















































软件

产品


Fast Incremental Bundle Adjustment with Covariance Recovery
SLAM++ 是增量非线性最小二乘求解器的有效实现。 它是用 C++ 编写的,由于它利用块结构来解决问题并提供非常快速的解决方案来在迭代非线性求解器中操作块矩阵,因此速度非常快。 它目前依赖于 Eigen 和 CSparse 或 CHOLMOD,但我们正在努力使其更加独立。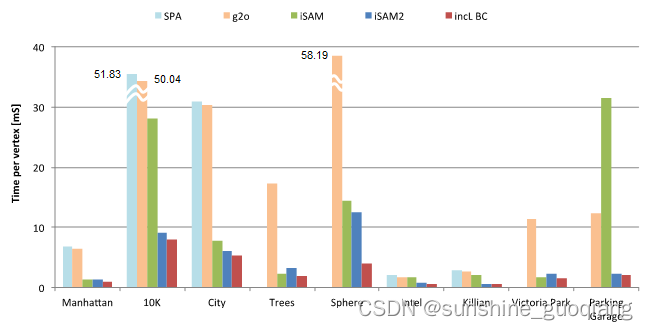
核心参考论文:
Highly Efficient Compact Pose SLAM with SLAM++
BA 参数化 ACRA - 测试来自运动估计的结构的几个参数化。 实现了三种类型的点参数化:欧几里得坐标、反深度和反距离。 点也可以用世界坐标或相对于参考相机来表示。 实现了几种相机顶点类型:SE(3)、带有校准参数的 SE(3) 和集成了比例参数的 Sim(3)。 这直接影响增量求解的收敛性; 在下图中,这很容易看出(橙色顶点的更新幅度较高,绿色和蓝色顶点的更新幅度较低)。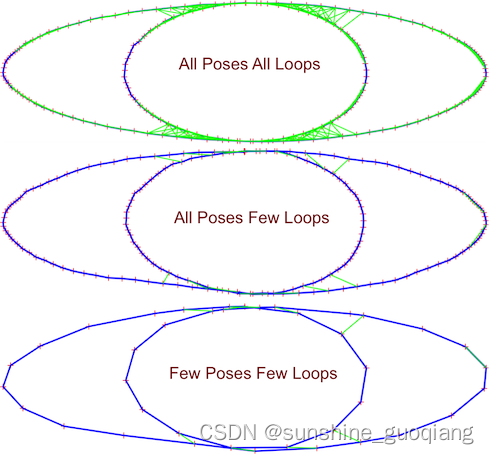
上图显示了标准图 SLAM 数据集的时间比较(我们的实现为红色)。 它目前支持 2D 和 3D 数据集。 这些是增量时间(更新和解决每个新变量),因为这是我们的实现带来优势的地方。
To get full commandline reference, simply use the --help switch:
General use:
./SLAM_plus_plus -i --no-detailed-timing
To run the pose-only datasets more quickly:
./SLAM_plus_plus -i --pose-only --no-detailed-timing
To run incrementally:
./SLAM_plus_plus -lsp -i --no-detailed-timing
This generates initial.txt and initial.tga, a description and image of the
system before the final optimization, and solution.txt and solution.tga, a
description and image of the final optimized system (unless --no-bitmaps
is specified).
–help|-h displays this help screen
–verbose|-v displays verbose output while running (may slow down,
especially in windows and if running incrementally)
–silent|-s suppresses displaying verbose output
–no-show|-ns doesn’t show output image (windows only)
–no-commandline doesn’t echo command line
–no-flags doesn’t show compiler flags
–no-detailed-timing doesn’t show detailed timing breakup (use this, you’ll
get confused)
–no-bitmaps doesn’t write bitmaps initial.tga and solution.tga (neither
the text files)
–pose-only|-po enables optimisation for pose-only slam (will warn and ignore
on datasets with landmarks (only the first 1000 lines checked
in case there are landmarks later, it would segfault))
–use-old-code|-uogc uses the old CSparse code (no block matrices in it)
–a-slam|-A uses A-SLAM (default)
–lambda|-,\ uses lambda-SLAM (preferred batch solver)
–l-slam|-L uses L-SLAM
–fast-l-slam|-fL uses the new fast L-SLAM solver (preferred incremental solver)
–infile|-i specifies input file ; it can cope with
many file types and conventions
–parse-lines-limit|-pll sets limit of lines read from the input file
(handy for testing), note this does not set limit of vertices
nor edges!
–linear-solve-period|-lsp sets period for incrementally running linear
solver (default 0: disabled)
–nonlinear-solve-period|-nsp sets period for incrementally running
non-linear solver (default 0: disabled)
–max-nonlinear-solve-iters|-mnsi sets maximal number of nonlinear
solver iterations (default 10)
–nonlinear-solve-error-thresh|-nset sets nonlinear solve error threshold
(default 20)
–max-final-nonlinear-solve-iters|-mfnsi sets maximal number of final
optimization iterations (default 5)
–final-nonlinear-solve-error-thresh|-fnset sets final nonlinear solve
error threshold (default .01)
–run-matrix-benchmarks|-rmb runs block
matrix benchmarks (benchmark-name is name of a folder with
UFLSMC benchmark, benchmark-type is one of alloc, factor, all)
–run-matrix-unit-tests|-rmut runs block matrix unit tests
initial.tga
solution_print.tga
arning: the 'LANDMARK' token is ambiguous: interpreted as XY landmark (rather than RB)
warning: XY landmark edge occured: covariance conversion to RB not performed (chi2 will be incorrect)
warning: the 'LANDMARK' token is ambiguous: interpreted as XY landmark (rather than RB)
warning: XY landmark edge occured: covariance conversion to RB not performed (chi2 will be incorrect)
done. it took 00:00:00.72327 (0.723271 sec)
solver took 142 iterations
solver spent 0.054465 seconds in parallelizable section (disparity 0.040233 seconds)
out of which:
,\: 0.035888
rhs: 0.018577
solver spent 0.628573 seconds in serial section
out of which:
chol: 0.615195
norm: 0.000574
v-upd: 0.012805
denormalized chi2 error: 114.53
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















