















































软件

产品


构建自定义聊天机器人,以使用 LangChain、OpenAI 和 PineconeDB 从任何数据源开发问答应用程序
大型语言模型的出现是我们这个时代最令人兴奋的技术发展之一。它为人工智能领域开辟了无限可能,为各行业的现实问题提供了解决方案。这些模型最有趣的应用之一是开发来自个人或组织数据源的自定义问答或聊天机器人。然而,由于LLMS接受的是公开可用的一般数据的培训,因此他们的答案可能并不总是具体或对最终用户有用。为了解决这个问题,我们可以使用LangChain等框架来开发自定义聊天机器人,根据我们的数据提供特定的答案。在本文中,我们将学习如何构建自定义问答应用程序并部署在 Streamlit Cloud 上。那么让我们开始吧!
问答或“通过数据聊天”是LLMs 和 LangChain 的一个流行用例。LangChain 提供了一系列组件来加载您可以为您的用例找到的任何数据源。它支持大量数据源和转换器转换为一系列字符串以存储在矢量数据库中。一旦数据存储在数据库中,就可以使用称为检索器的组件查询数据库。此外,通过使用LLMS,我们可以像聊天机器人一样获得准确的答案,而无需处理大量文档。
LangChain支持以下数据源。如图所示,它允许超过 120 个集成来连接您可能拥有的每个数据源。
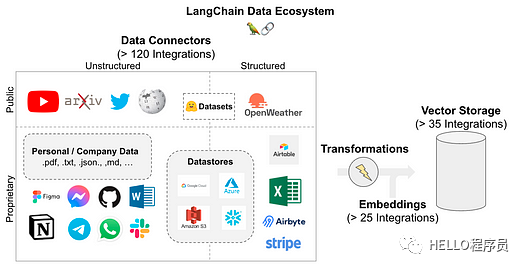 图片
图片
我们了解了LangChain支持的数据源,这使我们能够使用LangChain中可用的组件开发问答管道。以下是 LLM 用于文档加载、存储、检索和生成输出的组件。
这是问答管道的高级工作流程,可以解决多种类型的现实问题。我没有深入研究每个 LangChain 组件
 图片
图片
自定义问答相对于模型微调的优势
Pinecone 是一种流行的矢量数据库,用于构建 LLM 支持的应用程序。它具有多功能性和可扩展性,适用于高性能人工智能应用。它是一个完全托管的云原生矢量数据库,不会给用户带来任何基础设施麻烦。
LLMS基础应用程序涉及大量非结构化数据,需要复杂的长期记忆才能以最大准确度检索信息。生成式人工智能应用程序依靠向量嵌入的语义搜索来根据用户输入返回合适的上下文。
Pinecone 非常适合此类应用程序,并经过优化以低延迟存储和查询大量向量,以构建用户友好的应用程序。让我们学习如何为我们的问答应用程序设置松果矢量数据库。
复制
# install pinecone-client
pip install pinecone-client
# 导入 pinecone 并使用您的 API 密钥和环境名称进行初始化
import pinecone
pinecone.init(api_key= "YOUR_API_KEY" ,envirnotallow= "YOUR_ENVIRONMENT" )
# 创建您的第一个索引以开始存储Vectors
pinecone.create_index( "first_index" ,Dimension= 8 , metric= "cosine" )
# 更新插入样本数据(5个8维向量)
index.upsert([
( "A" , [ 0.1 , 0.1 , 0.1 , 0.1 , 0.1 ) , 0.1 , 0.1 , 0.1 ]),
( "B" , [ 0.2 , 0.2 , 0.2 , 0.2 , 0.2 , 0.2 , 0.2 , 0.2 ]),
( "C" , [ 0.3 , 0.3 , 0.3 , 0.3 , 0.3 , 0.3 , 0.3 , 0.3 ]),
( "D" , [ 0.4 , 0.4 , 0.4 , 0.4 , 0.4 , 0.4 , 0.4 , 0.4 ]),
( "E" , [ 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 , 0.5 ])
])
# 使用 list_indexes() 方法调用 db 中可用的多个索引
pinecone.list_indexes()
[Output]>>> [ 'first_index' ]
在上面的演示中,我们安装了一个pinecone客户端来初始化我们项目环境中的矢量数据库。初始化向量数据库后,我们可以创建具有所需维度和度量的索引,以将向量嵌入插入到向量数据库中。在下一节中,我们将使用 Pinecone 和 LangChain 为我们的应用程序开发语义搜索管道。
我们了解到问答应用程序工作流程有 5 个步骤。在本节中,我们将执行前 4 个步骤,即文档加载器、文本拆分器、向量存储和文档检索。
要在本地环境或云基础笔记本环境(例如 Google Colab)中执行这些步骤,您需要安装一些库并在 OpenAI 和 Pinecone 上创建一个帐户以分别获取它们的 API 密钥。让我们从环境设置开始:
复制
# install langchain and openai with other dependencies
!pip install --upgrade langchain openai -q
!pip install pillow==6.2.2
!pip install unstructured -q
!pip install unstructured[local-inference] -q
!pip install detectron2@git+https://github.com/facebookresearch/detectron2.git@v0.6#egg=detectron2 -q
!apt-get install poppler-utils
!pip install pinecone-client -q
!pip install tiktoken -q
# setup openai environment
import os
os.environ["OPENAI_API_KEY"] = "YOUR-API-KEY"
# importing libraries
import os
import openai
import pinecone
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
from langchain.llms import OpenAI
from langchain.chains.question_answering import load_qa_chain
安装设置完成后,导入上述代码片段中提到的所有库。然后,按照以下步骤操作:
在此步骤中,我们将从目录加载文档作为 AI 项目管道的起点。我们的目录中有 2 个文档,我们将把它们加载到项目环境中。
复制
#load the documents from content/data dir
directory = '/content/data'
# load_docs functions to load documents using langchain function
def load_docs(directory):
loader = DirectoryLoader(directory)
documents = loader.load()
return documents
documents = load_docs(directory)
len(documents)
[Output]>>> 5
如果每个文档的长度固定,文本嵌入和LLMS的性能会更好。因此,对于任何LLMS用例来说,将文本分割成相等长度的块是必要的。我们将使用“RecursiveCharacterTextSplitter”将文档转换为与文本文档相同的大小。
复制
# split the docs using recursive text splitter
def split_docs(documents, chunk_size=200, chunk_overlap=20):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
docs = text_splitter.split_documents(documents)
return docs
# split the docs
docs = split_docs(documents)
print(len(docs))
[Output]>>>12
一旦文档被分割,我们将使用 OpenAI 嵌入将它们的嵌入存储在向量数据库中。
复制
# embedding example on random word
embeddings = OpenAIEmbeddings()
# initiate pinecondb
pinecone.init(
api_key="YOUR-API-KEY",
envirnotallow="YOUR-ENV"
)
# define index name
index_name = "langchain-project"
# store the data and embeddings into pinecone index
index = Pinecone.from_documents(docs, embeddings, index_name=index_name)
在此阶段,我们将使用语义搜索从矢量数据库中检索文档。我们将向量存储在名为“langchain-project”的索引中,一旦我们查询到与下面相同的内容,我们就会从数据库中获得最相似的文档。
复制
# An example query to our database
query = "What are the different types of pet animals are there?"
# do a similarity search and store the documents in result variable
result = index.similarity_search(
query, # our search query
k=3 # return 3 most relevant docs
)
-
--------------------------------[Output]--------------------------------------
result
[Document(page_cnotallow='Small mammals like hamsters, guinea pigs,
and rabbits are often chosen for their
low maintenance needs. Birds offer beauty and song,
and reptiles like turtles and lizards can make intriguing pets.',
metadata={'source': '/content/data/Different Types of Pet Animals.txt'}),
Document(page_cnotallow='Pet animals come in all shapes and sizes, each suited
to different lifestyles and home environments. Dogs and cats are the most
common, known for their companionship and unique personalities. Small',
metadata={'source': '/content/data/Different Types of Pet Animals.txt'}),
Document(page_cnotallow='intriguing pets. Even fish, with their calming presence
, can be wonderful pets.',
metadata={'source': '/content/data/Different Types of Pet Animals.txt'})]
我们可以根据相似性搜索从向量存储中检索文档。
在问答应用程序的最后阶段,我们将集成工作流程的每个组件来构建自定义问答应用程序,该应用程序允许用户输入各种数据源(例如基于网络的文章、PDF、CSV 等)与其聊天。从而使他们在日常活动中富有成效。我们需要创建一个 GitHub 存储库并将以下文件添加到其中。
 图片
图片
需要添加的项目文件:
我们在此项目演示中支持两种类型的数据源:
这两种类型包含广泛的文本数据,并且在许多用例中最常见。您可以查看下面的main.py python 代码来了解应用程序的用户界面。
复制
# import necessary libraries
import streamlit as st
import openai
import qanda
from vector_search import *
from utils import *
from io import StringIO
# take openai api key in
api_key = st.sidebar.text_input("Enter your OpenAI API key:", type='password')
# open ai key
openai.api_key = str(api_key)
# header of the app
_ , col2,_ = st.columns([1,7,1])
with col2:
col2 = st.header("Simplchat: Chat with your data")
url = False
query = False
pdf = False
data = False
# select option based on user need
options = st.selectbox("Select the type of data source",
optinotallow=['Web URL','PDF','Existing data source'])
#ask a query based on options of data sources
if options == 'Web URL':
url = st.text_input("Enter the URL of the data source")
query = st.text_input("Enter your query")
button = st.button("Submit")
elif options == 'PDF':
pdf = st.text_input("Enter your PDF link here")
query = st.text_input("Enter your query")
button = st.button("Submit")
elif options == 'Existing data source':
data= True
query = st.text_input("Enter your query")
button = st.button("Submit")
# write code to get the output based on given query and data sources
if button and url:
with st.spinner("Updating the database..."):
corpusData = scrape_text(url)
encodeaddData(corpusData,url=url,pdf=False)
st.success("Database Updated")
with st.spinner("Finding an answer..."):
title, res = find_k_best_match(query,2)
context = "\n\n".join(res)
st.expander("Context").write(context)
prompt = qanda.prompt(context,query)
answer = qanda.get_answer(prompt)
st.success("Answer: "+ answer)
# write a code to get output on given query and data sources
if button and pdf:
with st.spinner("Updating the database..."):
corpusData = pdf_text(pdf=pdf)
encodeaddData(corpusData,pdf=pdf,url=False)
st.success("Database Updated")
with st.spinner("Finding an answer..."):
title, res = find_k_best_match(query,2)
context = "\n\n".join(res)
st.expander("Context").write(context)
prompt = qanda.prompt(context,query)
answer = qanda.get_answer(prompt)
st.success("Answer: "+ answer)
if button and data:
with st.spinner("Finding an answer..."):
title, res = find_k_best_match(query,2)
context = "\n\n".join(res)
st.expander("Context").write(context)
prompt = qanda.prompt(context,query)
answer = qanda.get_answer(prompt)
st.success("Answer: "+ answer)
# delete the vectors from the database
st.expander("Delete the indexes from the database")
button1 = st.button("Delete the current vectors")
if button1 == True:
index.delete(deleteAll='true')
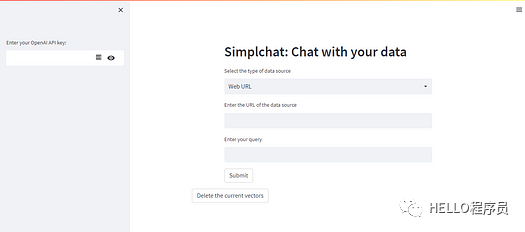 图片
图片
Streamlit 提供社区云来免费托管应用程序。此外,streamlit 由于其自动化 CI/CD 管道功能而易于使用。
总之,我们探索了使用 LangChain 和 Pinecone 矢量数据库构建自定义问答应用程序的令人兴奋的可能性。本博客向我们介绍了基本概念,从问答应用程序的概述开始,到了解 Pinecone 矢量数据库的功能。通过将 OpenAI 语义搜索管道的强大功能与 Pinecone 高效的索引和检索系统相结合,我们充分利用了利用 Streamlit 创建强大且准确的问答解决方案的潜力。
Q1:什么是Pinecone和LangChain ?
答:Pinecone 是一个可扩展的长期记忆向量数据库,用于存储 LLM 支持的应用程序的文本嵌入,而 LangChain 是一个允许开发人员构建 LLM 支持的应用程序的框架
Q2:NLP问答有什么应用?
答:问答应用程序用于客户支持聊天机器人、学术研究、电子学习等。
Q3:为什么要使用LangChain ?
答:与LLMS合作可能会很复杂。LangChain允许开发人员使用各种组件以对开发人员最友好的方式集成这些LLM,从而更快地交付产品。
Q4:构建问答应用程序的步骤是什么?
A:构建问答应用的步骤如下:文档加载、文本分割、向量存储、检索、模型输出。
Q5:LangChain 工具有哪些?
答:LangChain 有以下工具:文档加载器、文档转换器、向量存储、链、内存和代理。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















