















































软件

产品


主要记录一下最近NX的使用以及部署NX的辛酸过程。 . p t − > . o n n x − > . e n g i n e − > D e e p s t r e a m .pt->.onnx->.engine-> Deepstream .pt−>.onnx−>.engine−>Deepstream
相比于Jetson nano,拥有更高的算力。并且实验室刚好有一块闲置的Jetson NX。并且,Jetson NX支持INT8的浮点计算,Jetson nano只支持float16的浮点计算。
下面是一些Jetson系列的对比图
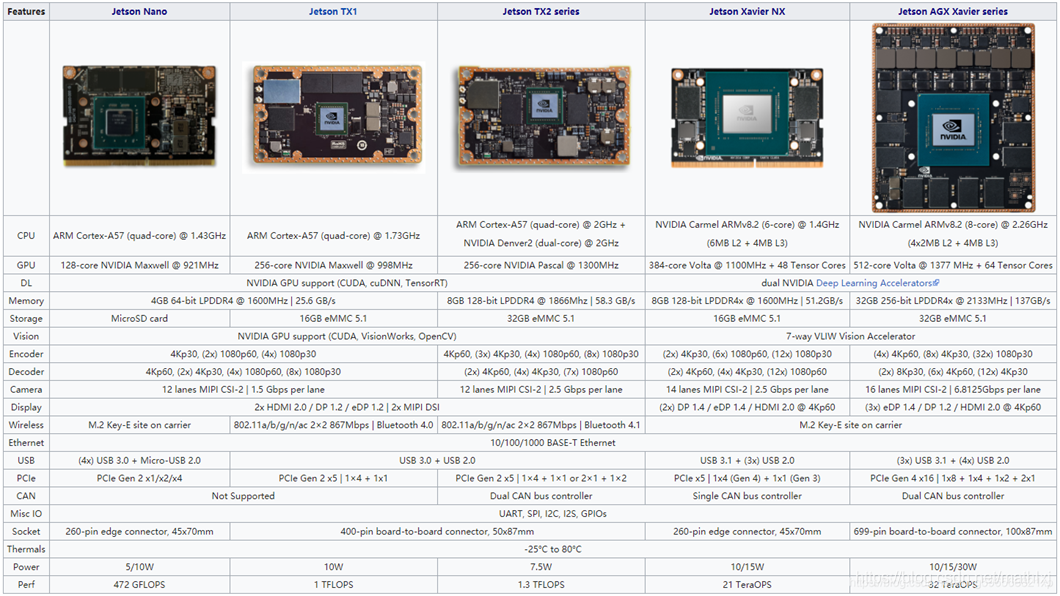
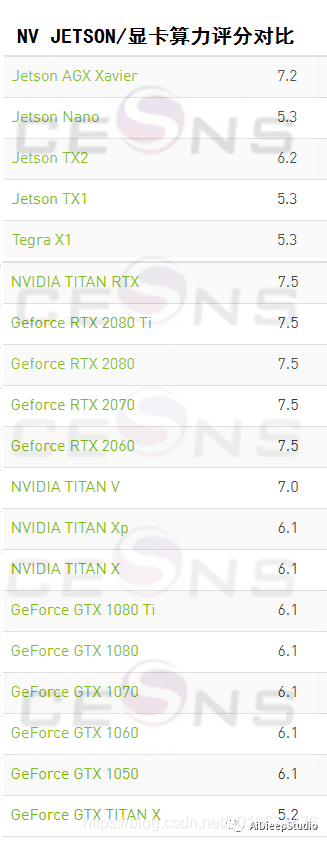

我是用学长配置好的NX,并不是自己配置的,所以一开始没有自己去镜像烧录。
个人建议直接去NVIDIA上找教程,然后进行镜像烧录。
区别大了,呜呜。环境配置完全不一样,不一样就算了,还很难配。
部署是模型落地的最后一步,也是最重要的一环。
模型部署,听上去很高大上,但是实际上就是把深度学习的算法在开发板上运行起来。至于深度学习的模型,你管它是.pt,.pth,.onnx,.engine啥的,只要run起来就算部署了。
那么问题来了,为什么会出现那么多模型推理框架呢?
因为移动端(开发板)的算力有限,模型推理转化就是为了让模型更加轻量(运行推理的更快)
推理较为简单的推理方法多是各大厂商为了适配自己的产品推出的,如Intel的OpenVINO、ARM的ARM NN、Nvidia的TensorRT,腾讯的NCNN等。
TVM:带来的加速效果非常的可观,对硬件的支持非常宽泛, 但是对新手不友好, 需要熟练掌握算法输入输出结构,并且熟知TVM API函数的情况下,可以使用TVM对算法进行加速,否则项目周期会变得不可控. OpenVino(Intel):对新手友好,但对部署的硬件有一定的要求,如果算法可以在intel-cpu、神经网络加速棒(Stick 2)上部署,那么OpenVino是一个不错选择. TNN:对新手友好,单纯使用TNN加速带来的加速效果一般,可以按照TNN的文档对算法进行一次优化;在编译时可以选择openvino、TensorRT编译选项,对硬件的支持就宽泛. NCNN:加速PC端加速效果并不理想,手机端的使用比较多一些
但这些框架在实际应用场景中会遇到不少问题:
因此,一套可以让我们在任意硬件上高效运行任意模型的统一框架就显得尤其有价值。
而TVM正是这样一套框架。但是可能是我孤陋寡闻,没怎么听说TVM。
TVM:深度学习模型编译框架TVM概述 - 知乎 (zhihu.com)
ONNX(Open Neural Network Exchange )还是听过的吧,一个开放的生态系统,是一种深度模型的开放格式,它使 AI 开发人员能够随着项目的发展选择合适的工具,增强模型的交互性。ONNX 得到广泛支持,可以在许多框架、工具和硬件中找到,实现不同框架之间的互操作性并简化从研究到生产的路径,也就是说不同框架(TensorFlow/Pytorch/Paddle)训练出来的模型都可以转换成onnx模型进行存储以后后续的推理。
ONNX可以用来做为推理转化的中间桥梁。
使用Jetson NX,当然使用自家的TensorRT推理。
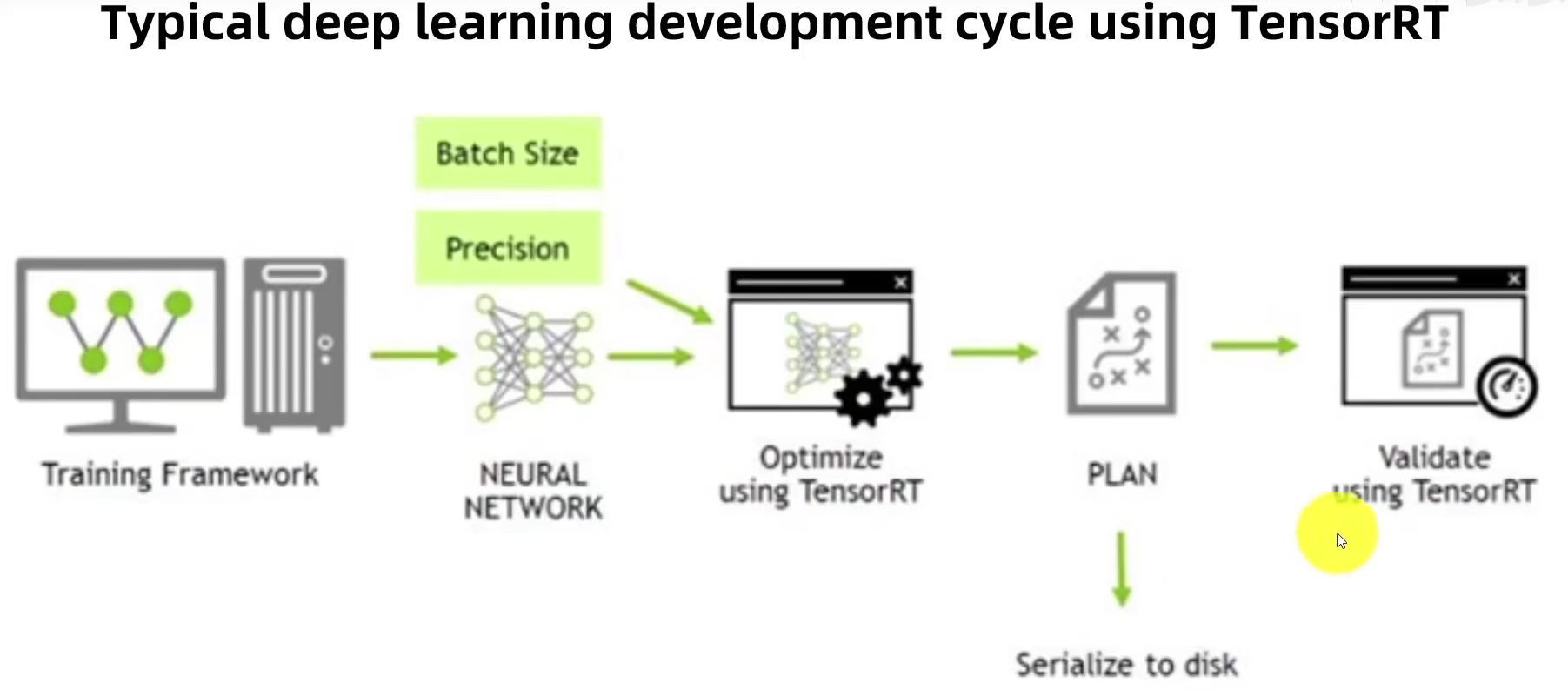
TensorRT有如下五个功能:
图1.TensorRT 的垂直和水平层融合和层消除优化简化了 GoogLeNet Inception 模块图,减少了计算和内存开销。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LuC5ow4h-1650705963190)(C:\Users\BlackFriday\AppData\Roaming\Typora\typora-user-images\image-20211125123422839.png)]
听着是不是很懵逼,啥序列化,反序列化。反正我当时人都看麻了。 要花钱买的视频:YOLOv5的Jetson Nano部署 - 网易云课堂 (163.com)
通过一番探索,一共发现三种方式:
直接根据TensorRT官方 GitHub 教程wang-xinyu/tensorrtx: Implementation of popular deep learning networks with TensorRT network definition API (github.com)来,注意版本对应。通过查看,我发现在转成.engine的过程中,是采用源码编译的方式进行,也就是说需要相关的网络结构文件。重点是要C++的网络结构文件,通过.wts进行cmake生成,这我就麻了啊,我用的是别人改进的YOLOV5-Lite,根本没有相关的C++文件。
运气不错,通过搜索,发现竟然有好几种转.engine的方式,其中一种就是通过Jetson自带的trtexec可以把.onnx转化为.engine。
git clone https://github.com/ppogg/YOLOv5-Lite.git
python models/export.py --weights weights/yolov5-lite.pt --img 640 --batch 1
python -m onnxsim weights/yolov5-lite.onnx weights/yolov5-lite-sim.onnx
/usr/src/tensorrt/bin/trtexec --onnx=input.onnx --saveEngine=out.engine --fp16 --workspace=1024
参数含义: /usr/src/tensorrt/bin/trtexec: 你的tensorrt的地址 –onnx: 需要转换的onnx模型路径 –saveEngine: 保存的模型地址名称 –fp16: 保存出的模型的精度 –workspace: 运行空间大小(貌似没卵用)
结果转化成功了,好耶ヾ(✿゚▽゚)ノ。
然后就开始找要怎么运行.engine文件。最终在TensorRT的 yolov5 仓库中发现了yolov_trt.py,但是运行这个文件需要.engine以及.io文件,但是采用法二似乎没有生成什么.so的编译文件,通过cmake得到的还会生成.so文件。。。不是很懂。
参考:
(101条消息) onnx 转 trt 并使用trt模型推理_嘿,不许笑的博客-CSDN博客_onnx模型转trt 复制的文档:(101条消息) TensorRT trtexec的用法说明_冬日and暖阳的博客-CSDN博客_trtexec
也就是我在愁的时候,发现还有 Deepstream 这个东东,这个是NVIDIM研发的SDK,用于构建智能的视频流读取,建立深度学习部署的pipline。
是通过配置一个对应的txt文件运行。打算尝试一下,后面发现还是需要.so动态编译库,寄!
考虑到Deepstream的部署也需要make,所以打算使用Yolov5s,于是进行\remake。通过配置Deepstream的过程,发现Deepstream也可以自动生成.engine
这真是一个让你又爱又恨的玩意儿呢。。。
建议先找一个别人写的教程,然后配合官网教程(主)使用。
Quickstart Guide — DeepStream 6.0 Release documentation (nvidia.com)
一定要注意好对应的版本环境!!!!!!
升级JetPack的教程,官网上也有:(101条消息) NVIDIA Jetson Xavier NX升级JetPack 4.4至4.6.1_jch_wang的博客-CSDN博客
Deepstream有相关的example,可以尝试运行一下。
通过Deepstream运行Yolov5,可以直接搜索,找相关的教程以及GitHub仓库。
一定要注意好对应的版本环境:
Deepstream是C++,那么我们怎么通过模型与完成相关的后续任务呢?
Deepstream5.0之后就实现的Python的接口编写:
运行这些example也需要环境配置(具体看官网),该仓库实现了许多Deepstream进行目标检测的Python example,在他们的基础上进行修改。
deepstream-test1 – 4-class object detection pipeline deepstream-test2 – 4-class object detection, tracking and attribute classification pipeline deepstream-test3 – multi-stream pipeline performing 4-class object detection deepstream-test4 – msgbroker for sending analytics results to the cloud deepstream-imagedata-multistream – multi-stream pipeline with access to image buffers deepstream-ssd-parser – SSD model inference via Triton server with output parsing in Python deepstream-test1-usbcam – deepstream-test1 pipelien with USB camera input deepstream-test1-rtsp-out – deepstream-test1 pipeline with RTSP output deepstream-opticalflow – optical flow and visualization pipeline with flow vectors returned in NumPy array deepstream-segmentation – segmentation and visualization pipeline with segmentation mask returned in NumPy array deepstream-nvdsanalytics – multistream pipeline with analytics plugin runtime_source_add_delete – add/delete source streams at runtime deepstream-imagedata-multistream-redaction – multi-stream pipeline with face detection and redaction deepstream-rtsp-in-rtsp-out – multi-stream pipeline with RTSP input/output
使用NVIDIA自带的检测模型以及跟踪模型NvDCF同时跑四路视频(一帧感觉会卡0.5s),跑一路视频(摄像头)可以达到实时检测的效果。

免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















