双向RNNs(BRNNs)被用来学习时间关系在原来的和相反的方向?????? Paper[71]:Nested LSTM(嵌套LSTM),由两个子LSTM组成,其中,T-LSTM对所学特征的时间动力学进行建模,C-LSTM将所有T-LSTM的输出集成在一起,对网络中间层编码的多层特征进行编码。 C3D:是CNN的衍生出来的一种网络,使用基于时间轴共享权值的三维卷积核取代了传统的二维卷积核,被广泛应用于基于动态算法的求解 Paper[199]:在[199]中,3D CNN与受dpm启发的[200]可变形面部动作约束相结合,同时对动态运动和基于鉴别部分的表示进行编码。 Paper[16]:提出了一种深度时间表象网络(DTAN),该网络在时间轴上采用无权值共享的三维滤波器,因此,随着时间的推移,每个过滤器的权值会有所不同。 Paper[190]:加权C3D(Weighted C3D),其中从每个序列中提取连续窗口的几个窗口,并根据它们的预测得分进行加权 Paper[109]:只使用C3D进行时空特征提取,然后与DBN级联进行表情分类。 Paper[201]:C3D被用作特征提取器,随后是NetVLAD层[202],以通过学习聚类中心来聚合运动特征的时间信息。
- Facial landmark trajectory(面部标志轨迹) 通过研究五官的变化轨迹,进而分析表情的变化,如深度几何空间网络(deep temporal geometry network,DTGN)。该方法联合每帧landmark的x,y坐标值,归一化处理后,将landmark作为一个运动轨迹维度,或者或者计算landmark特征点的成对L2距离特征,以及基于PHRNN用于获取帧内的空间变化信息。
- 级联网络 跟之前静态图像的级联网络思路一样,主要是CNN提取特征,级联RNN做序列特征分类。如LRCN,级联CNN与LSTM,类似的,还有级联DAE作为特征提取,LSTM进行分类,还有ResNet-LSTM,即在低级CNN层,直接用LSTM连接序列之间的低级CNN特征,3DIR用LSTM作为一个单元构建了一个3D Inception-ResNet特征层,其他还有很多类似的级联网络,包括,用CRFs代替了LSTM等等。
- 网络集成 如两路CNN网络模型用于行为识别,一路用多帧数据的稠密光流训练获取时间信息,一路用于单帧图像特征学习,最后融合两路CNN的输出。还有多通道训练,如一通道用于自然脸和表情脸之间的光流信息训练,一路用于脸部表情特征训练,然后用三种融合策略,平均融合,基于SVM融合,基于DNN融合。也有基于PHRNN时间网络和MSCNN空间网络相结合来提取局部整体关系,几何变化以及静动态信息。除了融合,也有联合训练的,如DTAN和DTGN联合fineturn训练。
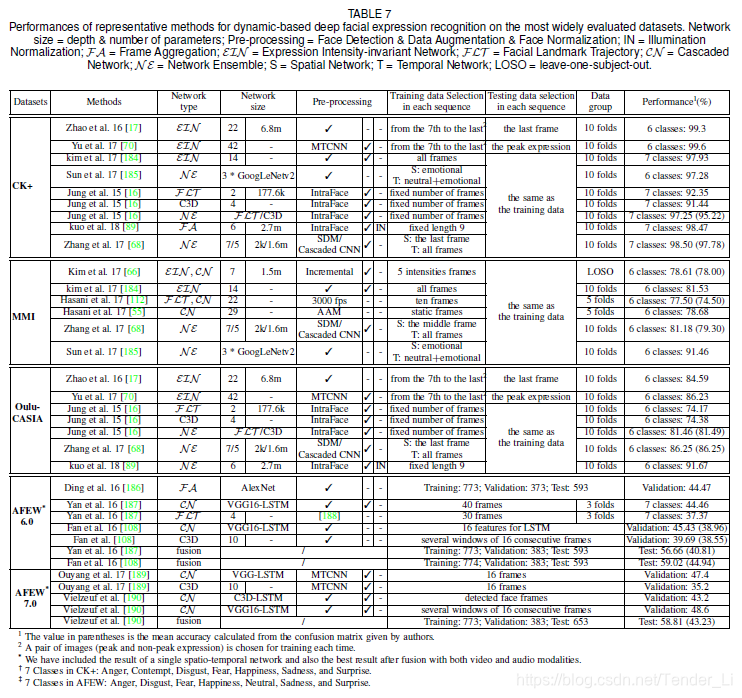
(4)各种模型在数据集上的表现
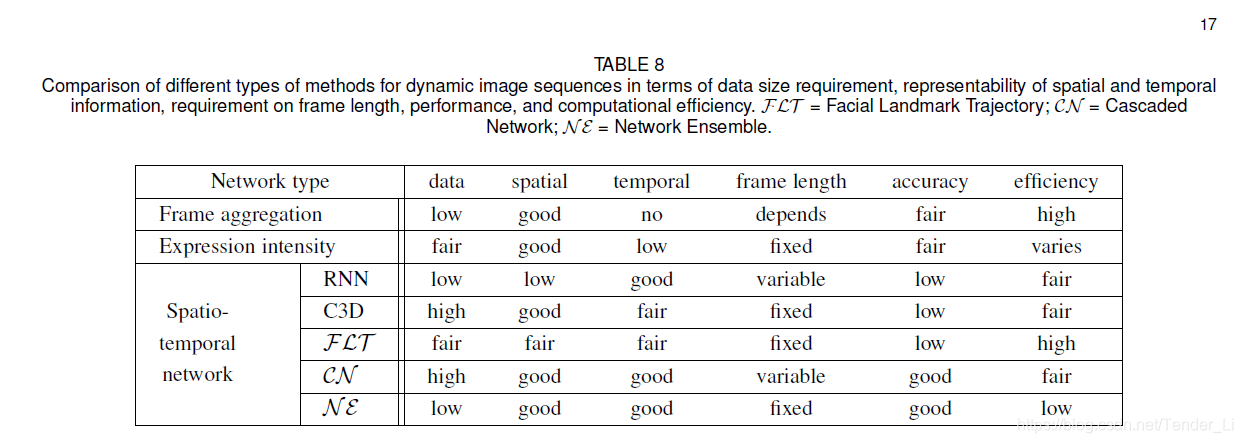
(5)上述几种方法的表现
五、其他相关问题
1. 遮挡和非正面头部姿势
- 说明:遮挡和非额头姿态可能会改变原始面部表情的视觉外观,是实现自动FER的两个主要障碍,特别是在真实场景中。
- 解决方法:
2. 红外数据的FER
- 说明:虽然RBG或灰度数据是目前深FER的标准,这些数据容易受到环境光照条件的影响。而记录由情绪产生的皮肤时间分布的红外图像对光照变化不敏感,这可能是研究面部表情的一种有前途的替代方法。
3. 静态3D数据以及动态数据的FER
4. 面部表情合成
5. 可视化技术
的高级学习特征连接起来。
2. 红外数据的FER
- 说明:虽然RBG或灰度数据是目前深FER的标准,这些数据容易受到环境光照条件的影响。而记录由情绪产生的皮肤时间分布的红外图像对光照变化不敏感,这可能是研究面部表情的一种有前途的替代方法。
3. 静态3D数据以及动态数据的FER
4. 面部表情合成
5. 可视化技术
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。



















































 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















