一.杂论
1.1 训练集,验证集,测试集的区别
- 训练集:利用标签不断的进行网络参数(权重)的更新,但是每次训练都有一定的训练参数(学习率等)
- 验证集:用来选择训练集中最好的训练参数(学习率等)
- 测试集:用来真实的评价模型或者参数的结果
1.2 max函数的梯度:
1.3 卷积维度的计算:
- 卷积输出的维度=(输入维度+增补维度-卷积核维度)/步幅+1
1.4 硬件使用
- CPU
核数较少,但运算很快,操作数很多,并且可以单独运行,适合做通信处理。
- GPU
核数很多,但运算慢,操作有限,不能单独运行,适合进行高度并行的处理(矩阵运算)
- FPGA:可编程门阵列.
- ASIC:特定用途集成电路
- 框架tensorflow,pytorch:更加的简便,同时能够更好的贴合硬件的结构
1.5全连接模块
1.6 上采样与去池化
1.7 跨卷积与反向跨卷积
- 跨卷积:调整卷积核的步幅
- 反向跨卷积:将卷积得到的结果再乘上卷积核,并移动一定的步长(相乘结果)
- 两者可以使用步长比来命名
1.8 目标函数
- 将最终的目标作为目标函数可以更加有效的得到对应的结果
1.9 忽略细节
- 不准确的说,人们往往只知道某项技术可以达到怎样的功能,但是产生这样效果的原因却尚未没解开
1.10 减小模型复杂度
- 剪枝:
(1)降低模型的复杂度
(2)防止过拟合
(3)先训练神经网络,再去除连接,再训练。
- 权值共享:对一些接近的权值,使用一个近似进行表示,学习
- 哈夫曼编码: 对于出现频率高的数字要用简单的表示,反之亦然
- SqueezeNet:在卷积之前,使用一个1*1的卷积核来缩小通道计算开销
- 低秩近似:
(1)把一个卷积核分解成多个
(2)可以提高模型的非线性表示能力
- 二元或三元网络:在训练时保持精准权重,但在测试时仅仅保留尺度因子:-1,1,0
- winograd:
在计算卷积时,被卷积数转换为只有1,0.5,2的特征映射矩阵(移位实现),将卷积核转换为4*4的张量 ,将两个矩阵对应位置的元素相乘,再进行逆变化
1.11 高效算法
- 并行化
(1)数据并行化
同时导入多张照片输入;同时进行多组参数的更新。
(2)模型并行化
将输入分割并行处理(图片分割);将权重分割;
(3)超参数并行化
在不同的机器上调整学习速率和权值衰减
- 混合精度
使用16位和32位混合,32位用于加法,16位用于乘法
- 模型蒸馏
将大型网络计算的得分进行融,让差距变小,但是仍能体现正确性(硬得分转换为软得分)
二.基础算法
1.1 SVM
1.2 特征提取:将较难表示的特征进行转换
- 颜色直方图:颜色在图像中的占比
- 词袋:稀疏表示,字典(不关注顺序)
- 方向梯度直方图:更倾向于提取边缘信息,对颜色不重视
(1)对图像使用x,y轴梯度算子得到梯度的方向和幅值(如果存在多通道,选择幅值最大的)
(2)将0-180分成若干份,根据方向进行幅值的分配(30°,幅值80,那么20°和40°都要40)
(3)得到直方图
(4)如果要减少光线的影响,那么还需要进行归一化(L2范数)
参考:图像学习之如何理解方向梯度直方图(Histogram Of Gradient)
三.激活、池化、正则化、预处理
3.1 激活作用:增加模型的非线性表示能力
3.2 激活函数主要类别
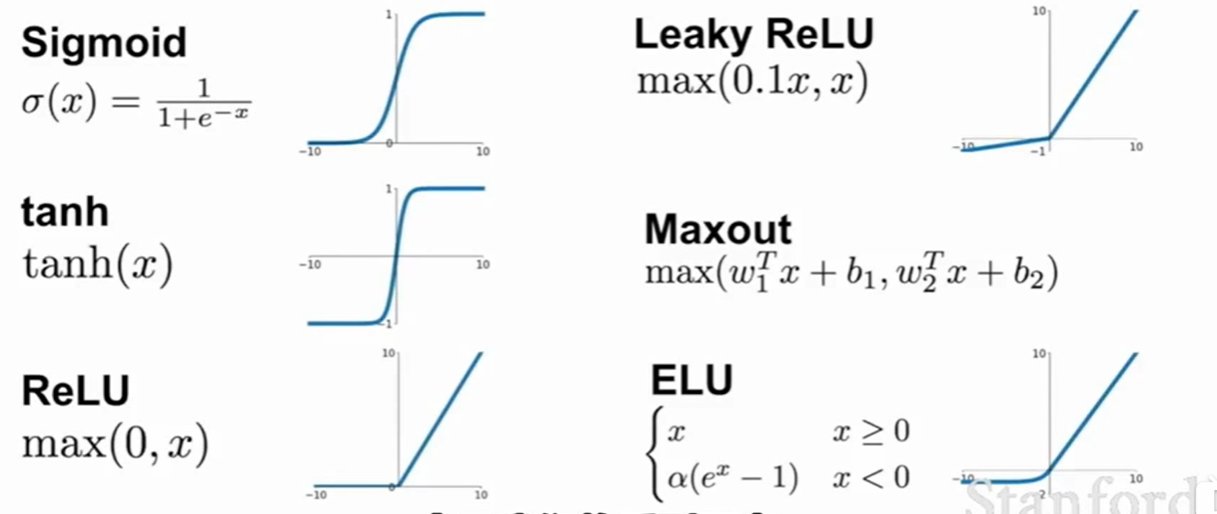
- sigmoid:
(1)当输入的数据绝对值比较大的时候,图像比较平稳,可能出现梯度消失。
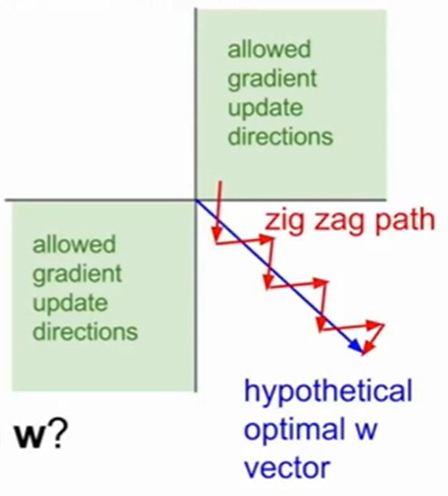
(2)梯度恒为正,可能会导致梯度只能在某个方向上变化(如下,只能沿着一、四象限方向运动)
- tanh:主要解决了问题(2)
- ReLU:
(1)解决上述两个问题
(2)收敛的速度更快,比sigmoid和tanh快6倍
(3)当输入小于0时,输出为0
(4)在运行的时候,如果经过0,可能会出现结果的突变
(5)等于0时的梯度为0
ReLU比较贴合神经元的结构,因此往往优先被使用,而考虑到(3)(4)两个问题,因此Leakly ReLU,ELU被构建。
- PReLU:其中的α可以在过程中学习
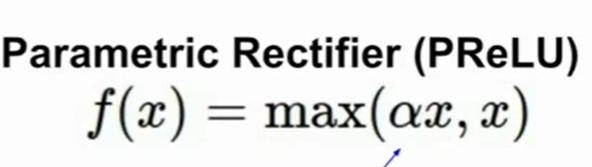
3.3池化作用
- 降低维度,减少计算量并防止过拟合(在训练集上表现的很好,非常准确,但是在测试集上效果很差:原因很多,可能是因为模型学的太强了,把一些不是该类的属性也学进去了,比如模型惊人的发现训练集中所有的野子都是锯齿状的,然后它就认为没有锯齿状的就不是叶子)
- 融合局部的特征
3.4 池化方法
- 最大池化:选择矩阵中的最大值作为矩阵的代表
- 均值池化:将小矩阵的均值作为矩阵的代表
3.5 正则作用:防止过拟合
3.5 正则方法
- 减小训练和测试之间的误差
- 全变差正则化:将左右相邻的像素差异转换成上下差异来增加图像的平滑度
- Dropout:
(1)元素置零:对激活层的部分元素置零
(2)权重置零:对一些权重置零
(3)层次置零:随机跳过一些层次
(4)可以看成集成学习,将不同的置零网络看成新的模型
- 随机深度:在训练的时候只使用部分层,在测试时使用全部层
3.6 预处理 原则:
- 尽量少的预处理,预处理可能会丧失原空间的特征和空间结构
- 参数的初始化不合理结果:初始化过大或过小都会导致梯度变化不正常
(1)初始化过大,快速增长,容易达到激活函数(sigmoid,tanh)的梯度饱和区域,则上游梯度过小
(2)初始化过小,导致上游传回的梯度乘上的数较小,则下游较小。
3.7 预处理方法
- 零均值化:
为了防止函数值始终正负不变导致梯度只能在某个方向上变化,所以要对数据进行0均值化
- 批量归一化(Batch Normalization):
将数据转换为单位高斯分布,并通过γ和β控制饱和的程度

四.网络结构
4.1卷积神经网络(CNN)
- 同类图像在全局的特征上可能不太相似,但是局部的特征往往有相似之处。
- 网络结构:CNN就是由一下几个层,有规律,有顺序的组合而成
(1)输入层:将输入图像转换为像素矩阵
(2)卷积层:利用卷积核以一定的步长扫描输入像素矩阵,提取局部的特征,得到feature map(特征图)【整体还是线性的过程】
(3)激活层:使用激活函数,对feature map的每个位置进行激活(提高模型的非线性表示能力)
(4)池化层:使用一些池化的方法对矩阵降维,更加深入的获取信息。(对局部信息的一个小融合)
(5)全连接层:使用和最后的feature map一样大小的卷积核(数量由输出的类别数决定)进行运算,然后使用函数进行归一化(常用softmax)
- 经过训练,网络的参数被反向传播所更新(训练),网络知道了怎么样的权重可以得到正确的分类(最小的损失函数)。
4.2 循环神经网络(RNN)
- 产生原因:
(1)CNN网络在时序方面的能力很弱,结合“人的认知是基于过往的经验和回忆”,所以人们研发了RNN,主要用于时序上的推理
(2)CNN对于网络的输入和输出太过严格,因此使用RNN能完成网络输入输出大小的自由化
 RNN更新函数 RNN更新函数 |
 多输入-多输出的RNN 多输入-多输出的RNN |
- 网络结构隐层的输入除了原本的输入,还增加了上一次的输出,进而完成时序上的更新,经过重复的训练,网络的参数得到优化,就能进行一些预测。
- 沿时间截断的反向传播:考虑到循环步骤的复杂性可能影响梯度反传,因此往往都是经过几个循环的步骤就进行反向传播,而不会等到所有循环都结束才反传
- 缺点:在迭代的过程中,可能出现梯度爆炸或者梯度消失的状况
4.3 长短期记忆网络网络(LSTM)
- 针对RNN一些问题,LSTM被提出(LSTM是一个被超级广泛运用的网络)
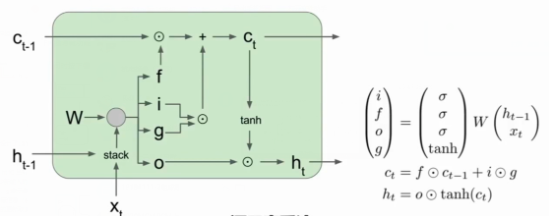
- 网络结构:上一层传递来的隐藏信息 ht-1 和 当前层的输入信息xt串联,并乘上一个很大的权重矩阵,会得到ifog四个门
(1) i:input表示接受多少新输入的信息
(2)f:forget表示遗忘多少以前的信息
(3)o:output表示展现多少信息给下一个单元格的隐藏层
(4)g:表示多少信息写输出中
(5)ht 表示当前层的隐藏信息(会传递) ct表示单元状态(是存储在LSTM中向量,不会完全暴露)
(6)对当前单元格状态的更新取决于以前的单元格状态、遗忘门、输入和g门,而当前层的隐藏状态为输出和当前单元格的状态决定
- 优点:
(1)在反向传播过程中,不断乘以变化的遗忘门,可以避免梯度消失和梯度爆炸的可能
(2)遗忘门使用sigmoid函数,能保证函数值处于0-1之间,使得数值性质更好
(3)遗忘门的矩阵乘法采用的是矩阵元素的乘法,计算量更小
4.4 残差神经网络(ResNet)
- 网络深度的增加会能让网络更好的提取信息(至少不会让网络性能变差【毕竟依靠的是梯度反传】),但在实践中,人们发现:当网络深度增加的时候,网络竟然变差了!!!!所以人们发明了深度残差网络
- 特点
(1)使用残差进行计算,输出层由H(x)变成H(x)-x。【保证了准确率的不断上升】
(2)使用了高速公路/短路操作(允许进行一些跳跃)
(3)当网络维度过大的时候,会使用1*1卷积核作为瓶颈,来缩小维度
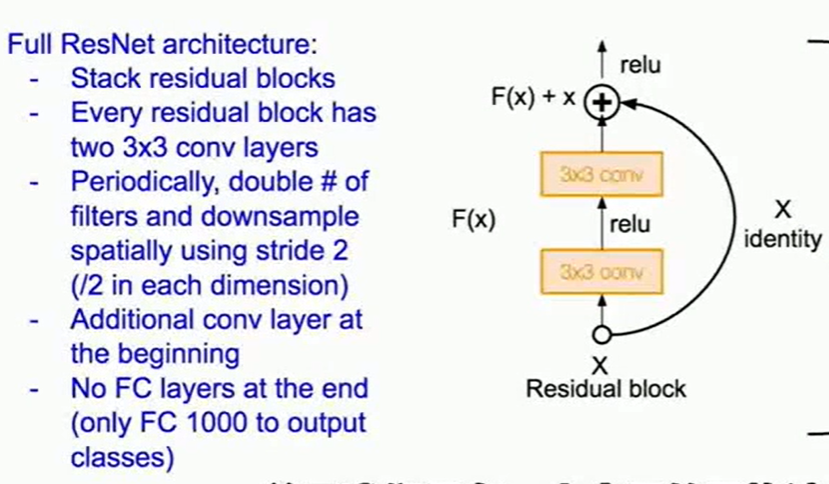
- 改进
(1)ResNeXt:在残差模块中使用更多的分支来拓宽深度(使用多个更小的卷积核)
(2)FractalNet:使用分形结构,来实现网络深层和浅层的合并
(3)DenseNet:对于一些区块,每一层都与后面所有层相连接
(4)随机深度网络:将其中一部分的层的权重设置成恒等变化
五.优化
5.1 深度学习 之所以能够如此蓬勃的发展,很大程度上归功于反向传播算法的提出,现在主流的深度学习算法的优化都是基于反向传播算法。
5.2 梯度下降的改进
-
随机梯度下降(SGD)
(1)沿着梯度的方向下降,十分考验学习率
(2)可能在不同的方向上的敏感性不一样,以至于在某个方向上飞快变化,另一个方向却走得很慢
(3)很容易陷入局部最优解或者鞍点【低维局部最优解影响大,高维鞍点】

敏感性脆弱
-
动量+SGD:位移的变化不在梯度的方向上,而在速度的方向上(速度受到摩擦的衰减和梯度的叠加)【利用速度越过局部点】
-
Nesterov Momentum:先对速度进行变化,然后再对梯度进行变化,完成当前速度的更新
 Momentum+SGD
Momentum+SGD
|
 Nesterov Momentum
Nesterov Momentum
|
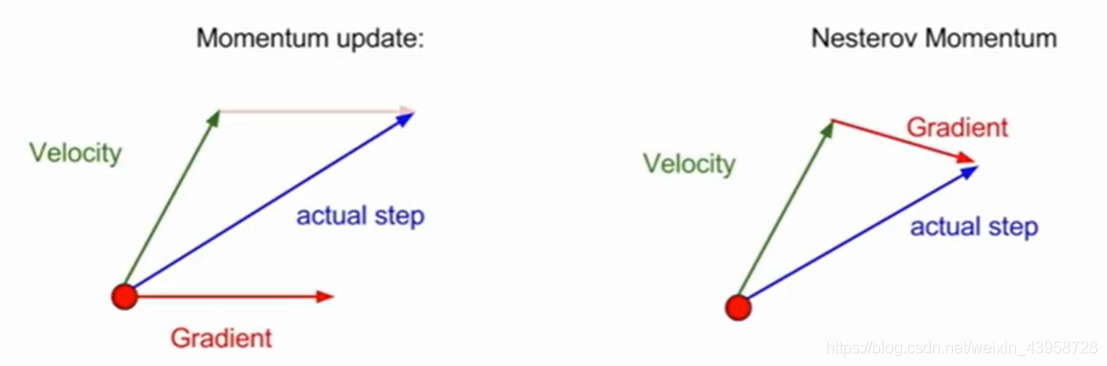
- AdaGrad:每次都设置变量累加上梯度的平方,并在位移处除以累计值的开方,降低在某个方向上的敏感性
- RMSProp:在AdaGrad中的变量中加入动量
 AdaGrad
AdaGrad  RMSProp
RMSProp
|
- Adam:上述方法的融合(首选)
(1)引入动量,对速度进行控制
(2)引入梯度平方的除法,对敏感性进行控制
(3)对于原始的Adam可能第一步的步长很大,进行改进(除以无偏估计)
 原始Adam
原始Adam  改进Adam
改进Adam
|
5.3 学习率:
- 可以被看成是选择走多少的梯度,如果学习率为1,那么就是直接走到对应的点
- 学习率的改变应该是最后进行考虑的,而且改变的时候需要找到在哪些点要修改(画损失函数图像)
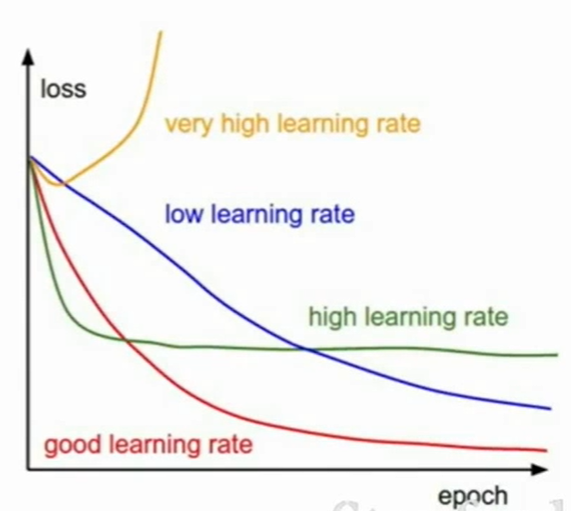
学习率对损失函数的影响
六.研究方向
6.1 图像标注(image caption):
- 得到图像的内容,并用自然语言说明
- 用CNN网络提取特征,传入RNN网络,循环迭代(存在开始和结束的标签)
- 改进:带注意力的图像标注
图像的每个特殊位置用向量表示,循环过程中,向量的分布也在不断改变,每个环节除了固有的输出(词汇表上的分布),还有传递给下一个环节的特征向量的分布(图像上的分布),即注意力的不断改变。
 示例
示例
 CNN-RNN示意图
CNN-RNN示意图
|
6.2 分类与定位
- 要从图像中找出一定数量的对象,并给出bounding box
- 方法:使用卷积网络得到两个输出
(1)对象的得分
(2)bounding box 的位置以及大小的得分
6.3 对象识别
- 从图中找出不知数量的对象,并给出bounding box
- 方法
(1)滑动窗口法:利用窗口进行局部的分辨,并将窗口进行滑动
(2)先使用图像寻找网络找到备选区域,再对候选区域分析
- R-CNN:利用固定的设定网络对备选区域进行处理,找到对应的候选区域
- Fast-RCNN:通过卷积网络对整幅图像进行处理,并学习,最后针对备选区域的卷积快实现划分同时,处理过程共享卷积层
- YOLO/SSD:将输入像素有规律的分成多个网格,并想象网格中存在一些不同的基本bounding box(横竖长方形),然后利用卷积网络计算真实的偏差。
 分类与定位
分类与定位
|
 对象识别
对象识别
|
6.4 语义分割
- 为每个像素产生标签
- 方法1:通过部分图像的中间像素来表示该部分(将该部分传入网络)
改进:通过相邻部分共享权重
- 方法2:利用全连接网络对整张图像进行处理,得到各个点的标签得分
改进:全连接网络会产生巨大的开销,因此先采用下采样(池化,跨卷积)来降维,再采用上采样(去池化,反向跨卷积)来恢复维度。
6.5 物体分割
- 对输入图像中的对象进行标签(类似于语义分割,但是只针对指定对象)
- Mask-RCNN:先进行候选框的寻找,再对其中每个像素求解
 语义分割
语义分割
|
 物体分割
物体分割
|
6.6 无监督学习
- 降维:找到对应的最大方差轴,并实现投影。
- 密度估计:估计数据内在分布
- 生成式模型:通过已有数据得到的模型再来预估新的数据
(1)CNNs和RNNs:利用极大似然的原理,让估计的图像与实际训练输入的图像尽可能相似,训练得到网络框架后,在应用时,给出一个像素点,得到整幅图像。
(2)PixelRNN:通过迭代,生成对应点的像素,并最大化似然函数
(3)PixelCNN:通过将周围灰色的像素导入CNN,得到中间黑色像素的结果(faster)
 PixelRNN
PixelRNN
|
 PixelCNN
PixelCNN
|
(4)自动编码器: 将输入利用编码器(神经网络)降维,再利用编码器升高至原来的维度完成重构,并计算对 应的损失(如果对于监督学习,在这一步之后,对比较好的重构x再求出对应的label,与真实 label计算损失)
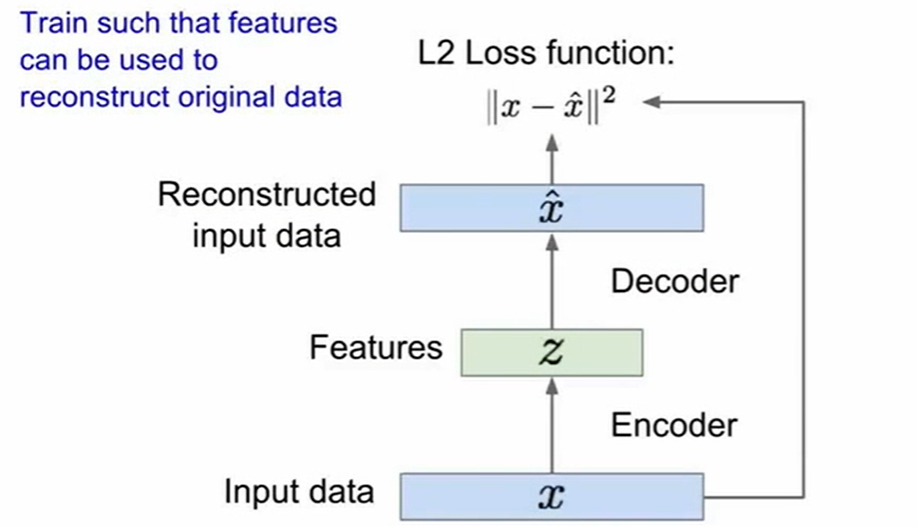
(5)变分编码器:
在自动编码器中加入随机因子而获得某种模型,得到生成数据的概率模型。其中z表示某种潜
在属性(比如几分的笑,鼻子是怎么样的),z生成了x(根据z的设定要求,利用解码器得到对
应的图片x),我们可以假定z服从某种分布,然后使用极大似然估计来计算贴合度
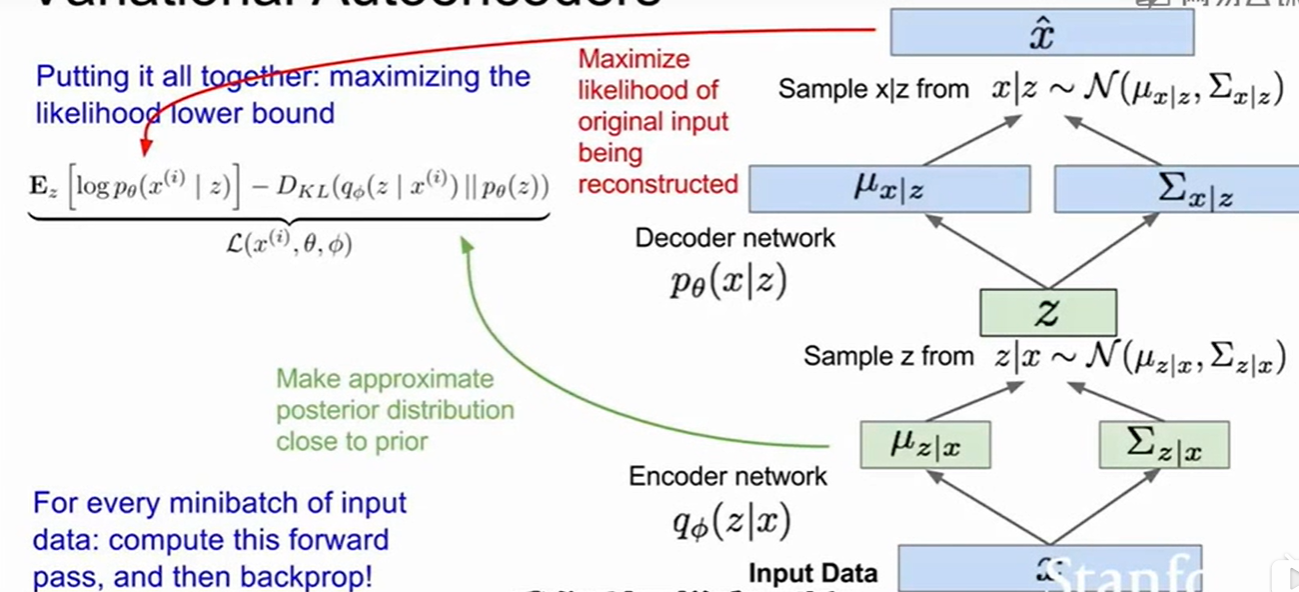
a. 整个过程:
对于输入的数据,通过编码器q得到均值和方差,并根据给定的分布实现对z的采样,这一步
就能完成后式的计算,再将z通过解码器p,同样获得均值和方差,最终在给定的分布中实现
对x的采样,实现前式的计算,完成前向传播,再反向传播,梯度更新。在训练完成之后,只
要使用解码器网络即可,通过z得到生成的x(所以主要训练解码器)
b.目标函数:
最大化各个z下得到x的概率,其中p(z)使用高斯分布可以得到,p(x|z)使用神经网络编码器,给
定z即可得到。但是积分不现实。所以采用进行了化简

将计算的指标转换成可以得到的协方差和对角 矩阵

c.结果解释:
KL散度是用来描述两个分布有多相似的,公式的第一项是由解码器网络生成的,第二项可以
看成两个网络高斯分布的KL散度(得到的均值和协方差矩阵),第三项也是两个分布的散度
而且大于0,但是其中的p(z|x)不好求,因此我们可以把前两项的和作为下界,那么最大化该
项的似然,我们也能得到一个θ和φ的估计,事实上这也是在最好的重构该变量。
6.7 可视化
- 人们尝试去解释网络黑盒子的原理
- CNN的第一个特征提取层往往提取图像的边缘以及相反的颜色
- 判断输入图像各部分的重要性:
对各个部分进行阻挡或对图像的像素进行一定的扰动,观察结果
- 怎样的图像才是最贴合模型的图像:
具体方法:将图像初始化为0,或是通过添加高斯噪声作为初始输入来去噪,然后通过3D网络计算,然后反向梯度传播,然后上升(在某类上的得分尽可能高)------愚弄图像
- 放大神经网络在某层检测到的特征
DeepDream:将输入图像运行到该层,将该层的梯度设置为激活值,反向传播,不断更新
- 特征反演:
将某一层得到的特征进行图像的重构,然后根据给出信息进行梯度上升,完善重构度(保留内容)得到与原始内容相似的新图片。
- 纹理合成:
(1)将小块的纹理合成大块的大块(保留风格)
(2)赋值周围像素,输入CNN网络,得到C个HW的特征图像,从HW中选出2个,取其C个维度,利用函数进行特征映射,得到CC的矩阵,对HW求平均(格莱姆矩阵),再利用梯度上升
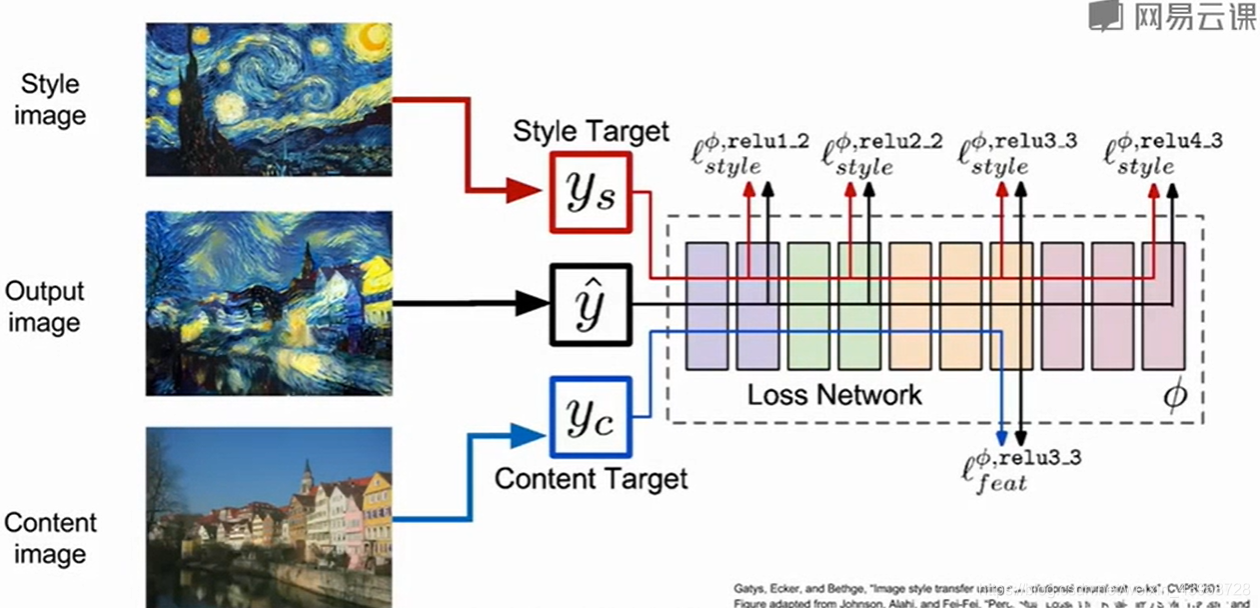
- 风格迁移
选择一副内容图像和一副风格图像,然后利用CNN,分别最小化特征重构损失和格莱姆矩阵损失,就能得到该风格下的内容图像。
6.8 强化学习
- 通过对象,环境,奖励,动作之间的关系不断激励模型更加适应与环境
- 马尔科夫链
(1) 定义

S:所有状态的 集合
A:所有动作的集合
R:奖励的分布函数
P:下一个状态转移的概率分布
γ:折扣系数
(2)运行过程:
给出一个初始时刻,然后从初始状态中采样,并将一些初始状态设为0,然后遍历循环。选择
At,然后获得Rt,得到St+1,然后循环。所以任务的目标转换为寻找最好的决策,让奖励之
和最高
- Q值函数
(1) 执行某个动作得到的奖励
(2)Q*函数:奖励最多的函
bellman条件:前面的各个状态都最好,再加上本次最好构成全局最好
- Q-Learning
(1)利用函数逼近器和网络结构,不断学习的过程
(2)经验重放
考虑到连续性,当前的动作会影响到以后的一系列动作
生成经验重放记忆,每次选择一小批量的动作,状态,奖励等进行反向传递
(3)整个过程
随机初始化训练网络,重播网络,在每次训练中,对图像进行初始化,然后以小概率选择动
作,根据贪心原则(选择这一步得分最多的),然后循环得到奖励和状态,将这一步骤结果
放入记忆重放内存中,并选择一部分进行梯度下降。
(1)跳过Q值函数,直接对决策进行选择(针对连续的问题,使用梯度的方法实现计算)
(2)通过梯度上升计算最大的平均奖励对应的策略
(3)方差缩小:上述的估计会有偏差,使用折扣因子来对不同时期的权重分割,越近权重越
大;使用基线函数,体现实际奖励与目标奖励的差距
(4)Action-Critic Algorithm:评价动作和预期的差值
1.初始化策略参数θ以及评价函数φ
2.在每一次的训练迭代中,走每一条路,然后沿着做出动作,使用策略得到一定的轨迹。
3.累计并计算梯度
4.完成更新

6.9 迁移学习
- 针对数据少而模型复杂的问题,为了方式网络训练不佳,利用其他数据训练的网络参数,再对一定数量的最后层进行训练(两个数据集应该是类似的)
6.10对抗样本和对抗网络
- 对原始的像素进行一些平移,并乘上系数就能让图像识别完全出错
- 原因:欠拟合,模型的线性化程度太高,以至于一些改变会把样本弄到离分界线很远的地方
- 训练对抗样本的办法:【比如快速符号梯度算法(fast gradient sign method ,FGSM)】
最大化损失函数,但是把每个点像素的变化范围进行限制(单个点变化不大,但是整体变化很大,那么肉眼可能就看不出来)
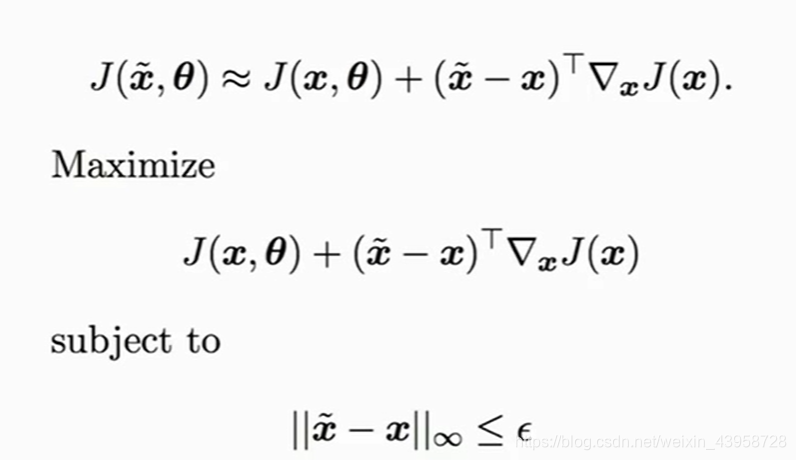
- 对抗样本不是噪声,加上噪声可能会不变,但是对抗样本一定会错
- RBF网络具有良好的非线性性,以及宽广平坦的区域,可以比较好的抵御对抗样本,但是很难训练(梯度经常为0)
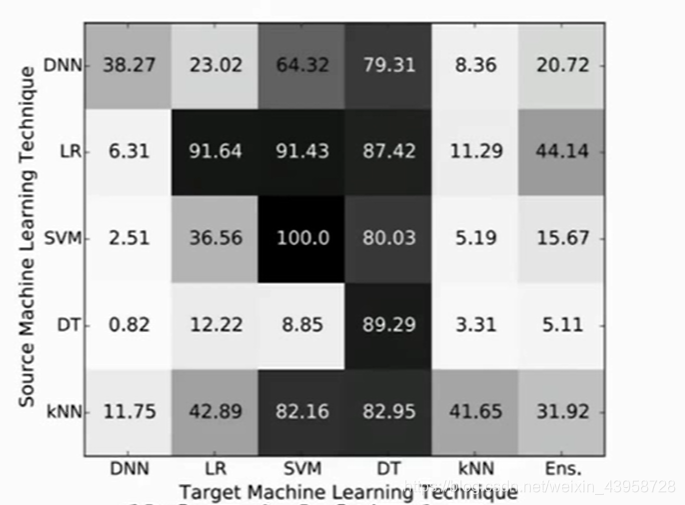
- 模型间的迁移(得分越高,越容易被迁移对抗)
- 训练对抗样本的方法:
(1)针对想要攻击的任务标上标签,利用自己的数据集标上标签,进行训练
(2)研究对应的模型的输入和输出(黑盒子)
- 对于集成的模型,生成的对抗样本可以对抗所有的部分模型
- 在训练的不是很好的模型上。使用虚拟对抗技术生成对抗样本,然后继续训练它,让他和原来一样



















































 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















