















































软件

产品


****📚HR-Depth, 一种高分率的 自监督 单目深度估计,重新设计DepthNet 的跳接层获取更好的高分辨特征,提出了特征融合压缩抽取方法Squeezeand-Excitation(fSE)高效融合特征。(from 浙大 网易伏羲)
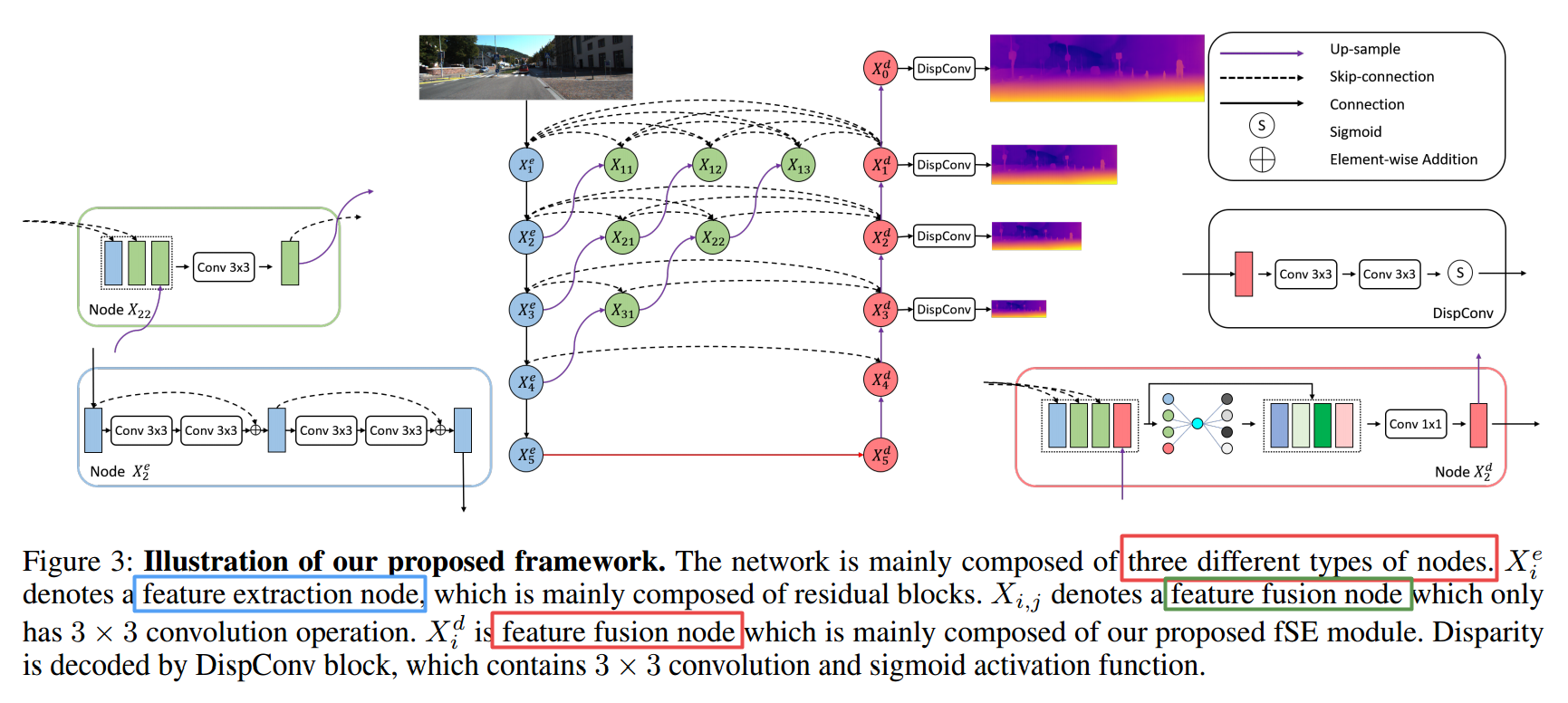
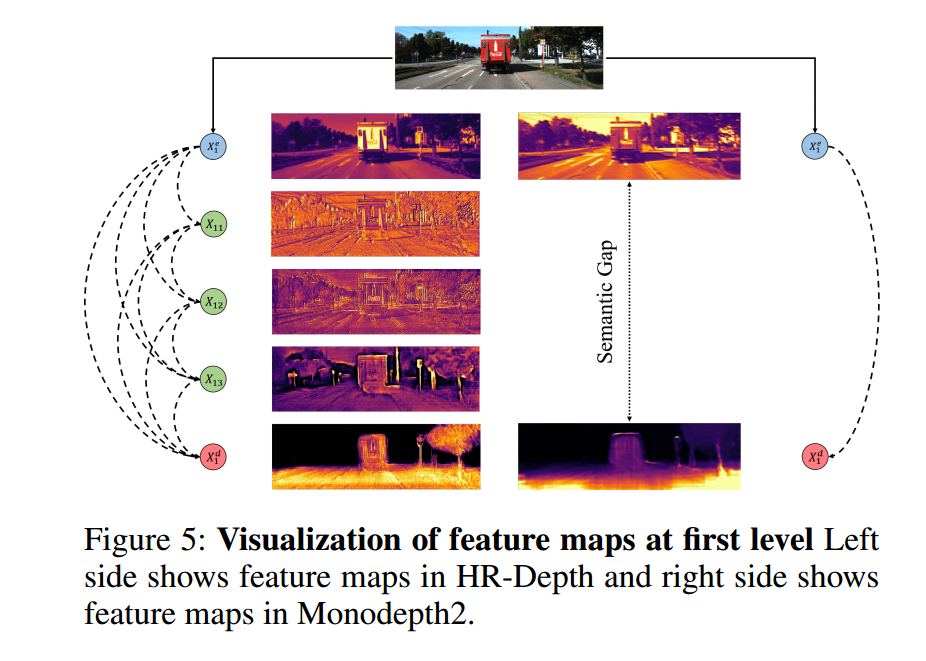
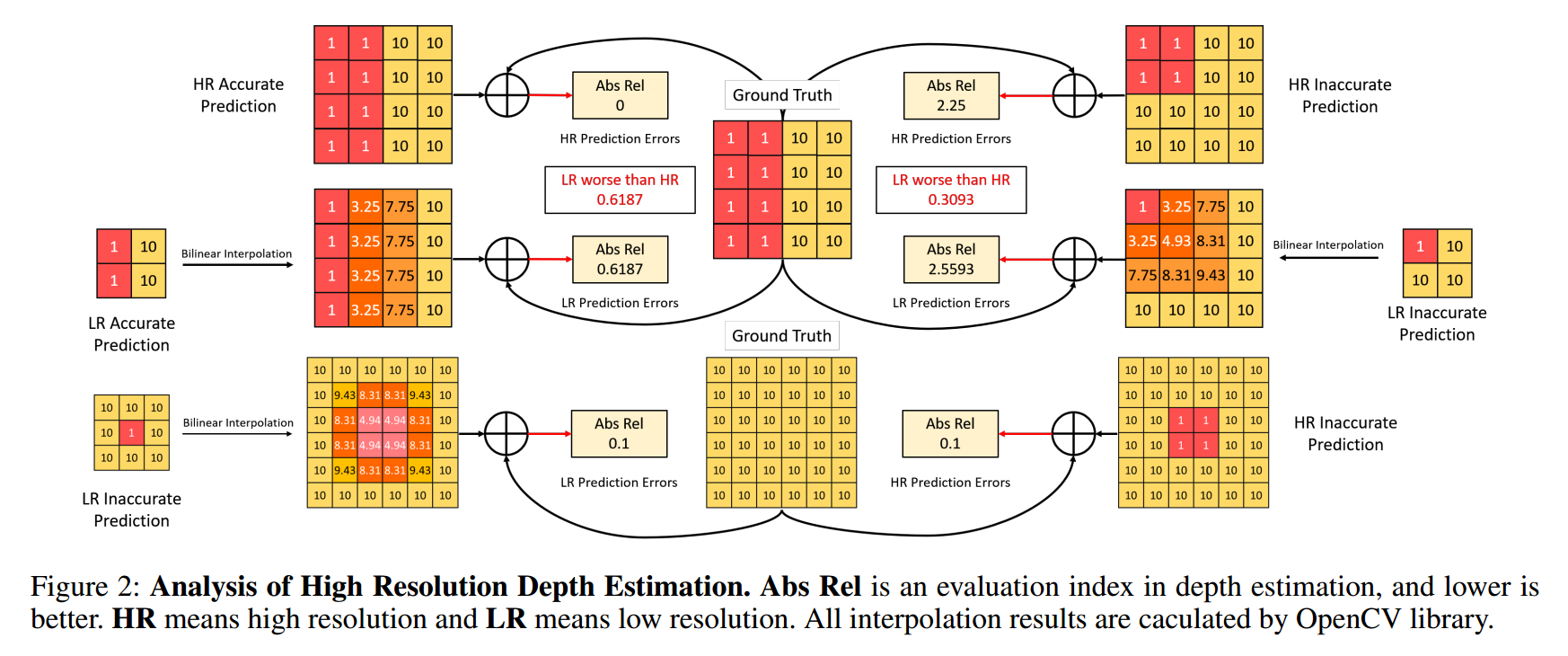
code:https://github.com/shawLyu/HR-Depth
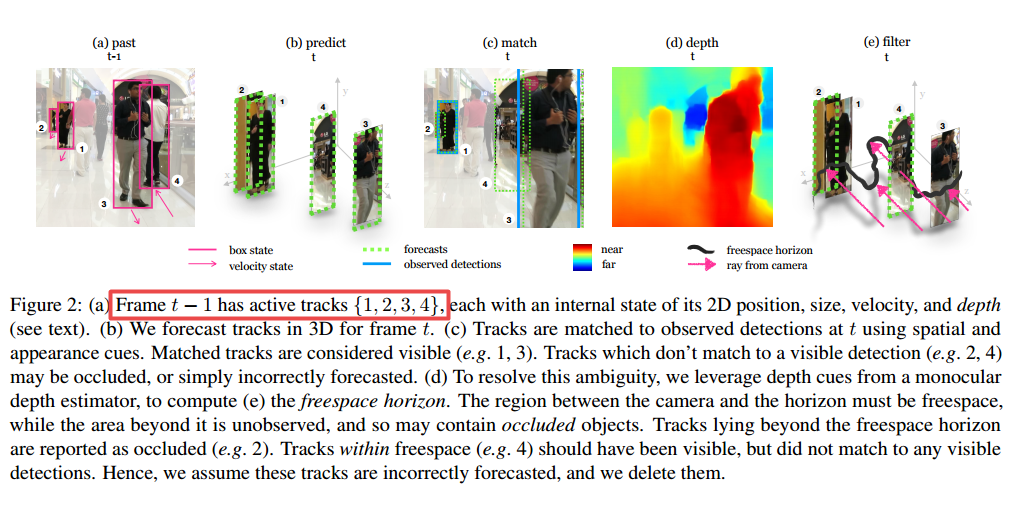
****📚Detecting Invisible People, 利用短时时序预测和动力学3D模型实现有部分遮挡或暂时遮挡的行人重识别(from CMU argo AI)。

****📚Point Transformer用于电云处理的自注意力网络, 构建了用于点云处理的自注意力层(from 牛津 港中文 intel)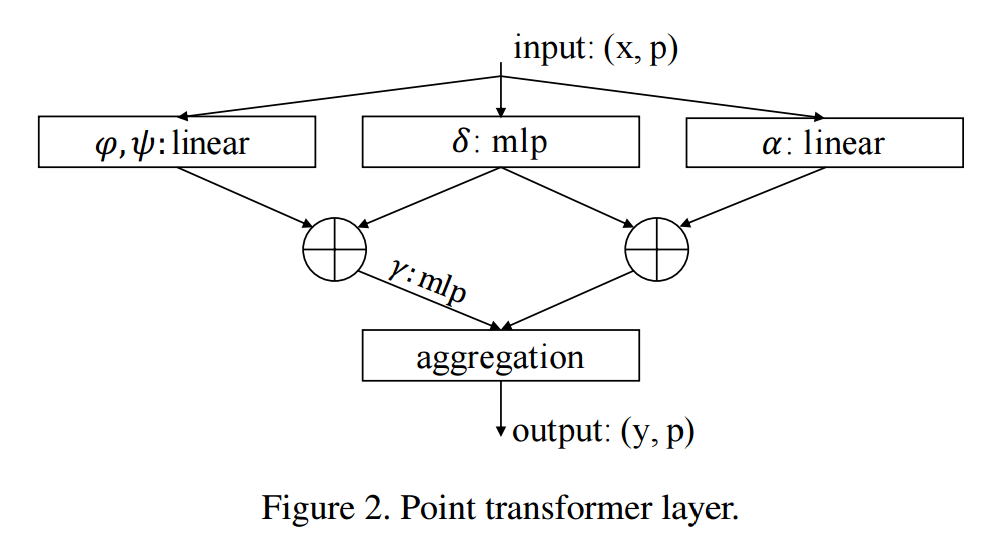
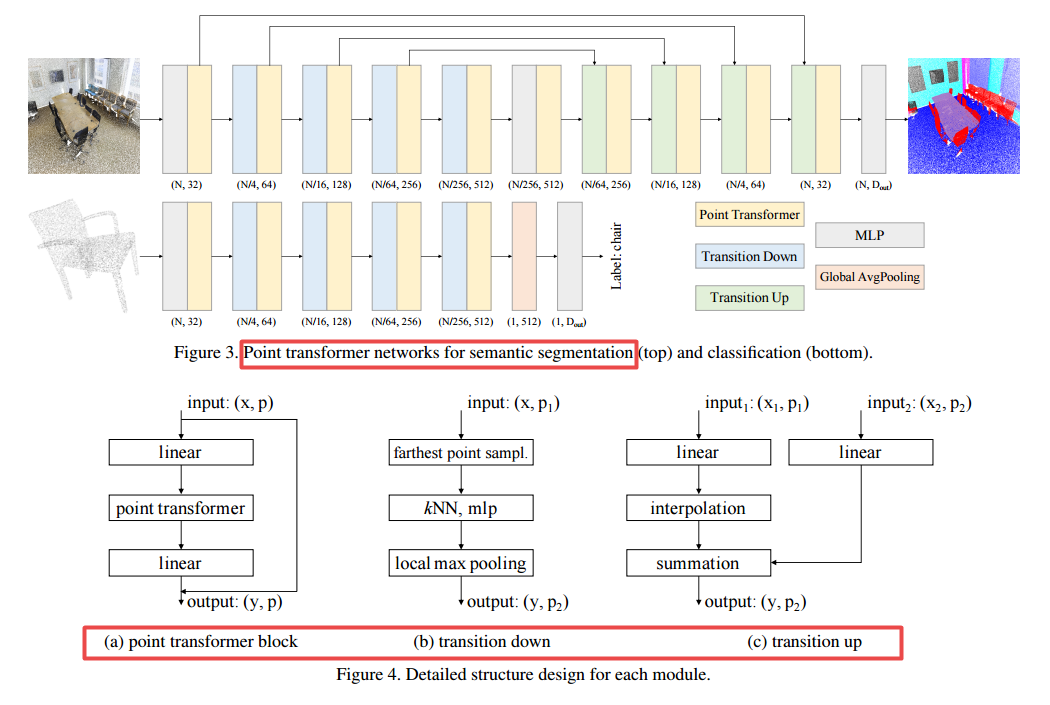
dataset:S3DIS dataset 3D semantic parsing of large-scale indoor spaces
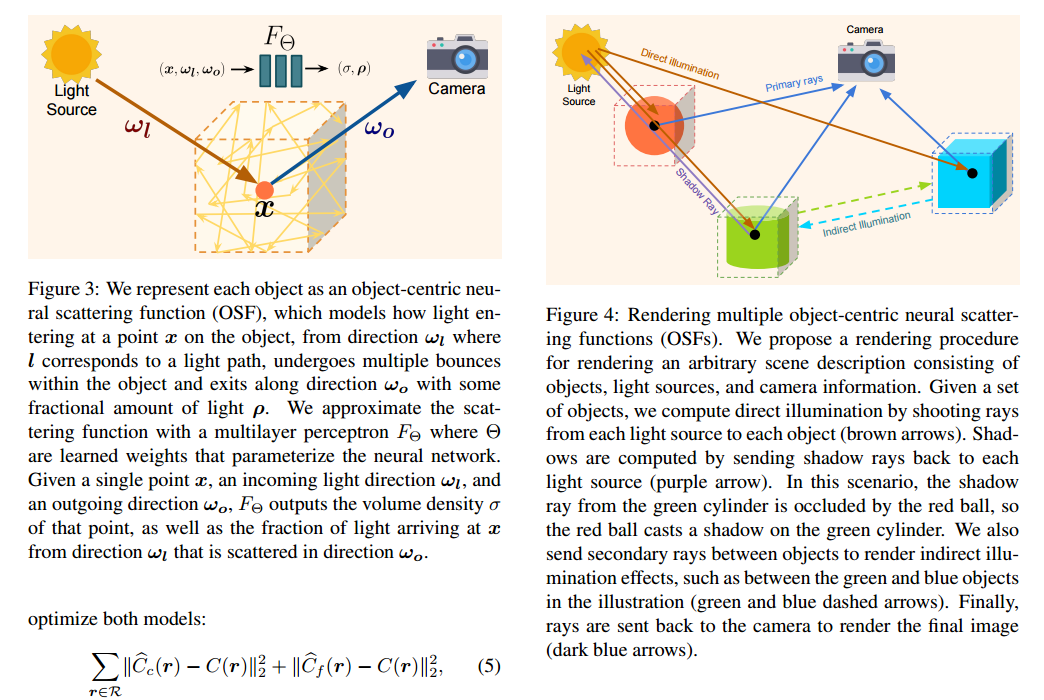
****📚基于目标为中心的神经渲染, (from 斯坦福 谷歌 )
***📚基于视觉上下文的几何结构提升算法, 可以基于视觉特征恢复出扫描GT中缺失的结果。(from 特拉维夫大学)
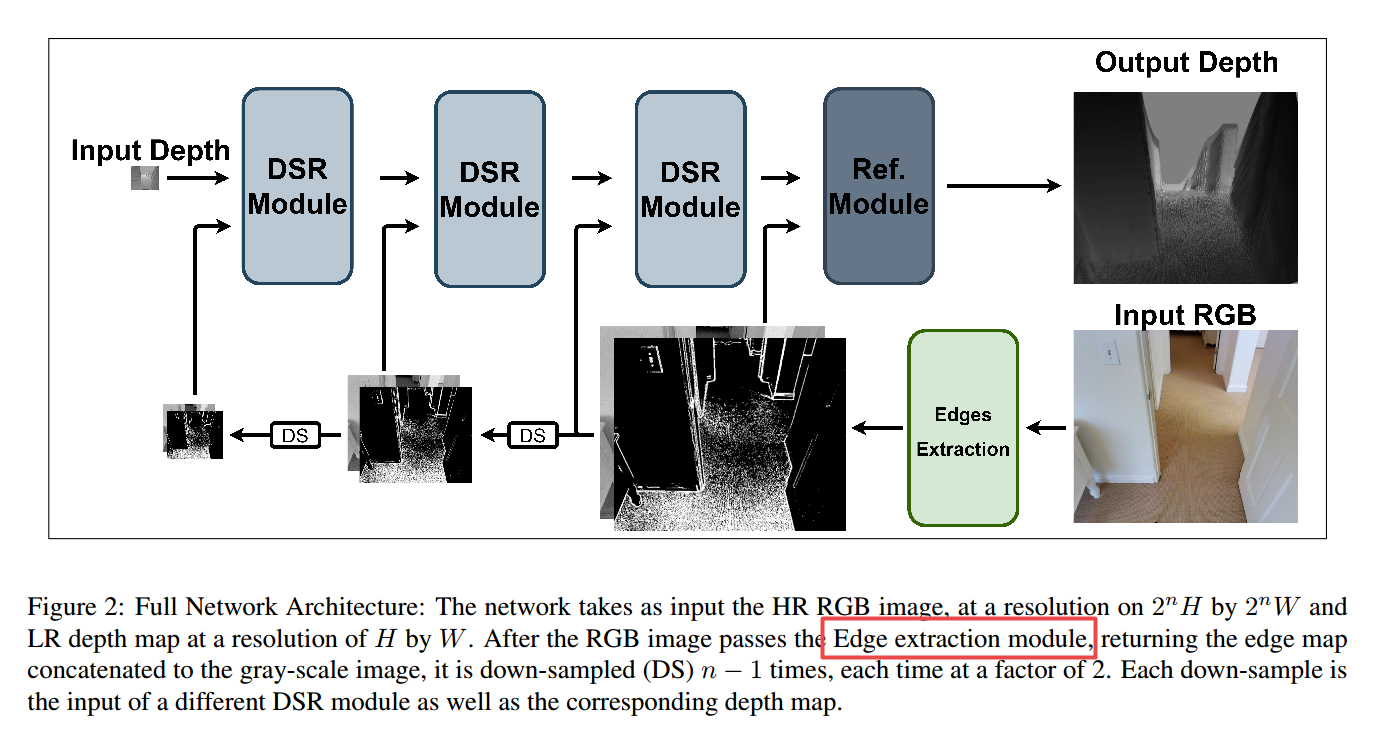
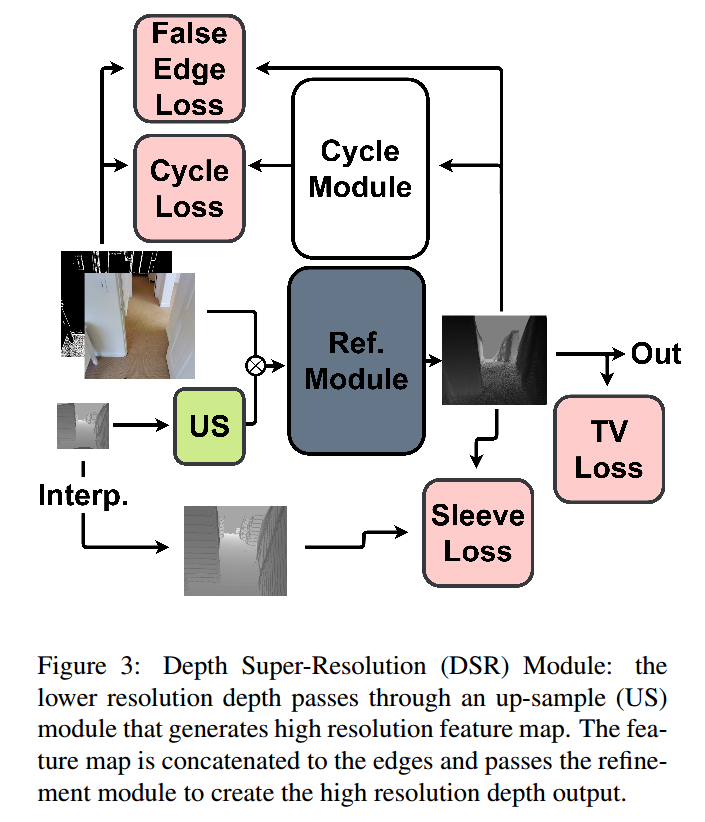
***📚基于上下文的高数据效率三维理解, 有限数据标注下实现3D 实例分割 模型训练。(from TUM 和Facebook AI)


dataset:ScanNet-LA Scannet: Richly-annotated 3D reconstructions of indoor scenes
torchapi
**📚基于图像的手绘草图生成,基于矢量流和绘图图像进行处理的操作生成算法。 (from 上交 华为)
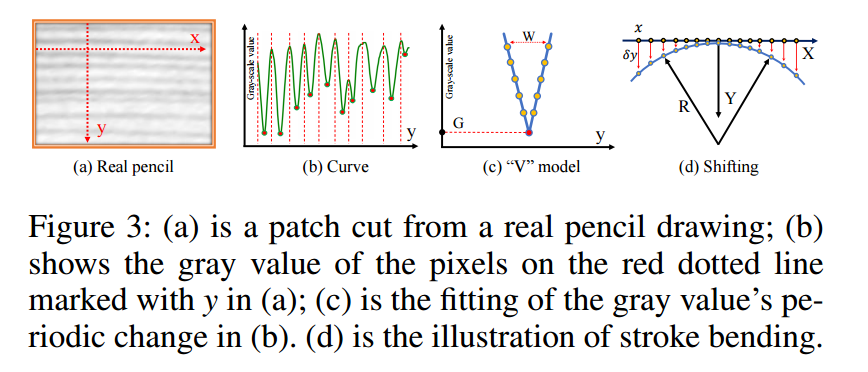
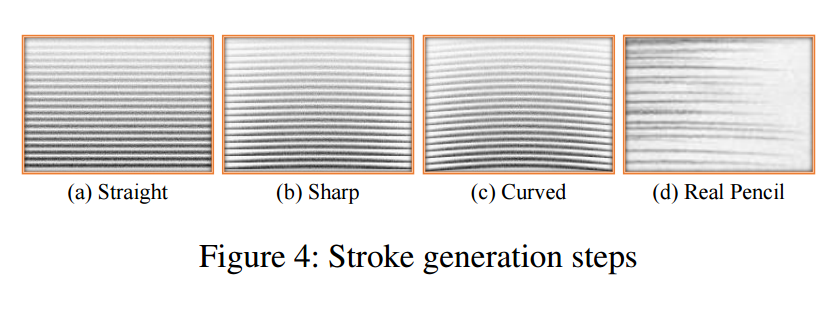
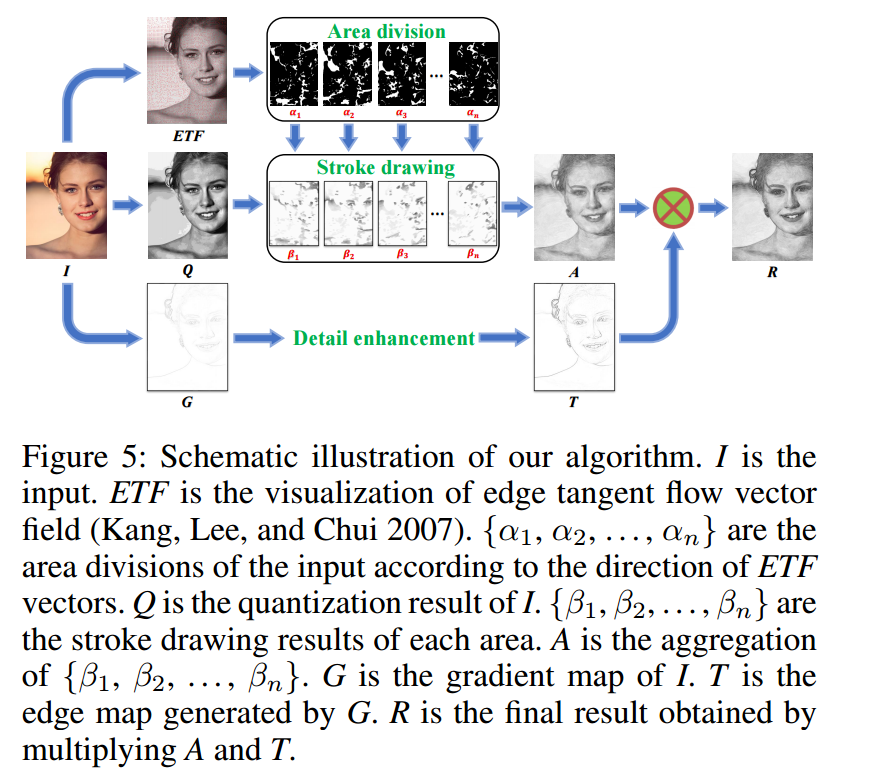
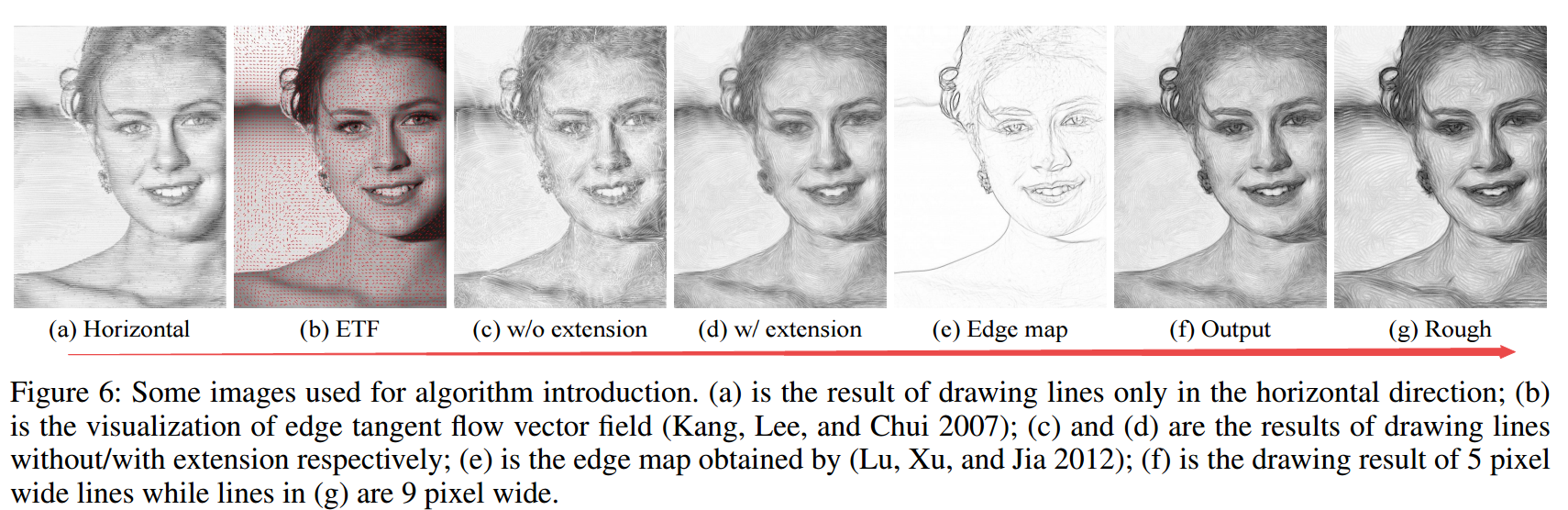

code:https://github.com/TZYSJTU/Sketch-Generation-with-Drawing-Process-Guided-by-Vector-Flow-and-Grayscale
***📚NAPA, 将人体位姿估计问题转换为了风格迁移与自监督问题。(from 纽约大学)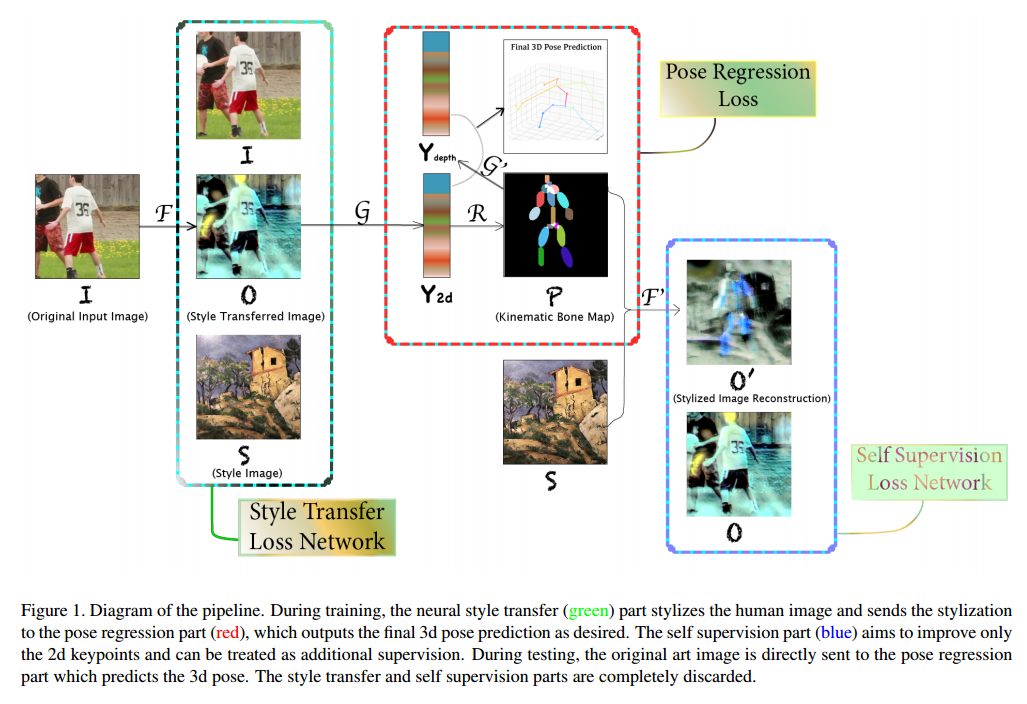
code:https://github.com/
***📚扣图技术, 基于用户点击与不确定性估计的抠图质量提升算法。(from 中科大 微软 香港城市大学)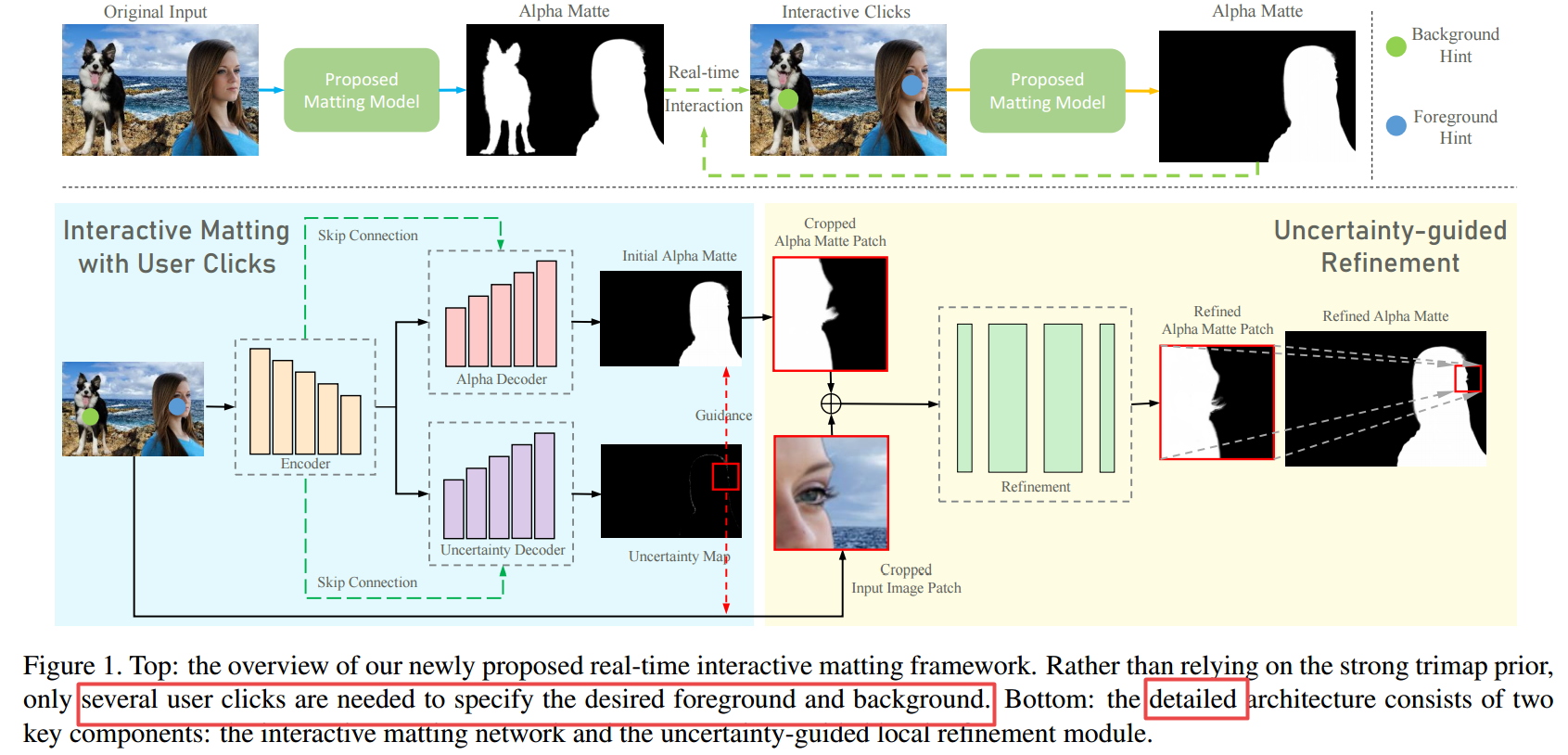

code:https://youtu.be/pAXydeN-LpQ
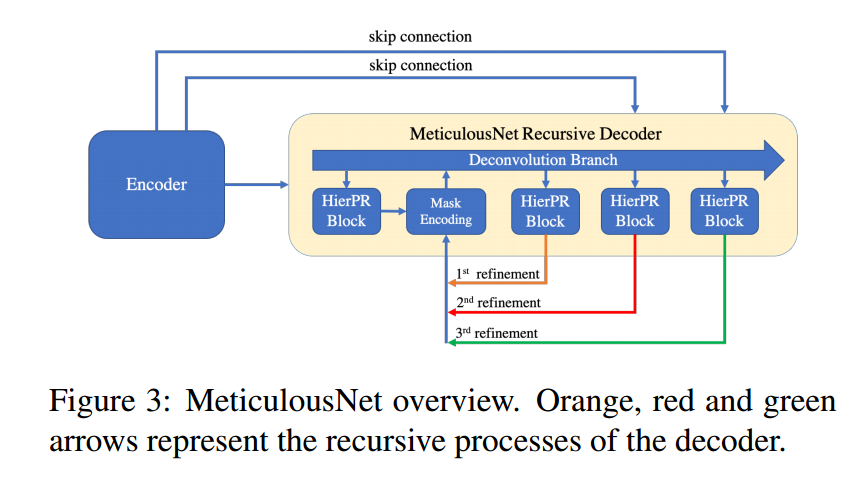
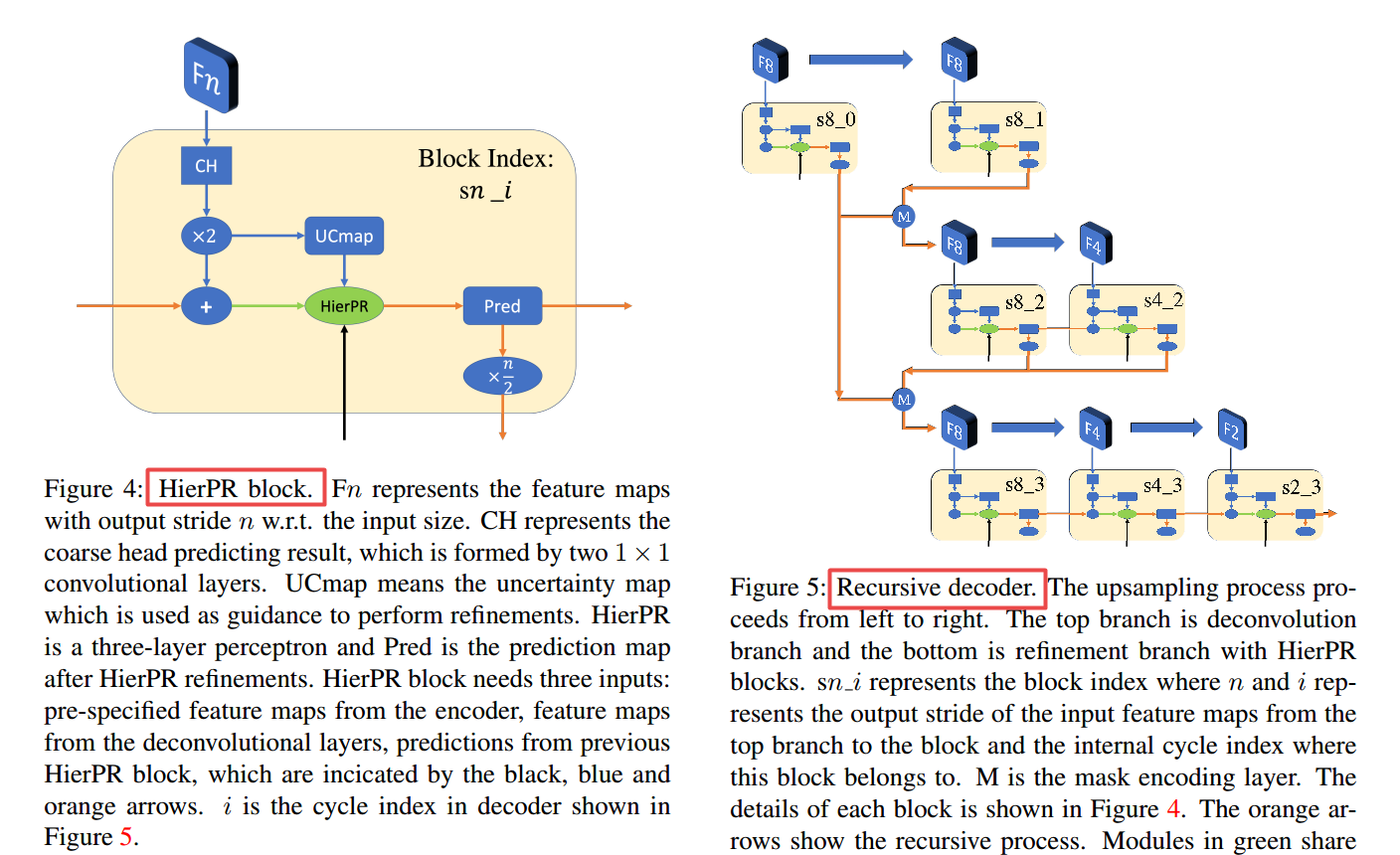
***📚MeticulousNet,抠图分割算法(from 约翰霍普金斯 adobe )
📚FSCOCO方程式赛车中公路桩识别数据集, (from LMU Munich Deggendorf Institute of Technology ETH Zurich )

ref: roborace.com formulastudent.de supervise.ly

img from pexels.com
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















