















































软件

产品


全球领先的半导体公司AMD(AMD)在2021年以350亿美元收购了芯片制造商Xilinx(XLNX),这是AMD继收购ATI Technologies以来的又一次重大收购。不过,在深度学习领域中,大多数情况下GPU被认为是比FPGA更加强大。那么,AMD为什么会花费350亿美元收购Xilinx,而不进一步提升自己的GPU呢?进一步投资和开发GPU有助于增强自身的竞争力,尤其是在数据中心领域,竞对NVIDIA公司似乎有着非常雄心勃勃的计划。
确实,在许多情况下,GPU可以为一些应用程序提供更好的性能。对于数十亿美元的深度学习市场而言,GPU在训练方面可以提供无与伦比的性能,每个DL模型(深度学习模型)只需进行一次训练,需要几天或者几周。在DL推理(即图像分类)的情况下,GPU也提供了高性能(即以每秒帧数为单位衡量的图像吞吐量)。MLCommons提供了一种公认的基准,用于公平比较数据中心、移动计算和边缘应用的多个计算平台。在最新版本的MLCommons中,GPU在大多数类别中以吞吐量的形式占主导地位,具有更高的吞吐量表现,可以更高效地处理数据和算法。
然而,在许多应用程序中,除了原始处理能力之外,其他要求可能更为重要。例如,在移动或嵌入式应用程序中,能量效率(即处理能力/瓦)更为重要,特别是当设备由电池供电时。此外,在许多边缘设备或嵌入式系统中,延迟也是至关重要的。在这种情况下,FPGA具有更多的竞争优势,因为它们提供了非常低的延迟和更好的能量效率。特别是来自英特尔(S10 NG)和Xilinx Versal的新FPGA,它们集成了专门设计的AI引擎,可以提供高吞吐量(特别是在低批量大小情况下)、低延迟和高能量效率的绝佳组合。
 图片
图片
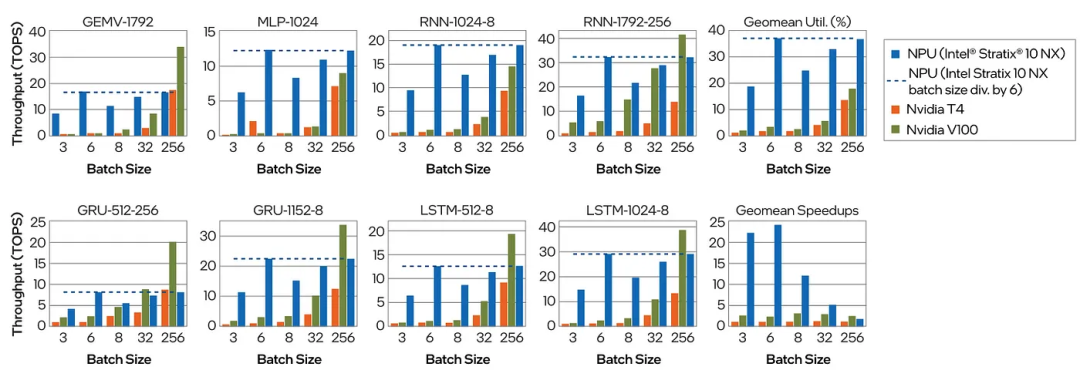
上图是NVIDIA V100和NVIDIA T4在不同批次大小下与Intel Stratix 10 NX FPGA上的NPU性能比较。参考文献:A. Boutros等人的论文“超越峰值性能:比较AI优化的FPGA和GPU的实际性能,FPT 2020”。
在许多情况下,GPU仍然可以提供更好的性能,特别是在处理大批量数据时。虽然FPGA在一些特定应用场景下具有优势,但是在其他情况下,GPU仍然是更好的选择。那么回到问题,为什么AMD要花这么多钱购买FPGA呢?
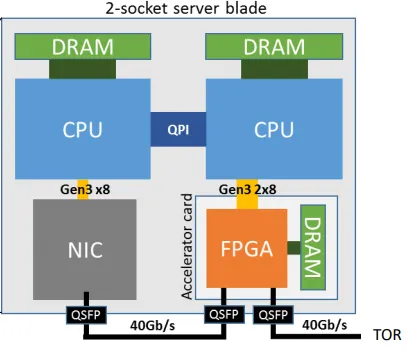
答案可能来自于FPGA在数据中心中的最近受到广泛采用的情况。微软Azure是第一批采用FPGA加速其自身应用程序的云供应商之一。Project Catapult是第一个商业部署FPGA的创新项目。可配置的云架构在网络交换机和服务器之间放置了一层可重构逻辑(FPGA),使网络流能够以线速率“可编程转换”,从而加速在服务器上运行的本地应用程序,并使FPGA能够直接在数据中心范围内通信,以收集未被其本地服务器使用的远程FPGA。例如,微软可以利用服务器中的FPGA加速Bing网络搜索排名。FPGA在数据中心中的应用范围越来越广泛,这也许是AMD购买FPGA的原因之一。
 图片
图片
上图是Project Catapult,来源:Adrian M. Caulfield等人的论文“云规模加速架构”
微软Azure宣布了在Azure Synapse中利用FPGA用于Apache Spark。根据Azure的数据,数据格式CSV、JSON和Parquet占了90%的客户工作负载。解析CSV和JSON数据格式非常耗费CPU资源,通常占据查询的70%至80%。因此,微软Azure使用FPGA加速CSV解析。FPGA解析器读取CSV数据,对其进行解析,并生成一个接近Apache Spark内部行格式(即Tungsten)的VStream格式化二进制数据。虽然FPGA解析器在FPGA级别的内部原始性能为8GB/秒,但在端到端应用程序中还无法实现全部性能。通过这种方式,他们成功提高了Apache Spark的性能。FPGAs也可用于加速Spark应用程序的机器学习,在这些应用程序中,FPGA可以加速诸如特征提取、模型推理和数据增强等任务。
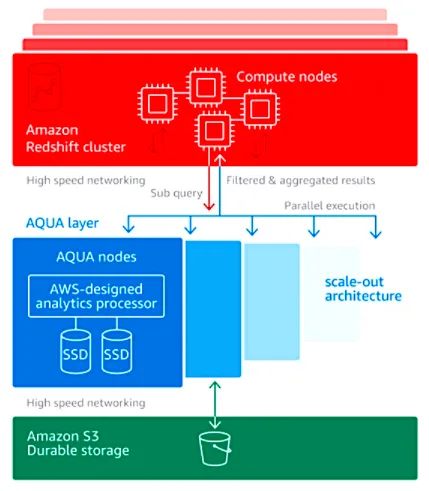
AWS是第一个宣布向终端用户提供FPGA的云供应商,于2017年推出了f1实例。FPGA开发人员可以将其设计上传到AWS市场。AWS宣布在Redshift AQUA上利用FPGA,在这项服务中,FPGA硬件执行数据集过滤和聚合。过滤可以删除数据集中不需要的信息,以创建子集;而聚合则提供记录中的总和、计数、平均值等信息。结果是向Redshift群集发送的数据量更少。由于进行了预处理,所以集群要处理的工作更少,可以将某些子查询处理卸载到AQUA节点,从而提高性能和效率。这种使用FPGA的方式在AWS的Redshift AQUA中被称为“自适应缩放”,它可以根据查询的复杂度和数据集的大小来动态分配FPGA资源。
 图片
图片
上图是Redshift AQUA使用FPGA和ASIC进行内联处理。
FPGA在数据中心的应用方面不断增长,但如何在其他应用程序中利用FPGA呢?
关键要实现更简单的FPGA部署、无缝扩展和自动资源管理。相比之下,GPU能提供易于部署、扩展和资源管理的丰富生态系统工具和方法(例如run.ai)。然而,到目前为止,FPGA的部署仍然具有挑战性,因为用户必须熟悉FPGA技术(比特流、配置文件、内存分配、LUT等)。因此,关键问题在于如何实现一种技术,让软件用户能够利用FPGA加速其应用程序,而无需先前的FPGA知识。这就是为什么InAccel的编排器提供了一种独特的技术,使任何人都能像调用软件函数一样利用FPGA的强大功能。InAccel编排器让人可以轻松地部署、扩展和资源管理FPGA集群,同时还能与任何应用程序和框架(Spark、Ray、Keras、Scikit-learn等)进行集成。这种技术的出现使FPGA在广泛的应用场景中更易于使用和普及。
例如,使用容器的强大功能,用户可以仅使用一行代码即可立即加速压缩应用程序。
复制
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















