















































软件

产品


开篇明义,三点结论:
视频分类在动作识别、非常规动作识别、活动理解、视频内容描述等领域;视频描述器的四个特点:通用、有竞争力、高效、简洁;卷积网络并不适用于处理视频数据,因此提出 C3D.
不同数据集上的表现:
除Sport 1M上,其他数据比之前最好的都要好。
优秀!
传统机器视觉领域的SIFTs(spatio-temporal interest points)、SIFT-3D、HOG3D算法。对大规模数据集合表现intractable;
前人在3D卷积网络上的研究对比,突出点提出适用于大规模视频数据集合,具有3D卷积、3Dpooling提取时间信息的深度网络。
图一对比了3D卷积的机构特点。对于多帧的视频输入,传统2d卷积核的深度于视频的帧数相同,输出只有一层输出,因此丢失了时域信息(b);相反,3D卷积核的深度d小于输入画面的帧数L,因此一个卷积核操作以后可以得到多特征层,因而保留了时域信息(c).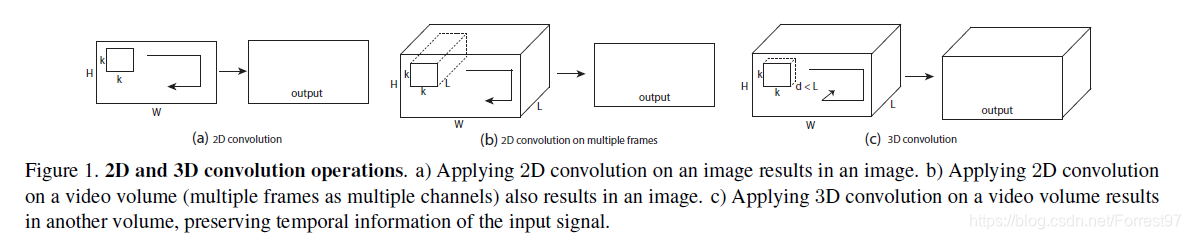
可以参看最后一张图中的数据维度,一般的conv2d的输入数据维度为(batch, w, h, channels), 卷积核和stride都是二维参数,即在(w, h)维度上进行操作;
对于conv3d为(batch, frames, w, h, channels),卷积核和stride都是三维参数,即在(frames, w, h)维度上进行操作。
对于UCF101的视频数据输入,压缩成3x16x128x171的格式
卷积核的深度d的确定:相同深度(1,3,5,7);不同深度(逐步加深3-3-5-5-7,逐步减小7-5-5-3-3)
对比结果如下: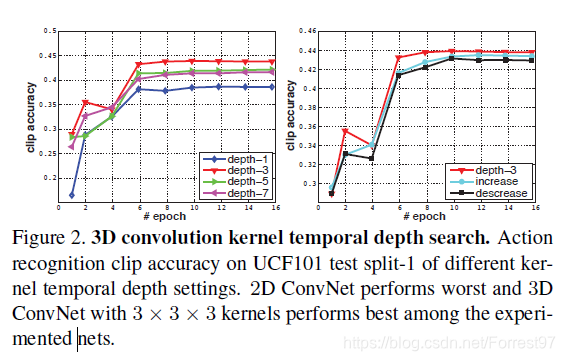
明显采用相同卷积核深度3的网络性能最好。
通过上面的对该笔提出了C3D网络的基本框架。
3x3x3的卷积核大小,1 x 1 x 1stride
2x2x2的pooling层, 2 x 2 x 2stride
整体结构:
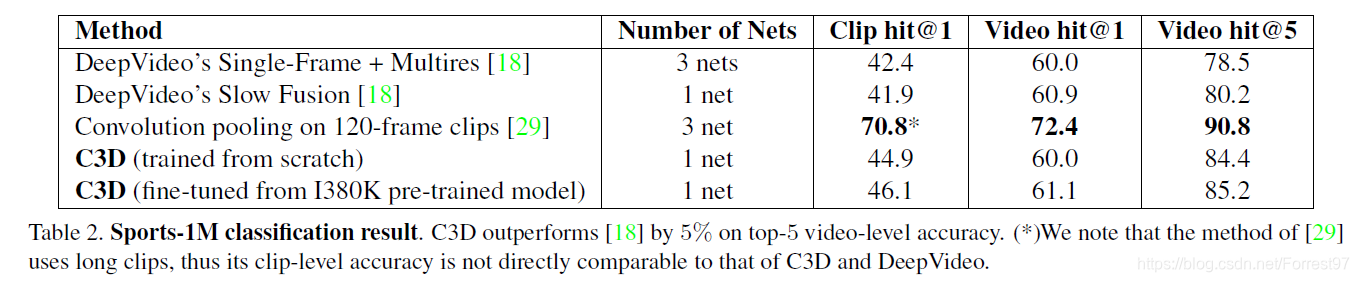
结果上看比文献29的预测准确度低,但作者说这主要是受到输入画面帧数较多的影响。
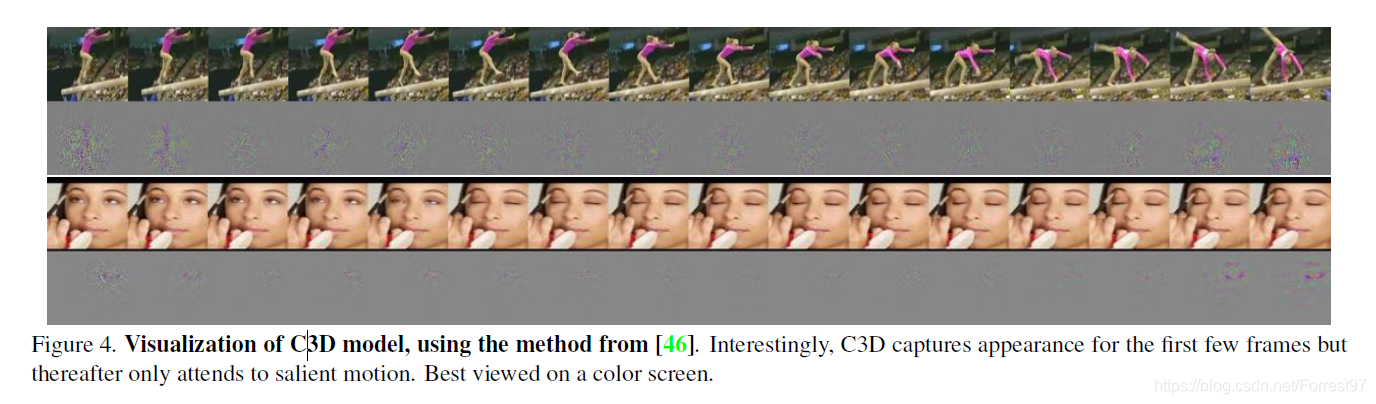
对conv5b特征层进行可视化,可以发现C3D网络相比2D网络对运动物体更加敏感。
UCF101数据集的动作识别结果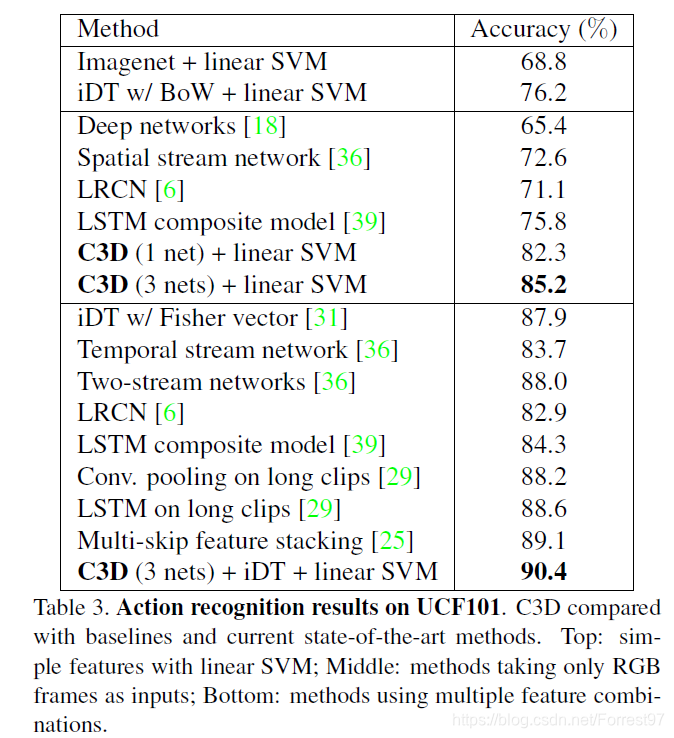
网络的一些组合和比较,比如C3D (3 nets) 表示三组C3D的fc6同时并联,与SVM结合后能提高预测精度(这里三组C3D训练差别没有太看明白)
通过提取不同算法的全连接层提取的体征,适用PCA算法降维到10后,对比算法的准确度,进而比较compactness性能。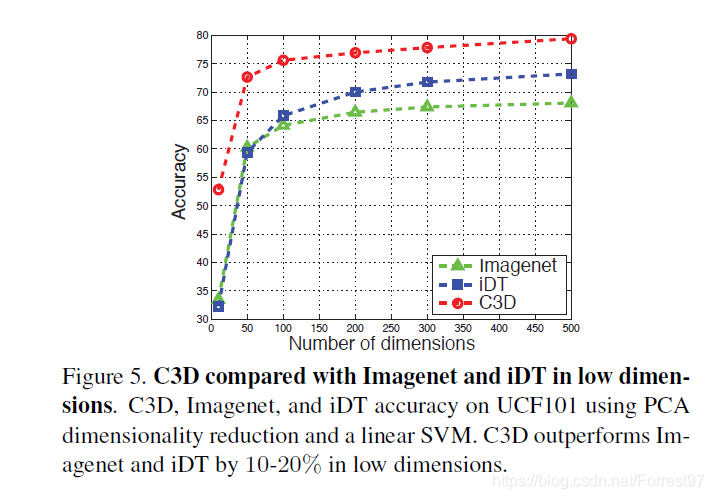
相同的fc6特征层,使用t-SNE算法降维到2维可视化空间。
可见C3D对不同类型的视频在2维空间中有很好的分离
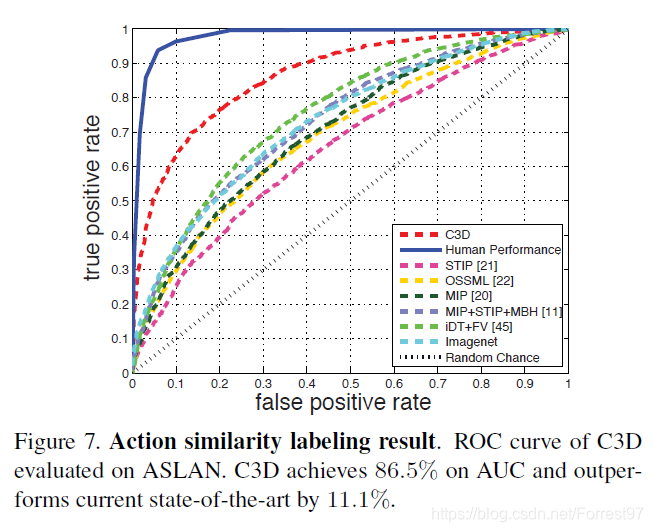
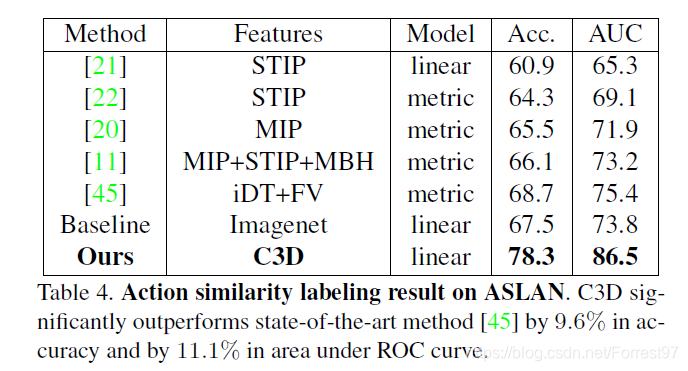
YUPENN(420 videos of 14 scene categories)和Maryland(130 videos of 13 scene categories)数据集。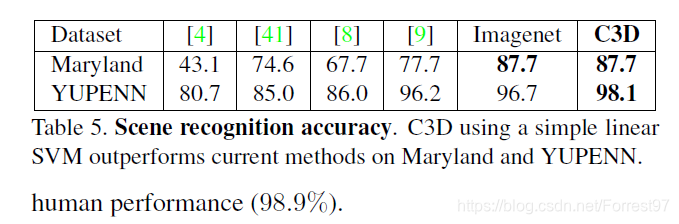
同样优秀!
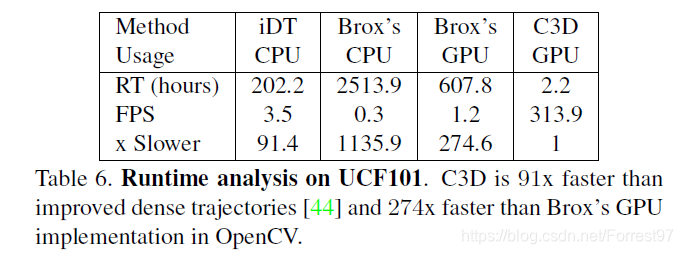
一样的优秀!
卷积神经网络 ,可视化的展示

Learning Spatiotemporal Features with 3D Convolutional Networks
http://vlg.cs.dartmouth.edu/c3d/
import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers, models, Input from tensorflow.keras.models import Model from tensorflow.keras.layers import Conv3D, MaxPooling3D, Dense, Flatten, Dropout, ZeroPadding3D def C3Dnet(nb_classes, input_shape): input_tensor = Input(shape=input_shape) # 1st block x = Conv3D(64, [3,3,3], activation='relu', padding='same', strides=(1,1,1), name='conv1')(input_tensor) x = MaxPooling3D(pool_size=(1,2,2), strides=(1,2,python
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020



















.png)

