















































软件

产品



目标函数
function y=F(x, N)
y=0;
for i=1:(N-1)
y=y+(1-x(i))^2+100*(x(i+1)-x(i)^2)^2;
end
end
函数梯度(N维向量,注意首尾变量)
function g=G(x, N)
g=zeros(N,1);
g(1)=2*(x(1)-1)+400*(x(1)^3-x(2)*x(1));
for i=2:(N-1)
g(i)=200*(x(i)-x(i-1)^2)+2*(x(i)-1)+400*(x(i)^3-x(i+1)*x(i));
end
g(N)=200*(x(N)-x(N-1)^2);
end
Hessen矩阵( N × N N\times N N×N,对梯度再求导)
function h=H(x, N)
h=zeros(N,N);
h(1,1)=2+1200*x(1)^2-400*x(2);
h(1,2)=-400*x(1);
for i=2:(N-1)
h(i,i-1)=-400*x(i-1);
h(i,i)=202+1200*x(i)^2-400*x(i+1);
h(i,i+1)=-400*x(i);
end
h(N,N-1)=-400*x(N-1);
h(N, N)=200;
end
几种 优化 方法的不同之处主要在于搜索方向的选取,步长使用不精确的线搜索得到(满足Wolfe-Powell准则)。
线搜索部分可以参考线搜索(line search)方法
x ( k + 1 ) = x ( k ) − λ k ∇ f ( x ( k ) ) x^{(k+1)}=x^{(k)}-\lambda_k\nabla f(x^{(k)}) x(k+1)=x(k)−λk∇f(x(k))
function main_gd
N=100;
x0=zeros(N,1);
eps=1e-4;
g0=G(x0, N);
step=0;
while norm(g0)>=eps
F0=F(x0, N);
fprintf('step %d: %.10f\t %f\n',step, F0, norm(g0));
s0=-g0;
%linear search
lambda0=1;
c1=0.1; c2=0.5;
a=0; b= inf;
temp=g0'* s0;
while 1
x1=x0+lambda0*s0;
if F0-F(x1, N) < -c1*lambda0*temp
b=lambda0;
lambda=(lambda0+a)/2;
elseif G(x1, N)'*s0 < c2*temp
a=lambda0;
lambda=min(2*lambda0, (lambda0+b)/2);
else
break;
end
if abs(lambda-lambda0)<=eps
break;
else
lambda0=lambda;
end
end
x0=x0+lambda0*s0;
g0=G(x0,N);
step=step+1;
end
fprintf('--------Gradient Descent (total step %d)---------\nx*=',step)
for i=1:N
fprintf('%.2f ',x0(i));
end
end
x ( k + 1 ) = x ( k ) − ( ∇ 2 f ( x ( k ) ) ) − 1 ∇ f ( x ( k ) ) x^{(k+1)}=x^{(k)}-(\nabla^2f(x^{(k)}))^{-1}\nabla f(x^{(k)}) x(k+1)=x(k)−(∇2f(x(k)))−1∇f(x(k))
function main_nt
N=100;
x0=zeros(N,1);
eps=1e-4;
g0=G(x0, N);
step=0;
while norm(g0)>=eps
fprintf('step %d: %.10f\t %f\n',step, F(x0, N), norm(g0));
x0=x0-H(x0, N)\g0;
g0=G(x0, N);
step=step+1;
end
fprintf('--------Newton (total step %d)---------\nx*=',step)
for i=1:N
fprintf('%.2f ',x0(i));
end
fprintf('\nf(x*)=%.2f\n',F(x0, N));
end
迭代方式逐步近似Hessen阵,初始 H 0 = I \mathbf{H}_0=\mathbf{I} H0=I:
x ( k + 1 ) = x ( k ) − λ k H k − 1 ∇ f ( x ( k ) ) x^{(k+1)}=x^{(k)}-\lambda_k\mathbf{H}_k^{-1}\nabla f(x^{(k)}) x(k+1)=x(k)−λkHk−1∇f(x(k))
function main_bfgs
N=100;
x0=zeros(N,1);
eps=1e-4;
g0=G(x0, N);
step=0;
H=eye(N, N);
while norm(g0)>=eps
fprintf('step %d: %.10f\t %f\n',step, F(x0, N), norm(g0));
s0=-H*g0;
%linear search
lambda0=1;
c1=0.1; c2=0.5;
a=0; b= inf;
temp=g0'* s0;
while 1
x1=x0+lambda0*s0;
if F(x0, N)-F(x1, N) < -c1*lambda0*temp
b=lambda0;
lambda=(lambda0+a)/2;
elseif G(x1, N)'*s0 < c2*temp
a=lambda0;
lambda=min(2*lambda0, (lambda0+b)/2);
else
break;
end
if abs(lambda-lambda0)<=eps
break;
else
lambda0=lambda;
end
%fprintf('%f\n',lambda0);
end
x1=x0+lambda0*s0;
g1=G(x1, N);
delta_x=x1-x0;
delta_g=g1-g0;
miu=1+((delta_g')*H*delta_g)/((delta_x')*delta_g);
% 更新H
H=H+((miu*delta_x*(delta_x')-H*delta_g*(delta_x')-delta_x*(delta_g')*H))/((delta_x')*delta_g);
x0=x1;
g0=g1;
step=step+1;
end
fprintf('--------BFGS (total step %d)---------\nx*=',step)
for i=1:N
fprintf('%.2f ',x0(i));
end
fprintf('\nf(x*)=%.2f\n',F(x0, N));
end
由Fletcher 和 Reeves 提出,我找了半天才知道FR方法即共轭梯度法…
注意对于N维问题的共轭方向只有N个,在N步之后需要重新选择初始点。
附算法框架图(来自:共轭梯度法通俗讲义):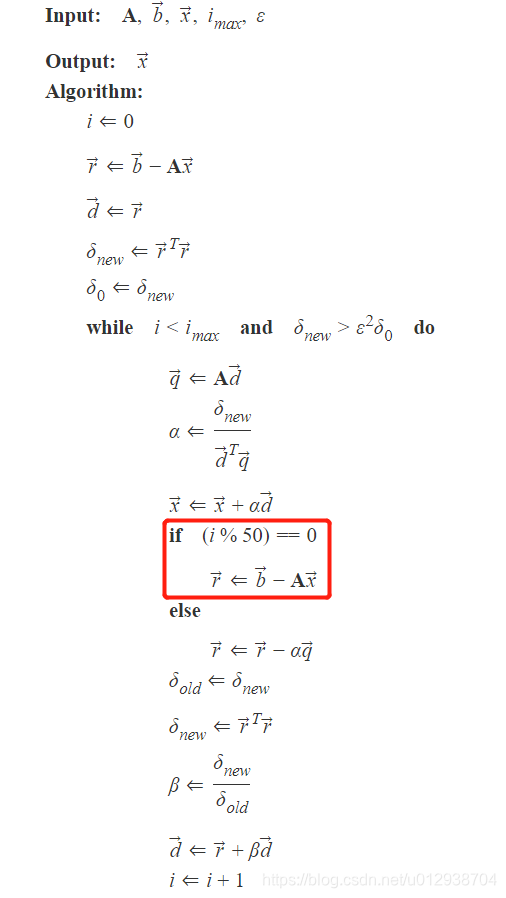
function main_frcg
N=100;
x0=zeros(N,1);
eps=1e-4;
g0=G(x0, N);
s0=-g0;
step=0;
while norm(g0)>=eps
fprintf('step %d: %.10f\t %f\n',step, F(x0, N), norm(g0));
%linear search
lambda0=1;
c1=0.1; c2=0.5;
a=0; b= inf;
temp=g0'* s0;
while 1
x1=x0+lambda0*s0;
if F(x0, N)-F(x1, N) < -c1*lambda0*temp
b=lambda0;
lambda=(lambda0+a)/2;
elseif G(x1, N)'*s0 < c2*temp
a=lambda0;
lambda=min(2*lambda0, (lambda0+b)/2);
else
break;
end
if abs(lambda-lambda0)<=1e-10
break;
else
lambda0=lambda;
end
end
x1=x0+lambda0*s0;
g1=G(x1, N);
miu=(g1'*g1)/(g0'*g0);
%以N步的近似极小点作为新的初始点
if step>=N-1
miu=0;
end
s0=-g1+miu*s0;
x0=x1;
g0=g1;
step=step+1;
end
fprintf('--------FR Conjugate Gradient (total step %d)---------\nx*=',step)
for i=1:N
fprintf('%.2f ',x0(i));
end
fprintf('\nf(x*)=%.2f\n',F(x0, N));
end
通过运行可以发现,收敛速度最快的是Newton法,其次是拟Newton法(BFGS),再是共轭梯度法,最后是 梯度下降法 。
--------Newton (total step 73)---------
x*=1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00
f(x*)=0.00
--------BFGS (total step 462)---------
--------FR Conjugate Gradient (total step 26906)---------
--------Gradient Descent (total step 27236)---------
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















