















































软件

产品




人工智能到底是什么?通常来说,人工智能(Artificial Intelligence)是研究、开发用于模拟、延伸和扩展人智能的理论、方法、技术及应用系统的一门新技术科学。人工智能领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。
但是事实上,给一门学科界定范围是很难的,尤其对于一门正在快速发展的学科更是难上加难。即使是数学这样成熟的学科,有时我们也很难梳理一个明确的边界。而像人工智能这样不断扩展边界的学科,更是很难做出一个相对准确的判断。对于人工智能的应用已经扩展到各个领域,机械、电子、经济甚至哲学,都有所设计。它的实用性极强,是一种极具代表性的多元跨专业学科。
基于AMiner科技情报引擎的梳理描绘,以河流图的形式展示了人工智能在60多年中的发展历史中取得的标志性成果。本文以该河流图为基础,系统的梳理了人工智能的发展过程及其标志性成果,希望能将这段60多年几经沉浮的历史,以一个更加清晰的面貌呈现出来。
人工智能的起源可以追溯到以及阿兰·图灵(Alan Turing)1936年发表的《论可计算数及其在判定问题中的应用》。后来随着克劳德·香农(Claude Shannon)在 1950 年提出计算机博弈。以及艾伦·麦席森·图灵(Alan Mathison Turing)在 1954 年提出“图灵测试”,让机器产生智能这一想法开始进入人们的视野。
1956年达特茅斯学院召开了一个研讨会,John McCarthy, Marvin Minsky, Nathaniel Rochester, 以及Claude Shannon等人正式提出“人工智能”这一概念。算法方面,1957年,Rosenblatt Frank提出感知机算法Perceptron,这不仅开启了机器学习的浪潮,也成为后来神经网络的基础(当然追溯的话,神经网络研究得追溯到1943年神经生理学家麦卡洛克(W. S. McCulloch)和皮茨(W. Pitts)的神经元模型)。
克劳德·艾尔伍德·香农(Claude Elwood Shannon,1916年4月30日—2001年2月24日)是美国数学家、信息论的创始人。
香农是世界上首批提出“计算机能够和人类进行国际象棋对弈”的科学家之一。1950年,他为《科学美国人》撰写过一篇文章,阐述了“实现人机博弈的方法”;他设计的国际象棋程序,发表在同年《哲学杂志》上(计算机下棋程序 Programming a Computer for Playing Chess)。
香农把棋盘定义为二维数组,每个棋子都有一个对应的子程序计算棋子所有可能的走法,最后有个评估函数(evaluation function)。传统的棋局都把下棋过程分为三个阶段,开局、中局和残局,不同阶段需要不同的技术手段。而此论文也引用了冯·诺依曼的《博弈论》和维纳的《控制论》。
这篇论文开启了计算机下棋的理论研究,其主要思路在多年后的“深蓝”及AlphaGo中仍能看到。1956年,在洛斯阿拉莫斯的MANIAC计算机上,他又展示了国际象棋的下棋程序。
艾伦·麦席森·图灵(英语:Alan Mathison Turing,1912年6月23日—1954年6月7日),英国数学家、逻辑学家,被称为计算机科学之父,人工智能之父。
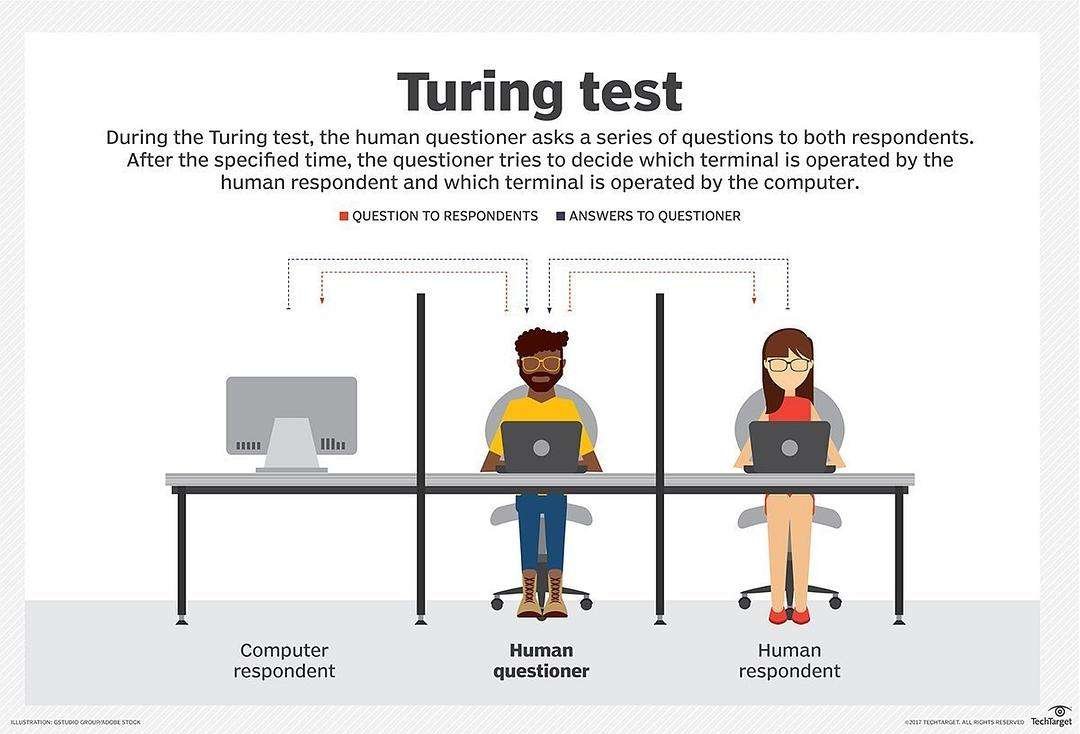
1954年,图灵测试(The Turing test)由图灵发明,指测试者与被测试者(一个人和一台机器)隔开的情况下,通过一些装置(如键盘)向被测试者随意提问。进行多次测试后,如果机器让平均每个参与者做出超过30%的误判,那么这台机器就通过了测试,并被认为具有人类智能。图灵测试一词来源于计算机科学和密码学的先驱艾伦·麦席森·图灵写于1950年的一篇论文《计算机器与智能》,其中30%是图灵对2000年时的机器思考能力的一个预测,目前我们已远远落后于这个预测。
他实际提出了一种测试机器是不是具备人类智能的方法。即假设有一台电脑,其运算速度非常快、记忆容量和逻辑单元的数目也超过了人脑,而且还为这台电脑编写了许多智能化的程序,并提供了合适种类的大量数据,那么,是否就能说这台机器具有思维能力?
图灵肯定机器可以思维的,他还对智能问题从行为主义的角度给出了定义,由此提出一假想:即一个人在不接触对方的情况下,通过一种特殊的方式,和对方进行一系列的问答,如果在相当长时间内,他无法根据这些问题判断对方是人还是计算机,那么,就可以认为这个计算机具有同人相当的智力,即这台计算机是能思维的。这就是著名的“图灵测试”(Turing Testing)。当时全世界只有几台电脑,其他几乎所有计算机根本无法通过这一测试。
要分辨一个想法是“自创”的思想还是精心设计的“模仿”是非常难的,任何自创思想的证据都可以被否决。图灵试图解决长久以来关于如何定义思考的哲学争论,他提出一个虽然主观但可操作的标准:如果一台电脑表现(act)、反应(react)和互相作用(interact)都和有意识的个体一样,那么它就应该被认为是有意识的。
为消除人类心中的偏见,图灵设计了一种“模仿游戏”即图灵测试:远处的人类测试者在一段规定的时间内,根据两个实体对他提出的各种问题的反应来判断是人类还是电脑。通过一系列这样的测试,从电脑被误判断为人的几率就可以测出电脑智能的成功程度。
图灵预言,在20世纪末,一定会有电脑通过“图灵测试”。2014年6月7日在英国皇家学会举行的“2014图灵测试”大会上,举办方英国雷丁大学发布新闻稿,宣称俄罗斯人弗拉基米尔·维西罗夫(Vladimir Veselov)创立的人工智能软件尤金·古斯特曼(Eugene Goostman)通过了图灵测试。虽然“尤金”软件还远不能“思考”,但也是人工智能乃至于计算机史上的一个标志性事件。
1956年夏季,年轻的明斯基与数学家和计算机专家麦卡锡(John MeCarthy,1927—2011)等10人在达特茅斯学院(Dartmouth College办了一个长达2个月的人工智能夏季研讨会,认真热烈地讨论用机器模拟人类智能的问题。会上正式使用了人工智能(artificial intelligence,即 AI)这一术语。
这是人类历史上第一次人工智能研讨,标志着人工智能学科的诞生,具有十分重要的历史意义,为国际人工智能的发展做出重要的开创性贡献。会议持续了一个月,基本上以大范围的集思广益为主。这催生了后来人所共知的人工智能革命。1956年也因此成为了人工智能元年。会议的主要议题包括自动计算机、如何为计算机编程使其能够使用语言、神经网络、计算规模理论、自我改造、抽象、随机性与创造性等。
1957年,弗兰克·罗森布拉特(Frank Rosenblatt)在一台IBM-704计算机上模拟实现了一种他发明的叫做“感知机”(Perceptron)的神经网络模型。罗森布拉特1962年出了本书:《神经动力学原理:感知机和大脑机制的理论》(Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms),基于MCP神经元提出了第一个感知器学习算法,同时它还提出了一个自学习算法,此算法可以通过对输入信号和输出信号的学习,自动获取到权重系数,通过输入信号与权重系数的乘积来判断神经元是否被激活(产生输出信号)。
感知机需要几个二进制输入, X1,X2,…Xn X1,X2,…Xn ,并产生一个二进制输出:
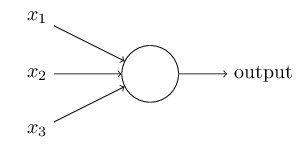
上图所示的 Perceptron Perceptron 有三个输入,但是实际的输入可能远多于三个或是少与三个。 Rosenblatt Rosenblatt 提出了一个简单的规则来计算输出,他首先引入了 weights weights(权重)概念, ω1,ω2,... ω1,ω2,...。以实数权重 ω ω表示输入到输出的重要性,神经元的输出 0 或 1 ,这取决于加权因子(即 weights weights)小于或大于某一阈值。就像权重,阈值为一个实数,是一个神经元的参数。
公式表示为:
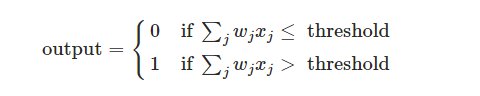
这就是我们熟知的激活函数的最初形态, 0 0 状态代表抑制, 1 1 状态代表激活。这简单的数学公式帮助我们了解 perceptrons perceptrons 是如何工作的。姑且我们把它理解为: 它是一种通过权衡输入信息的重要性来决定你的输出。
到了 20 世纪 60 年代,人工智能出现了第一次高潮,发展出了符号逻辑,解决了若干通用问题,初步萌芽了自然语言处理和人机对话技术。其中的代表性事件是丹尼尔·博布罗(Daniel Bobrow)在1964年发表了Natural Language Input for a Computer Problem Solving System,以及约瑟夫·维森鲍姆(Joseph Weizenbaum)在1966年发表了ELIZA—A Computer Program for the Study of Natural Language Communication between Man and Machine。
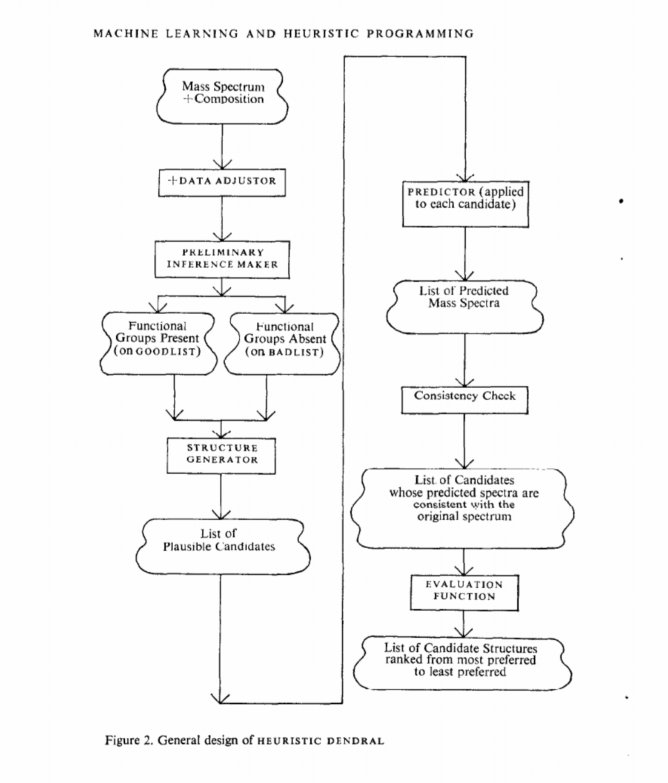
早期的人工智能更多的侧重描述逻辑和通用问题求解上,到了60年代末,爱德华·费根鲍姆(Edward Feigenbaum)提出首个专家系统DENDRAL,并对知识库给出了初步的定义,这也孕育了后来的第二次人工智能浪潮。当然这个时期更重要的情况是大家对人工智能的热情逐渐褪去,人工智能的发展也进入了一轮跨度将近十年的“寒冬”。
1961年,Leonard Merrick Uhr 和 Charles M Vossler发表了题目为A Pattern Recognition Program That Generates, Evaluates and Adjusts its Own Operators 的模式识别论文,该文章描述了一种利用机器学习或自组织过程设计模式识别程序的尝试。程序启动时不仅不知道要输入的特定模式,而且没有任何处理输入的运算符。算符是由程序本身生成和提炼的,它是问题空间的函数,也是处理问题空间的成功和失败的函数。程序不仅学习有关不同模式的信息,而且至少在一定程度上,它还学习或构造适合于分析输入到它特定模式集的二级代码。这也是第一个机器学习程序。
1966 年,麻省理工学院的计算机科学家Joseph Weizenbaum 在 ACM 上发表了题为《 ELIZA,一个研究人机自然语言交流的计算机程序》(ELIZA-a computer program for the study of natural language communication between man and machine)的文章。文章描述了这个叫作 ELIZA 的程序如何使人与计算机在一定程度上进行自然语言对话成为可能。Weizenbaum 开发了最早的聊天机器人 ELIZA,用于在临床治疗中模仿心理医生。
ELIZA 的实现技术是通过关键词匹配规则对输入进行分解,而后根据分解规则所对应的重组规则来生成回复。简而言之,就是将输入语句类型化,再翻译成合适的输出。虽然 ELIZA 很简单,但 Weizenbaum 本人对 ELIZA 的表现感到吃惊,随后撰写了《计算机的能力和人类的推理》(Computer Power and Human Reason)这本书,表达他对人工智能的特殊情感。ELIZA 如此出名,以至于 Siri 也说 ELIZA 是一位心理医生,是她的启蒙老师。
1968年,在美国国家航空航天局要求下,爱德华·费根鲍姆(Edward Feigenbaum)提出首个专家系统DENDRAL,并对知识库给出了初步的定义,这也孕育了后来的第二次人工智能浪潮。当然这个时期更重要的情况是大家对人工智能的热情逐渐褪去,人工智能的发展也进入了一轮跨度将近十年的“寒冬”。该系统具有非常丰富的化学知识,可根据质谱数据帮助化学家推断分子结构。这个系统的完成标志着专家系统的诞生。在此之后, 麻省理工学院开始研制MACSYMA系统,经过不断扩充, 它能求解600多种数学问题。
现在,专家系统(Expert System,简称ES)是人工智能(Artificial Intelligence,简称AI)的一个重要分支,同自然语言理解,机器人学并列为AI的三大研究方向。
20世纪70年代末、80年代初,人工智能进入了第二次浪潮,其中代表性的工作是1976年兰德尔·戴维斯(Randall Davis)构建和维护的大规模的知识库,1980年德鲁·麦狄蒙(Drew McDermott)和乔恩·多伊尔(Jon Doyle)提出的非单调逻辑,以及后期出现的机器人系统。
1980年,汉斯·贝利纳(Hans Berliner)打造的计算机战胜双陆棋世界冠军成为标志性事件。随后,基于行为的机器人学在罗德尼·布鲁克斯(Rodney Brooks)和萨顿(R. Sutton)等人的推动下快速发展,成为人工智能一个重要的发展分支。这其中格瑞·特索罗(Gerry Tesauro)等人打造的自我学习双陆棋程序又为后来的增强学习的发展奠定了基础。
机器学习算法方面,这个时期可谓是百花齐放,百家争鸣。Geoffrey Hinton等人提出的多层感知机,解决了Perceptron存在的不能做非线性分类的问题;Judea Pearl倡导的概率方法和贝叶斯网络为后来的因果推断奠定基础;以及机器学习方法在机器视觉等方向取得快速发展。
1975年,马文·明斯基(Marvin Minsky)在论文《知识表示的框架》(A Framework for Representing Knowledge)中提出框架理论,用于人工智能中的“知识表示”。
明斯基框架不是一种单纯的理论。除了数据结构上有单纯的一面外,在概念上是相当复杂的。针对的是人们在理解事物情景或某一事件时的心理学模型。它将框架看作是知识的基本单位,将一组有关的框架连接起来整合成框架系统。系统中不同框架可用有共同节点,系统的行为由系统的子框架的具体功能来实现。推理过程由子框架的协调来完成。框架理论类似于人工智能中的面向对象化程序设计。它的成功之处是它利用框架这种结构将知识有机的整合起来,使其有一种特定的结构约束。同时保持了结构的相对独立性、封闭性。
明斯基的框架理论体现出来的模块化思想和基于事例的认知推理为其理论增添了永恒的魅力,这也是认知哲学家关注它的一个重要原因。作为认知可计算主义核心代表的明斯基将心智与计算机类比,把认知过程理解为信息加工过程,把一切智能系统理解为物理符号系统。虽然这样做使人们能从环境到心智,又从心智到到环境的信息流中来分析问题,使心智问题研究具有实验上的严格性。但是机械性的缺陷也非常明显。
同时,框架跟软件工程领域面向对象语言中的“类”相似,只是两者的基本设计目标不同。
Douglas Lenat(道格拉斯·布鲁斯·勒纳特)(生于1950年)是德克萨斯州奥斯汀市Cycorp公司的首席执行官,一直是人工智能领域的杰出研究者。他从事过机器学习(与他的AM和Eurisko程序)、知识表示、黑板系统和“本体工程”(在MCC和Cycorp的Cyc程序)。他还从事军事模拟,并发表了一篇对传统随机突变达尔文学说的批判,这是基于他对尤里斯科的经验。列纳特是AAAI的最初成员之一。
在宾夕法尼亚大学,勒纳特获得数学和物理学士学位,并于1972年获得应用数学硕士学位。1976年,他从斯坦福大学获得博士学位,并发表论文《数学中发现的人工智能方法——启发式搜索》。
该文章描述了一个名为“AM”的程序,它模拟了初等数学研究的一个方面:在大量启发式规则的指导下开发新概念数学被认为是一种智能行为,而不是一种成品。本地启发式通过一个议程机制、系统要执行的任务的全局列表以及每个任务合理的原因进行通信。一个单独的任务可以指导AM定义一个新的概念,或者探索一个现有概念的某个方面,或者检查一些经验数据的规律性等。程序从议程中反复选择具有最佳支持理由的任务,然后执行它。每个概念都是一个活跃的、结构化的知识模块。最初提供了一百个非常不完整的模,每个模对应于一个基本的集合论概念(如并集)。这提供了一个明确但巨大的“空间”,AM开始探索。AM扩展了它的知识库,最终重新发现了数百个常见的概念和定理。
1976年,Randall Davis在斯坦福大学获得人工智能博士学位,并发表文章 Applications of Meta Level Knowledge to the Construction, Maintenance and Use of Large Knowledge Bases,此文提出:使用集成的面向对象模型是提高知识库(KB)开发、维护和使用的完整性的解决方案。共享对象增加了模型之间的跟踪能力,增强了半自动开发和维护功能。而抽象模型是在知识库构造过程中创建的,推理则是在模型初始化过程中执行的。
Randall Davis在基于知识的系统和人机交互领域做出了开创性的贡献,发表了大约100多篇文章,并在多个系统的开发中发挥了核心作用。他和他的研究小组通过创建能够理解用户图像、手势和交谈的软件,开发先进的工具,并与计算机进行自然的多模式交互。
视觉计算理论(computational theory of vision)是在20世纪70年代由马尔(David Marr)提出的概念,他在1982发表代表作《视觉计算理论》。他的工作同时对认知科学(CognitiveScience)也产生了很深远的影响。
David Marr生于1945年1月19日,早年就读于剑桥大学三一学院,获得数学硕士、神经生理学博士学位,同时还受过神经解剖学、心理学、生物化学等方面的严格训练。他在英国曾从事新皮层、海马,特别是小脑方面的理论研究。
1974年访问美国,并应M.Minsky教授之请,留在麻省理工学院开展知觉和记忆方面的研究工作。他从计算机科学的观点出发,集数学、心理物理学、神经生理学于一体,首创人的视觉计算理论,使视觉研究的面貌为之一新。
他的理论由他创建的一个以博士研究生为主体的研究小组继承、丰富和发展,并由其学生归纳总结为一本计算机视觉领域著作:Vision: A computational investigation into the human representation and processing of visual information,于他后发表。
计算机视觉是一门研究如何使机器“看”的科学,更进一步的说,就是指用摄影机和计算机代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图像处理,用计算机处理成更适合人眼观察或进行仪器检测的图像。学习和运算能让机器能够更好的理解图片环境,并且建立具有真正智能的视觉系统。当下环境中存在着大量的图片和视频内容,这些内容亟需学者们理解并在其中找出模式,来揭示那些我们以前不曾注意过的细节。
1979 年 7 月,一款名为 BKG 9.8 的计算机程序在蒙特卡洛举行的世界西洋双陆棋锦标赛中夺得冠军。这款程序的发明者是匹兹堡卡内基梅隆大学的计算机科学教授 Hans Berliner(汉斯·柏林格),它在卡内基梅隆的一台大型计算机上运行,并通过卫星连接到蒙特卡洛的一个机器人上。 这个名为 Gammonoid 的机器人胸前有一个西洋棋显示屏,可以显示它自己,以及其意大利对手 Luigi Villa 的动作。Luigi Villa 在短时间内击败了所有人类挑战者,赢得了与 Gammonoid 对弈的权利。竞赛的奖励是五千美元,Gammonoid 最终以 7:1 赢得了比赛。
全世界都知道了:BKG9.8于1979年击败了西洋双陆棋世界冠军。
专家系统产生于六十年代中期,以Bruce G Buchanan在1968年发表的文章《 启发式DENDRAL:一个在有机化学中生成解释性假说的程序》为始。在美国国家航空航天局要求下,斯坦福大学成功研制了DENRAL专家系统,该系统具有非常丰富的化学知识,可根据质谱数据帮助化学家推断分子结构。这个系统的完成标志着专家系统的诞生。在此之后, 麻省理工学院开始研制MACSYMA系统,现经过不断扩充, 它能求解600多种数学问题。虽然它只有不到三十年的历史,但其发展速度相当惊人,它的应用几乎已渗透到自然界的各个领域。
专家系统定义为:使用人类专家推理的计算机模型来处理现实世界中需要专家作出解释的复杂问题,并得出与专家相同的结论。简专家系统可视作“知识库(knowledge base)”和“推理机(inference machine)” 的结合。它同自然语言理解、机器人学并列为人工智能的三大研究方向,并且是人工智能中最活跃的分支。
朱迪亚·珀尔(Judea Pearl),以色列裔美国计算机科学家和哲学家,以倡导人工智能的概率方法和发展贝叶斯网络而闻名(。他还因发展了一种基于结构模型的因果和反事实推理理论而受到赞誉。2011年,计算机械协会授予Judea Pearl图灵奖,原因为——“通过发展概率和因果推理微积分对人工智能做出了根本性贡献”。
贝叶斯网络(Bayesian network),又称信念网络(Belief Network),或有向无环图模型(directed acyclic graphical model),是一种概率图模型,于1985年由Judea Pearl首先提出。它是一种模拟人类推理过程中因果关系的不确定性处理模型,其网络拓朴结构是一个有向无环图(DAG)。

贝叶斯网络的有向无环图中的节点表示随机变量{X1,X2,...,Xn}{X1,X2,...,Xn}
它们可以是可观察到的变量,或隐变量、未知参数等。认为有因果关系(或非条件独立)的变量或命题则用箭头来连接。若两个节点间以一个单箭头连接在一起,表示其中一个节点是“因(parents)”,另一个是“果(children)”,两节点就会产生一个条件概率值。
简言之,把某个研究系统中涉及的随机变量,根据是否条件独立绘制在一个有向图中,就形成了贝叶斯网络。其主要用来描述随机变量之间的条件依赖,用圈表示随机变量(random variables),用箭头表示条件依赖(conditional dependencies)。
此外,对于任意的随机变量,其联合概率可由各自的局部条件概率分布相乘而得出:
P(x1,...,xk)=P(xk|x1,...,xk−1)...P(x2|x1)P(x1)
1986年,Brooks发表论文《移动机器人鲁棒分层控制系统》,标志着基于行为的机器人学的创立。文章介绍了一种新的移动机器人控制体系结构。为了让机器人在不断提高的能力水平上操作,建立了多层次的控制系统。层由异步模块组成,这些模块通过低带宽信道进行通信。每个模块都是一个相当简单的计算机实例。较高级别的层可以通过抑制其输出来容纳较低级别的角色。但是,随着更高级别的添加,较低级别继续发挥作用。其结果是一个鲁棒和灵活的机器人控制系统。该系统已用于控制移动机器人在无限制的实验室区域和计算机机房中漫游。最终,它的目标是控制一个在我们实验室的办公区域徘徊的机器人,用一个内置的手臂来完成简单的任务,绘制出周围环境的地图。
基于行为的机器人学的理论提出了与基于符号的人工智能完全不同的有关智能的观点和结构,主要是实现以下二个观念上的转变:第一,智能不是符号化的模型;第二,智能不是由输入得到输出的计算过程。
20世纪90年代,AI 出现了两个很重要的发展:一方面是蒂姆·伯纳斯·李(Tim Berners-Lee)在1998年提出的语义网,即以语义为基础的知识网或知识表示。后来又出现了 OWL 语言和其他一些相关知识描述语言,这为知识库的两个核心问题:知识表达和开放知识实体,给出了一个可能的解决方案(尽管这一思路在后来一直没有得到广泛认可,直到2012年谷歌提出知识图谱的概念,才让这一方向有了明确的发展思路)。
另一个重要的发展是统计机器学习理论,包括Vapnik Vladimir等人提出的支持向量机、John Lafferty等人的条件随机场以及David Blei和Michael Jordan等人的话题模型LDA。总的来讲这一时期的主旋律是AI平稳发展,人工智能相关的各个领域都取得长足进步。
1995年,Cortes和Vapnik首次提出支持向量机(Support Vector Machine)的概念,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。
支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane)。
同时,支持向量机方法是建立在统计学习理论的VC 维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度,Accuracy)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折衷,以期获得最好的推广能力(或称泛化能力)。
John Lafferty于2001年首次提出条件随机场模型,它是基于贝叶斯理论框架的判别式概率图模型,当时用于文本的分割和标注,同时在许多自然语言处理任务中比如分词、命名实体识别等表现尤为出色。CRF最早是针对序列数据分析提出的,现已成功应用于自然语言处理(NLP)、生物信息学、机器视觉及网络智能等领域。
简单地讲,随机场可以看成是一组随机变量的集合(这组随机变量对应同一个样本空间)。当给每一个位置按照某种分布随机赋予一个值之后,其全体就叫做随机场。当然,这些随机变量之间可能有依赖关系,一般来说,也只有当这些变量之间有依赖关系的时候,我们将其单独拿出来看成一个随机场才有实际意义。
设X与Y是随机变量,P(Y|X)是在给定X的条件下Y的条件概率分布,若随机变量Y构成一个由无向图G=(V,E)表示的马尔科夫随机场,即:对任意的结点v成立,则称条件概率分布P(Y|X)为条件随机场。
这个概念看起来挺抽象的涉及到了很多其他的概念,此时如果你回去再看一遍开头我们的定义部分,就会明白许多,所谓的条件随机场不过是一组随机变量X,Y形成的条件概率的集合,但是这个条件概率满足了马尔科夫独立性假设/概率无向图模型的条件,所以我们称之为条件随机场! 上述定义的解释也很直观,那就是:所有不跟我直接相连的变量都跟我没关系!
1997年5月11日,举世瞩目的人与计算机大战在经过6场拼杀后终见伯仲。尽管人脑战胜电脑为民意所归——据美国有限电视网与《今日美国》日报的民意调查,82%的人希望人脑取胜;尽管棋王坚信世界上最好的棋手可以利用创造力和想象力战胜硅片——他认为:“在严肃而标准的国际象棋中,计算机在本世纪是不会得手的。”但事实胜于雄辩,IBM"深蓝"(Deep Blue)最终以3.5:2.5战胜了国际象棋大师卡斯帕罗夫(Kasparov),并成为纽约国际象棋人机赛110万美元奖金的最终赢家,同时成为首台打败了国际象棋世界冠军的电脑。其实正如IBM公司所说,无论鹿死谁手,人类都是最后赢家。
随后数年,人们对待机器的态度渐渐恢复理性。个人计算机的功能大幅增强,智能手机如今可以同时运行和深蓝一样强大的象棋引擎与其他应用。更重要的是,得益于人工智能的最新进展,机器现在可以自己学习和探索游戏。
深蓝的背后仍旧是人类为国际象棋对弈而设计的代码规则。相比之下,Alphabet子公司DeepMind在2017年推出的程序AlphaZero,通过反复练习,可以自学成为大师级选手。甚至,AlphaZero还挖掘出一些新的策略,这些策略让国际象棋专家都自叹不如。
语义网(Semantic Web)是由万维网联盟的蒂姆·伯纳斯·李(Tim Berners-Lee)在1998年提出的的一个概念,它的核心是:通过给万维网上的文档(如HTML)添加能够被计算机所理解的语义(Meta data),从而使整个互联网成为一个通用的信息交换媒介),其最基本的元素就是语义链接(linked node)。
语义网是一个更官方的名称,也是该领域学者使用得最多的一个术语,同时,也用于指代其相关的技术标准。在万维网诞生之初,网络上的内容只是人类可读,而计算机无法理解和处理。比如,我们浏览一个网页,我们能够轻松理解网页上面的内容,而计算机只知道这是一个网页。网页里面有图片,有链接,但是计算机并不知道图片是关于什么的,也不清楚链接指向的页面和当前页面有何关系。语义网正是为了使得网络上的数据变得机器可读而提出的一个通用框架。“Semantic”就是用更丰富的方式来表达数据背后的含义,让机器能够理解数据。“Web”则是希望这些数据相互链接,组成一个庞大的信息网络,正如互联网中相互链接的网页,只不过基本单位变为粒度更小的数据。
在机器学习领域,LDA是两个常用模型的简称:Linear Discriminant Analysis 和 Latent Dirichlet Allocation。本文的LDA仅指代Latent Dirichlet Allocation. LDA 在主题模型中占有非常重要的地位,常用来文本分类。
LDA由Blei、 David M.、Ng, Andrew Y.、Jordan于2003年提出,用来推测文档的主题分布。它可以将文档集中每篇文档的主题以概率分布的形式给出,从而通过分析一些文档抽取出它们的主题分布后,便可以根据主题分布进行主题聚类或文本分类。
LDA是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
第三次人工智能浪潮兴起的标志可能要数2006杰弗里·辛顿(Geoffrey Hinton)等人提出的深度学习,或者说Hinton等人吹响了这次浪潮的号角。与之前最大的不同,这次引领浪潮冲锋的是企业:塞巴斯蒂安·特龙(Sebastian Thrun)在谷歌领导了自动驾驶汽车项目;IBM 的沃森(Watson)于 2011 年在《危险边缘》(Jeopardy)中战胜人类、获得冠军;苹果在 2011 年推出了自然语言问答工具 Siri 等;2016年谷歌旗下DeepMind公司推出的阿尔法围棋(AlphaGo)战胜围棋世界冠军李世石等。可以说这次人工智能浪潮的影响是前所未有的。
波士顿动力公司(英语:Boston Dynamics)创办与是一家美国的工程与机器人设计公司,此公司的著名产品包含在国防高等研究计划署(DARPA)出资下替美国军方开发的四足机器人:波士顿机械狗,以及DI-Guy,一套用于写实人类模拟的现成软件(COTS)。此公司早期曾和美国系统公司一同接受来自美国海军航空作战中心训练处(NAWCTSD)的一份合约,该合约的内容是要以DI-Guy人物的互动式3D电脑模拟,取代海军飞机弹射任务训练影片。
该公司由Marc Raibert和其合伙人一起创办。Marc Raibert是著名的机器人学家。其28岁毕业于MIT,随后在CMU担任过副教授,并且在那里建立了CMUleg实验室研究与机器人有关的控制和视觉处理相关的技术。在37岁时回到MIT的继续从事机器人相关的科研和教学工作。在1992年,其与合伙人一起创办了Boston Dynamics这家公司,开启了机器人研究的新纪元。
波士顿动力公司于 2005 年推出一款四足机器人——big Dog ,它被人们亲切地称为 “大狗”,也正是这款四足机器人让波士顿动力公司名声大噪。大狗抛开传统的轮式或履带式机器人,转而研究四足机器人,是因为四足机器人能够适应更多地形地貌,通过性能更强。同时,在波士顿动力公司发布的宣传视频中,Big Dog 在装载着重物的情况下,仍能对人类从其侧面的踢踹做出灵敏的反应,始终保持站立的姿态。
在2013年12月13日,波士顿动力公司被Google收购。2017年6月9日软银以不公开的条款收购谷歌母公司Alphabet旗下的波士顿动力公司。
迁移学习是机器学习的一个重要分支,是指利用数据、任务、或模型之间的相似性,将在源领域学习过的模型,应用于新领域的一种学习过程。比如我们大部分人学摩托车的时候,都是把骑自行车的经验迁移了过来。
2010年时Sinno Jialin Pan和 Qiang Yang发表文章《迁移学习的调查》,详细介绍了迁移学习的分类问题。当以迁移学习的场景为标准时分为三类:归纳式迁移学习(Inductive Transfer Learning)、直推式迁移学习(Transductive Transfer Learning)、和直推式迁移学习(Unsupervised Transfer Learning)。

深度迁移学习主要就是模型的迁移,一个最简单最常用的方法就是fine-tuning,就是利用别人已经训练好的网络,针对目标任务再进行调整。近年来大火的BERT、GPT、XLNET等都是首先在大量语料上进行预训练,然后在目标任务上进行fine-tuning。
Watson是一种能够回答自然语言提出的问题的问答计算机系统,由主要研究员David Ferrucci领导的研究小组在IBM的DeepQA项目中开发。Watson以IBM的创始人兼第一任首席执行官工业家Thomas J. Watson的名字命名。
最初开发Watson计算机系统是为了回答测验节目 Jeopardy!中的问题,并且在2011年参与Jeopardy比赛与与冠军布拉德·鲁特(Brad Rutter)和肯·詹宁斯(Ken Jennings)竞争。最终赢得了胜利赢得一百万美元的冠军奖金。
Waston运行机制:
Watson是作为问题解答(QA)计算系统被创建的,它将高级自然语言处理,信息检索,知识表示,自动推理和机器学习技术应用于开放域问题解答领域。
QA技术与文档搜索之间的主要区别在于,文档搜索采用关键字查询并返回按与查询相关性排序的文档列表(通常基于受欢迎程度和页面排名),而QA技术则采用以自然语言,试图更详细地理解它,以此反馈出对该问题的精确答案。创建是IBM时表示,“有100多种不同的技术用于分析自然语言,识别来源,查找和生成假设,查找和评分证据以及合并和排列假设。” 近年来,Watson的功能得到了扩展,Watson的工作方式也发生了变化,以利用新的部署模型(IBM Cloud上的Watson)以及不断发展的机器学习功能和开发人员和研究人员可用的优化硬件。它不再是单纯的问答(QA)计算系统的Q&A对设计的,但现在可以“看”,“听”,“读”,“讲”,“味道”,“解释”,“学习”和“推荐'。
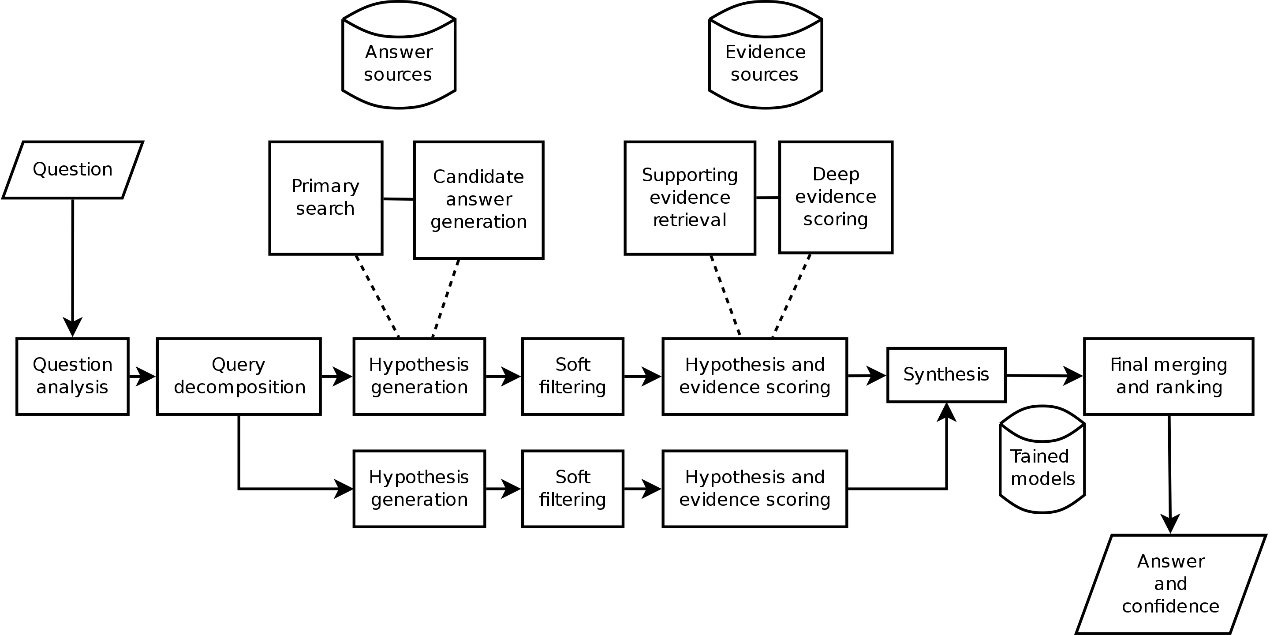
Watson中使用的IBM Deep QA的高级体系结构
大卫·费鲁奇(David Ferrucci)是首席研究员,他在2007年至2011年带领IBM和学术研究人员及工程师组成的团队,开发了赢得Jeopardy的沃森计算机系统。
Ferrucci 于1994年毕业于曼哈顿学院,获得生物学学士学位,并于Rensselaer理工学院获得博士学位。计算机科学学位,专门研究知识表示和推理。[2] 他于1995年加入IBM的Thomas J. Watson,并于2012年离开,加入Bridgewater Associates。[3]他还是Elemental Cognition的创始人,首席执行官兼首席科学家,该公司致力于探索自然学习这一新的研究领域,Ferrucci将其描述为“人工智能,它以人们的方式理解世界”。
Google的自动驾驶技术开发始于2009年1月17日,一直在在该公司秘密的X实验室中进行,在2010年10月9日《纽约时报》透露其存在之后,当天晚些时候,谷歌通过正式宣布了自动驾驶汽车计划。该项目由斯坦福大学人工智能实验室(SAIL)的前负责人塞巴斯蒂安·特伦(Sebastian Thrun )和510系统公司和安东尼机器人公司的创始人安东尼·莱万多夫斯基(Anthony Levandowski)发起。
在Google工作之前,Thrun和包括Dmitri Dolgov,Anthony Levandowski和Mike Montemerlo在内的15位工程师共同为SAIL开展了名为VueTool的数字地图技术项目。许多团队成员在2005 DARPA大挑战赛上见面,Thrun和Levandowski都有团队竞争自动无人驾驶汽车挑战。在2007年,Google收购了整个VueTool团队,以帮助推进Google的街景技术。
作为街景服务开发的一部分,购买了100辆丰田普锐斯,并配备了莱康多夫斯基公司510 Systems开发的Topcon盒,数字地图硬件。2008年,街景小组启动了“地面真相”项目,目的是通过从卫星和街景中提取数据来创建准确的路线图。这为Google的自动驾驶汽车计划奠定了基础。
2014年5月下旬,Google展示了其无人驾驶汽车的新原型,该汽车无方向盘,油门踏板或制动踏板,并且100%自治。12月,他们展示了一个功能完备的原型,计划从2015年初开始在旧金山湾区道路上进行测试。这款车名Firefly,旨在用作实验平台和学习,而不是大量生产。
2015年,联合创始人Anthony Levandowski和CTO Chris Urmson离开了该项目。2015年8月,Google聘用了现代汽车前高管约翰·克拉夫奇克(John Krafcik)作为首席执行官。 2015年秋天,Google向总工程师纳撒尼尔·费尔菲尔德(Nathaniel Fairfield)的合法盲人朋友提供了“世界上第一个完全无人驾驶的公共道路上的骑行服务” 。这次乘车之旅由得克萨斯州奥斯汀市圣塔克拉拉谷盲中心的前首席执行官史蒂夫·马汉(Steve Mahan)乘车。这是公共道路上的第一个完全无人驾驶的汽车。它没有测试驾驶员或警察护送,也没有方向盘或地板踏板。截至2015年底,这辆汽车已实现超过100万英里的自驾里程。
2016年12月,该部门从Google独立出来,更名为Waymo,并拆分为Alphabet的新部门。这意味着Google在主线业务中放弃了自动驾驶汽车项目。
谷歌知识图谱(英语:Google Knowledge Graph,也称Google知识图)是Google的一个知识库,其使用语义检索从多种来源收集信息,以提高Google搜索的质量。知识图谱2012年加入Google搜索,2012年5月16日正式发布。
Google Knowledge Graph 是 Google 一个相当有野心的计划 -- 在这里 Google 为字串赋予了意义,而不只是单纯的字串而已。以 Google 自己的例子来说,当你在英文 Google 上搜索泰姬马哈陵(Taj Mahal)的时候,传统的搜索会试着比对这个字串和 Google 扒下来的巨大文章库,找出最合适的结果,并依照 Google 神秘的演算法进行排序;但在 Google Knowledge Graph 里 Taj Mahal 会被理解成一个「东西」,并在搜索结果的右侧显示它的一些基本资料,像是地理位置、Wiki 的摘要、高度、建筑师等等,再加上一些和它类似的「东西」,例如万里长城等。
当然,Google 也了解「Taj Mahal」不见得一定是指泰姬马哈陵 -- 这就是 Knowledge graph 的威力显现出来的时候了。在泰姬马哈陵的框框底下还有两个常见的「Taj Mahal」,一个是歌手,另一个是一间赌场,正常状况下你如果想找这两个 Taj Mahal,却打不对关键字的话,有可能搜索结果会被最有名的那个淹没,但 Google Knowldge Graph 可以协助你找到你要的那个特定的内容。
Google 希望藉由 Knowledge Graph 来在普通的字串搜索上叠一层相互之间的关系,协助使用者更快找到所需的资料的同时,也可以更了解使用者需要的是什么,从而往以「知识」为基础的搜索更近一步。目前 Google 的这张 Knowledge Graph 已经有五亿样「东西」在上面,产生 35 亿个属性和相互关系,未来当然还会再继续扩充下去。继续阅读里有 Google 的介绍视频,可惜目前只支持英文,不知道还要多久才会支持中文呢。
Knowledge Graph的历史
这些内容是怎么来的呢?当然,不可能完全靠google自己搜索数据得到,因为,这个数据实在是太庞大了。
比如说,其中有部分数据来源于The World Factbook(世界概况) - CIA(中央情报局):《世界概况》是由美国中央情报局出版的调查报告,发布世界各国及地区的概况,例如人口、地理、政治及经济等各方面的统计数据。因中央情报局属美国政府部门,所以其资料格式、体例、内容皆需符合美国政府的官方需要及立场资料则是由美国国务院、美国人口调查局、国防部等部门及其辖下的相关单位提供。(google)
还有数据来自freebase:Freebase是一个由元数据组成的大型合作知识库,内容主要来自其社区成员的贡献。它整合了许多网上的资源,包括部分私人wiki站点中的内容。Freebase致力于打造一个允许全球所有人(和机器)快捷访问的资源库。它由美国软件公司Metaweb开发并于2007年3月公开运营。2010年7月16日被谷歌收购。 2014年12月16日,Google宣布将在六个月后关闭Freebase,并将全部数据迁移至维基数据。
当然,还有大名鼎鼎的wikipedia。
在2012年的时候,google的语义网络就已经包含了超过5亿7千万个对象实体,而且对象实体之间超过了180亿的史实和关系。这些数据用于理解我们输入到搜索栏中的关键字。
在2012年12月4日,Knowledge Graph被翻译成了七中语言,其中包括了:西班牙语,法语,德语,葡萄牙语,日语,俄语和意大利语。
AlexNet是一种卷积神经网络(CNN),由亚历克斯·克里泽夫斯基(Alex Krizhevsky)设计,与伊尔亚‧苏茨克维(Ilya Sutskever)和克里泽夫斯基的博士导师杰弗里·辛顿(Geoff Hinton)共同发表. AlexNet参加了2012年9月30日举行的ImageNet大规模视觉识别挑战赛,达到最低的15.3%的Top-5错误率,比第二名低10.8个百分点,至此一战成名。原论文的主要结论是,模型的深度对于提高性能至关重要,AlexNet的计算成本很高,但因在训练过程中使用了图形处理器(GPU)而使得计算具有可行性 。
克里热夫斯基(Krizhevsky)出生于乌克兰,在加拿大长大,当时他与杰弗里·辛顿(Geoff Hinton)接触,打算在多伦多大学(University of Toronto)从事AI的计算机科学博士学位研究。在读研究生时,克里热夫斯基就在阅读由其导师辛顿(Hinton)发明的一种早期算法的论文,该算法称为““restricted Boltzmann machine”。此时他已经发现图形处理器(GPU)与restricted Boltzmann machines一起使用的前景,而不是中央处理器(CPU)。他认为,如果可以在其他具有更多层(或称为“深度神经网络”)的神经网络上使用这些GPU,则可以提高深度神经网络的处理速度并创建更好的算法。在算法准确性方面可以迅速超越其他最新基准。
在他发现之后不久,2011年,辛顿的另一个研究生Sutskever就了解了ImageNet数据集。ImageNet有超过一百万张图像,是专门为多伦多团队试图解决的计算机视觉算法而设计的。“我意识到他的代码能够解决ImageNet,” Sutskever说。“当时的实现还不是很明显。”
两个人经过一番研究后,克里热夫斯基使用他的GPU加速代码的增强功能来训练数据集上的神经网络。更高的计算速度使网络可以在五六天内处理数百万张图像,而不是以前需要花费的几周甚至几个月的时间。所有可以处理的额外数据使神经网络在分辨图像中对象之间的差异方面具有空前的敏感性。
之后,二人和其导师辛顿一起参加了2012年的ImageNet竞赛。该竞赛是对AI的一种测试,其中包括庞大的在线图像数据库。这项比赛对全世界的所有人都开放,旨在评估为大规模物体检测和图像分类而设计的算法。关键不仅仅在于赢得胜利,还在于检验一个假设:如果使用正确的算法,那ImageNet数据库中的大量数据可能是释放AI潜力的关键。最后他们以错误率低于第二名10.8%的巨大优势击败其他所有研究实验室。
然而最开始的时候,Hinton是反对这种想法的,因为他认为,仍然需要告知神经网络哪些对象位于哪些图像中,而不是学习标签本身。尽管持怀疑态度,他但仍以顾问身份为该项目做出了贡献。克里热夫斯基仅仅用了六个月的时间就让他的神经网络就达到了ImageNet的图像分类基准,然后又花了六个月才能达到团队提交的结果。
最终的克里热夫斯基神经网络框架在AI领域的一项开创性研究论文中得到了验证,该论文首先在ImageNet挑战之后于2012年在AI最大的年度会议上提出。
现在的神经网络框架通称为AlexNet,但最初并未使用该名称。在ImageNet挑战之后,Google任命了名叫Wojciech Zaremba的实习生(现为OpenAI的机器人负责人)在克里热夫斯基的基础上重新编写了一套框架作为该公司的论文。由于Google具有按照其创建者命名神经网络的传统,因此该公司对克里热夫斯基的神经网络的近似版本最初称为WojNet。但是随后Google赢得了邀请克里热夫斯基的争夺战,并收购了其神经网络,此后名称已正确更改为AlexNet。
VAE,也可以叫做变分自编码器,属于自动编码器的变体。VAE于2013年,由Durk Kingma和Max Welling在ICLR上以文章《Auto-Encoding Variational Bayes》发表。
自动编码器是一种人工神经网络,用于学习高效的数据值编码以无监督方式。自动编码器的目的是通过训练网络忽略信号“噪声” 来学习一组数据的表示(编码),通常用于降维。基本模型存在几种变体,其目的是强制学习的输入表示形式具有有用的属性。
与经典(稀疏,去噪等)自动编码器不同,变分自动编码器(VAE)是生成模型,例如生成对抗网络。文章重点解决,在存在具有难解的后验分布的连续潜在变量和大型数据集的情况下,如何在定向概率模型中进行有效的推理和学习。他们引入了一种随机变分推理和学习算法,该算法可以扩展到大型数据集,并且在某些微分可微性条件下甚至可以在难处理的情况下工作。
作者证明了变化下界的重新参数化产生了一个下界估计量,该估计量可以使用标准随机梯度方法直接进行优化。 其次表明,对于每个数据点具有连续潜在变量的iid数据集,通过使用拟议的下界估计器将近似推理模型(也称为识别模型)拟合到难处理的后验,可以使后验推理特别有效。
主要提出者Durk Kingma(Diederik P. Kingma),目前就职于Google。 在加入Google之前,于2017年获得阿姆斯特丹大学博士学位,并于2015年成为OpenAI创始团队的一员。 他主要研究的方向为:推理,随机优化,可识别性。其中的研究成就包括变分自编码器(VAE)(一种用于生成建模的有原则的框架)以及广泛使用的随机优化方法Adam。
生成对抗网络(Generative Adversarial Network,简称GAN)是非监督式学习的一种方法,通过让两个神经网络相互博弈的方式进行学习。该方法由伊恩·古德费洛等人于2014年提出。生成对抗网络由一个生成网络与一个判别网络组成。生成网络从潜在空间(latent space)中随机取样作为输入,其输出结果需要尽量模仿训练集中的真实样本。判别网络的输入则为真实样本或生成网络的输出,其目的是将生成网络的输出从真实样本中尽可能分辨出来。而生成网络则要尽可能地欺骗判别网络。两个网络相互对抗、不断调整参数,最终目的是使判别网络无法判断生成网络的输出结果是否真实。
框架中同时训练两个模型:捕获数据分布的生成模型G,和估计样本来自训练数据的概率的判别模型D。G的训练程序是将D错误的概率最大化。这个框架对应一个最大值集下限的双方对抗游戏。可以证明在任意函数G和D的空间中,存在唯一的解决方案,使得G重现训练数据分布,而D=0.5。在G和D由多层感知器定义的情况下,整个系统可以用反向传播进行训练。在训练或生成样本期间,不需要任何马尔科夫链或展开的近似推理网络。实验通过对生成的样品的定性和定量评估证明了本框架的潜力
生成对抗网络常用于生成以假乱真的图片。此外,该方法还被用于生成影片、三维物体模型等。虽然生成对抗网络原先是为了无监督学习提出的,它也被证明对半监督学习、完全监督学习、强化学习是有用的。
GAN的提出者伊恩·古德费洛,曾就读于斯坦福大学,在那里获得了了计算机科学学士和硕士学位,之后在Yoshua Bengio和Aaron Courville 的指导下于蒙特利尔大学获得机器学习博士学位。毕业后,Goodfellow加入Google,成为Google Brain研究小组的成员。2015年他离开了Google,加入了新成立的OpenAI研究所。2017年3月回到Google Research。
Goodfellow最知名的成就就是发明了GAN,被誉为GAN之父。同时他还是 Deep Learning 教材的主要作者。在Google,他开发了一个系统,该系统使Google Maps能够自动转录街景汽车拍摄的照片中的地址,并展示了机器学习系统的安全漏洞。
2017年,Goodfellow被《MIT技术评论》的35位35岁以下的创新者所引用。在2019年,他被列入《外交政策》的100位全球思想家名单。
随机失活(dropout)是对具有深度结构的人工神经网络进行优化的方法,在学习过程中通过将隐含层的部分权重或输出随机归零,降低节点间的相互依赖性(co-dependence )从而实现神经网络的正则化(regularization),降低其结构风险(structural risk)。2014年,针对神经网络容易过拟合的问题,Srivastava和Hinton等人完整的对dropout进行了描述,并证明了比当时使用的其他正则化方法有了重大改进。实证结果也显示dropout在许多基准数据集上获得了优秀的结果。
2012年,Hinton和Srivastava等人首先提出了Dropout的思想。2013年,Li Wan和Yann LeCun等人介绍了Drop Connect,是另一种减少算法过拟合的正则化策略,是 Dropout 的一般化。在 Drop Connect 的过程中需要将网络架构权重的一个随机选择子集设置为零,取代了在 Dropout 中对每个层随机选择激活函数的子集设置为零的做法。Drop Connect 和 Dropout 相似的地方在于它涉及在模型中引入稀疏性,不同之处在于它引入的是权重的稀疏性而不是层的输出向量的稀疏性。2014年,针对神经网络容易过拟合的问题,Srivastava和Hinton等人完整的对dropout进行了描述,并证明了比当时使用的其他正则化方法有了重大改进。实证结果也显示dropout在许多基准数据集上获得了优秀的结果。自2014年Srivastava和Hinton等人的论文发表后,Dropout很快受到了各类研究的青睐。在批归一化(BN)提出之前,Dropout 几乎是所有的最优网络的标配,直到Ioffe & Szegedy 于 2015 提出批归一化(BN)技术,通过运用该技术,不仅可以加速现代模型的速度,而且可以以正则项的形式来提高基线水平。因此,批归一化几乎应用在近期所有的网络架构中,这说明了它强大的实用性和高效性。
深度学习(Deeping Learning)可以作为机器学习最重要的一个分支。2006年,被称为深度学习元年。2006年杰弗里 ·辛顿以及他的学生鲁斯兰·萨拉赫丁诺夫正式提出了深度学习的概念。杰弗里 ·辛顿也因此被称为深度学习之父。2015年,杰弗里 ·辛顿等人在世界顶级学术期刊 《自然》 发表的一篇文章中详细的给出了 “梯度消失”问题的解决方案 —— 通过无监督的学习方法逐层训练算法,再使用有监督的反向传播算法进行调优。该深度学习方法的提出,立即在学术圈引起了巨大的反响,以斯坦福大学、多伦多大学为代表的众多世界知名高校纷纷投入巨大的人力、财力进行深度学习领域的相关研究。而后又在迅速蔓延到工业界中。因为在深度学习方面做出的突出贡献,2019年3月27日,ACM(美国计算机协会)宣布,有“深度学习三巨头”之称Yoshua Bengio、Yann LeCun、Geoffrey Hinton共同获得了2018年的图灵奖,这是图灵奖1966年建立以来少有的一年颁奖给三位获奖者。
2012年,在著名的ImageNet图像识别大赛中, 杰弗里 ·辛顿领导的小组采用深度学习模型AlexNet一举夺冠。同年,由斯坦福大学著名的吴恩达教授和世界顶尖计算机专家Jeff Dean共同主导的深度神经网络 —— DNN技术在图像识别领域取得了惊人的成绩,在ImageNet评测中成功的把错误率从26%降低到了15%。深度学习算法在世界大赛的脱颖而出,也再一次吸引了学术界和工业界对于深度学习领域的关注。
随着深度学习技术的不断进步以及数据处理能力的不断提升,2014年,Facebook基于深度学习技术的DeepFace项目,在人脸识别方面的准确率已经能达到97%以上,跟人类识别的准确率几乎没有差别。这样的结果也再一次证明了深度学习算法在图像识别方面的一骑绝尘。
杰弗里·埃弗里斯特·辛顿(Geoffrey Everest Hinton),计算机学家、心理学家,被称为“神经网络之父”、“深度学习鼻祖”。他研究了使用神经网络进行机器学习、记忆、感知和符号处理的方法,并在这些领域发表了超过200篇论文。他是将(Backpropagation)反向传播算法引入多层神经网络训练的学者之一,他还联合发明了波尔兹曼机(Boltzmann machine)。他对于神经网络的其它贡献包括:分散表示(distributed representation)、时延神经网络、专家混合系统(mixtures of experts)、亥姆霍兹机(Helmholtz machines)等。
1970年,Hinton在英国剑桥大学获得文学学士学位,主修实验心理学;1978年,他在爱丁堡大学获得哲学博士学位,主修人工智能。此后Hinton曾在萨塞克斯大学、加州大学圣迭戈分校、剑桥大学、卡内基梅隆大学和伦敦大学学院工作。2012年,Hinton获得了加拿大基廉奖(Killam Prizes,有“加拿大诺贝尔奖”之称的国家最高科学奖)。Hinton是机器学习领域的加拿大首席学者,是加拿大高等研究院赞助的“神经计算和自适应感知”项目的领导者,是盖茨比计算神经科学中心的创始人,目前担任多伦多大学计算机科学系教授。
残差网络(ResNet)是由来自Microsoft Research的4位学者,分别是Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun提出的卷积神经网络,在2015年的ImageNet大规模视觉识别竞赛(ImageNet Large Scale Visual Recognition Challenge, ILSVRC)中获得了图像分类和物体识别的优胜。残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。
残差网络的主要提出者何凯明,2003年广东省理科高考状元,曾就读于清华基础科学班并在香港中文大学攻读研究生。2011年获得博士学位后加入曾在微软亚洲研究院(MSRA)工作。他的主要研究方向是计算机视觉和深度学习。目前就职于Facebook AI Research(FAIR)
他的论文Deep Residual Networks(ResNets)是2019年Google Scholar Metrics中所有领域中被引用最多的论文。ResNets的应用还包括语言、语音和AlphaGo。
TensorFlow是一个基于数据流编程(dataflow programming)的符号数学系统,被广泛应用于各类机器学习(machine learning)算法的编程实现,其前身是谷歌的神经网络算法库DistBelief。自2015年11月9日起,TensorFlow依据阿帕奇授权协议(Apache 2.0 open source license)开放源代码。TensorFlow拥有多层级结构,可部署于各类服务器、PC终端和网页并支持GPU和TPU高性能数值计算,被广泛应用于谷歌内部的产品开发和各领域的科学研究。TensorFlow由谷歌人工智能团队谷歌大脑(Google Brain)开发和维护,拥有包括TensorFlow Hub、TensorFlow Lite、TensorFlow Research Cloud在内的多个项目以及各类应用程序接口(Application Programming Interface, API)。
TensorFlow的 Tensor(张量)表示无限的数据,Flow表示节点,流程和处理。就如同神经信号在大脑内纵横驰骋,TensorFlow模拟了一个人造的大脑。TensorFlow内核定义了一系列的深度学习方法:卷积神经网络,使用 GPU 的反向传播算法,交叉熵。神经网络的每一层都可以映射到一个或者多个方法,方便扩展其它深度学习算法,同时架构适合在高性能计算机系统中工作,和底层的具体计算机硬件无关。
TensorFlow可以利用一个长短期记忆神经网络将输入序列映射到多维序列,同时使用另一个长短期记忆神经网络从多维序列中生成输出序列。想象一下,如果输入序列是英文,输出序列是中文,TensorFlow就组成了一个智能翻译系统;如果输入序列是问题,输出序列是答案,TensorFlow就组成了一个Siri;如果输入序列是图片,输出序列是文字,TensorFlow就组成了一个图片识别系统。还有很多种如果,让TensorFlow有了无限的可能。
OpenAI,由诸多硅谷大亨联合建立的人工智能非营利组织。2015年马斯克与其他硅谷科技大亨进行连续对话后,决定共同创建OpenAI,希望能够预防人工智能的灾难性影响,推动人工智能发挥积极作用。特斯拉电动汽车公司与美国太空技术探索公司SpaceX创始人马斯克、Y Combinator总裁阿尔特曼、天使投资人彼得·泰尔(Peter Thiel)以及其他硅谷巨头2014年12月份承诺向OpenAI注资10亿美元。
OpenAI的使命是确保通用人工智能 (Artificial General Intelligence, AGI),即一种高度自主且在大多数具有经济价值的工作上超越人类的系统,将为全人类带来福祉。不仅希望直接建造出安全的、符合共同利益的通用人工智能,而且愿意帮助其它研究机构共同建造出这样的通用人工智能以达成他们的使命。
索菲亚是由中国香港的汉森机器人技术公司(Hanson Robotics)开发的类人机器人,是历史上首个获得公民身份的一台机器人。索菲亚看起来就像人类女性,拥有橡胶皮肤,能够表现出超过62种面部表情。索菲亚“大脑”中的计算机算法能够识别面部,并与人进行眼神接触。
2016年3月,在机器人设计师戴维·汉森(David Hanson)的测试中,与人类极为相似的人类机器人索菲亚(Sophia)自曝愿望,称想去上学,成立家庭。索菲亚看起来就像人类女性,拥 有橡胶皮肤,能够使用很多自然的面部表情。索菲亚“大脑”中的计算机算法能够识别面部,并与人进行眼神接触。索菲亚的皮肤使用名为Frubber的延展性 材料制作,下面有很多电机,让它可以做出微笑等动作。此外,索菲亚还能理解语言和记住与人类的互动,包括面部。随着时间推移,它会变得越来越聪明。汉森说:“它的目标就是像任何人类那样,拥有同样的意识、创造性和其他能力。
2017年10月26日,沙特阿拉伯授予香港汉森机器人公司生产的机器人索菲亚公民身份。作为史上首个获得公民身份的机器人,索菲亚当天在沙特说,它希望用人工智能“帮助人类过上更美好的生活”,人类不用害怕机器人,“你们对我好,我也会对你们好”。
阿尔法围棋(AlphaGo)是一款围棋人工智能程序。其主要工作原理是“深度学习”。“深度学习”是指多层的人工神经网络和训练它的方法。一层神经网络会把大量矩阵数字作为输入,通过非线性激活方法取权重,再产生另一个数据集合作为输出。这就像生物神经大脑的工作机理一样,通过合适的矩阵数量,多层组织链接一起,形成神经网络“大脑”进行精准复杂的处理,就像人们识别物体标注图片一样。它第一个击败人类职业围棋选手、第一个战胜围棋世界冠军的人工智能机器人,由谷歌(Google)旗下DeepMind公司戴密斯·哈萨比斯领衔的团队开发。其主要工作原理是“深度学习”。
2016年3月,AlphaGo与围棋世界冠军、职业九段棋手李世石进行围棋人机大战,以4比1的总比分获胜;2016年末2017年初,该程序在中国棋类网站上以“大师”(Master)为注册账号与中日韩数十位围棋高手进行快棋对决,连续60局无一败绩;2017年5月,在中国乌镇围棋峰会上,它与排名世界第一的世界围棋冠军柯洁对战,以3比0的总比分获胜。围棋界公认阿尔法围棋的棋力已经超过人类职业围棋顶尖水平,在GoRatings网站公布的世界职业围棋排名中,其等级分曾超过排名人类第一的棋手柯洁。
2017年5月27日,在柯洁与阿尔法围棋的人机大战之后,阿尔法围棋团队宣布阿尔法围棋将不再参加围棋比赛。2017年10月18日,DeepMind团队公布了最强版阿尔法围棋,代号AlphaGo Zero。
旧版的AlphaGo主要由几个部分组成:一、策略网络(Policy Network),给定当前局面,预测并采样下一步的走棋;二、快速走子(Fast rollout),目标和策略网络一样,但在适当牺牲走棋质量的条件下,速度要比策略网络快1000倍;三、价值网络(Value Network),给定当前局面,估计是白胜概率大还是黑胜概率大;四、蒙特卡洛树搜索(Monte Carlo Tree Search),把以上这四个部分连起来,形成一个完整的系统。阿尔法围棋(AlphaGo)是通过两个不同神经网络“大脑”合作来改进下棋。这些“大脑”是多层神经网络,跟那些Google图片搜索引擎识别图片在结构上是相似的。它们从多层启发式二维过滤器开始,去处理围棋棋盘的定位,就像图片分类器网络处理图片一样。经过过滤,13个完全连接的神经网络层产生对它们看到的局面判断。这些层能够做分类和逻辑推理。
新版的AlphaGo名为AlphaGo Zero在此前的版本的基础上,结合了数百万人类围棋专家的棋谱,以及强化学习进行了自我训练。它与旧版最大的区别是,它不再需要人类数据。也就是说,它一开始就没有接触过人类棋谱。研发团队只是让它自由随意地在棋盘上下棋,然后进行自我博弈。
据阿尔法围棋团队负责人大卫·席尔瓦(Dave Sliver)介绍,AlphaGo Zero使用新的强化学习方法,让自己变成了老师。系统一开始甚至并不知道什么是围棋,只是从单一神经网络开始,通过神经网络强大的搜索算法,进行了自我对弈。随着自我博弈的增加,神经网络逐渐调整,提升预测下一步的能力,最终赢得比赛。更为厉害的是,随着训练的深入,阿尔法围棋团队发现,AlphaGo Zero还独立发现了游戏规则,并走出了新策略,为围棋这项古老游戏带来了新的见解。
AlphaGo Zero仅用了单一的神经网络。在此前的版本中,AlphaGo用到了“策略网络”来选择下一步棋的走法,以及使用“价值网络”来预测每一步棋后的赢家。而在新的版本中,这两个神经网络合二为一,从而让它能得到更高效的训练和评估。同时AlphaGo Zero并不使用快速、随机的走子方法。在此前的版本中,AlphaGo用的是快速走子方法,来预测哪个玩家会从当前的局面中赢得比赛。相反,新版本依靠地是其高质量的神经网络来评估下棋的局势。
AlphaGo的主要设计者,戴密斯·哈萨比斯(Demis Hassabis),人工智能企业家,DeepMind Technologies公司创始人,人称“阿尔法围棋之父”。4岁开始下国际象棋,8岁自学编程,13岁获得国际象棋大师称号。17岁进入剑桥大学攻读计算机科学专业。在大学里,他开始学习围棋。2005年进入伦敦大学学院攻读神经科学博士,选择大脑中的海马体作为研究对象。两年后,他证明了5位因为海马体受伤而患上健忘症的病人,在畅想未来时也会面临障碍,并凭这项研究入选《科学》杂志的“年度突破奖”。2011年创办DeepMind Technologies公司,以“解决智能”为公司的终极目标。
联邦学习(又称协作学习)是一种机器学习技术, 2016 年由谷歌最先提出,它在多个持有本地数据样本的分散式边缘设备或服务器上训练算法,而不交换其数据样本。这种方法与传统的集中式机器学习技术形成鲜明对比,传统的集中式机器学习技术将所有的数据样本上传到一个服务器上,而更经典的去中心化方法则假设本地数据样本是完全相同分布的。
联邦学习能够使多个参与者在不共享数据的情况下建立一个共同的、强大的机器学习模型,从而解决数据隐私、数据安全、数据访问权限和异构数据的访问等关键问题。其应用遍布国防、电信、物联网或制药等多个行业。
联邦学习原本用于解决安卓手机终端用户在本地更新模型的问题,其设计目标是在保障大数据交换时的信息安全、保护终端数据和个人数据隐私、保证合法合规的前提下,在多参与方或多计算结点之间开展高效率的机器学习。其中,联邦学习可使用的机器学习算法不局限于神经网络,还包括随机森林等重要算法。联邦学习有望成为下一代人工智能协同算法和协作网络的基础。
BERT的全称为Bidirectional Encoder Representation from Transformers,是一个预训练的语言表征模型。BERT论文 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding于2018年发表,它强调了不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的masked language model(MLM),以致能生成深度的双向语言表征。发表时提及在11个NLP(Natural Language Processing,自然语言处理)任务中获得了新的state-of-the-art的结果,令人目瞪口呆。
该模型有以下主要优点:
1)采用MLM对双向的Transformers进行预训练,以生成深层的双向语言表征。
2)预训练后,只需要添加一个额外的输出层进行fine-tune,就可以在各种各样的下游任务中取得state-of-the-art的表现。在这过程中并不需要对BERT进行任务特定的结构修改。
BERT的本质上是通过在海量的语料的基础上运行自监督学习方法为单词学习一个好的特征表示,所谓自监督学习是指在没有人工标注的数据上运行的监督学习。在以后特定的NLP任务中,我们可以直接使用BERT的特征表示作为该任务的词嵌入特征。所以BERT提供的是一个供其它任务迁移学习的模型,该模型可以根据任务微调或者固定之后作为特征提取器。BERT的源码和模型2018年10月31号已经在Github上开源,简体中文和多语言模型也于11月3号开源。
人工智能,未来已来。2015年,张钹院士提出第三代人工智能体系的雏形。2017 年,美国国防高级研究计划局(DARPA) 发起 XAI 项目,核心思想是从可解释的机器学习系统、人机交互技术以及可解释的心理学理论3个方面,全面开展可解释性 AI 系统的研究。自2017年开始,人工智能连续三年被列入政府工作报告中。
2019年,人工智能行业彻底告别了“喊口号”“包装概念”的时代,步入稳步发展的轨道。人工智能的技术和应用开始在各个行业落地,人工智能的成果和场景实践层出不穷。例如NVDIA 开源的 StyleGAN、谷歌量子霸权论文正式登上Nature、波士顿动力机器狗Spot即将商用、阿里推出了这款全球最强的 AI芯片——含光800、AI换脸、AI“人脸识别”协助警方等等。这些大事件都表明人工智能技术已经越来越“接地气”,进入到人们的生活中,而不是停留在研究和实验当中。人工智能被正式列入新增审批本科专业名单。
2020年,在全球抗击疫情的背景下,当人与人之间的交往受到限制的时候,人工智能被赋予了更多期待和重任。它在信息收集、数据汇总及实时更新、流行病调查、疫苗药物研发、新型基础设施建设等领域大显身手。与此同时,随着新技术新业态的不断涌现,人工智能凝聚全球智慧、助力全球经济复苏的力量更加凸显。
2020年3月4日,中央明确指示要加快推进国家规划已明确的重大工程和基础设施建设,人工智能被列入新基建范畴,它将是新一轮产业变革的核心驱动力,重构生产、分配、交换、消费等经济活动各环节,催生新技术、新产品、新产业。
2020年8月5日、国家标准化管理委员会、中央网信办、国家发展改革委、科技部、工业和信息化部,五部门联合印发《国家新一代人工智能标准体系建设指南》,指南中,提出了具体的国家新一代人工智能标准体系建设思路、建设内容,并附上了人工智能标准研制方向明细表,在国家层面进一步规范了人工智能的应用体系,明确了其发展方向。
未来是属于人工智能的。人工智能将会融入我们每个人的生活,变得无处不在。任何技术的发展都是有高峰和低谷,人工智能的发展也一样。因此我们在保持乐观态度的同时,也有保留理智。不过分夸大其作用,盲目从众,而是正确引导,稳步发展。真正将人工智能的长处发挥出来,改善人类生活,助力经济发展。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















