















































软件

产品


前言
最近在乌镇举办的人工智能峰会上,AlphaGo 2.0作为一代的升级版,和现世界排名第一的柯洁进行了三局厮杀,且不说结果如何,人工智能,尤其是深度学习领域已经在悄然间走进了我们的视野之中。AlphaGo一路连克世界冠军井山裕太、朴廷桓、李世石以及柯洁等众多高手,一时间成为大家茶余饭后的话题。作为支撑AlphaGo复杂训练任务的深度学习框架tensorflow,和其他深度学习框架如caffe、CNTK等相比有什么优势?怎么样才能对它有大体的认识和了解呢?希望通过这篇文章,能够让你对上面的问题有了比较全面的了解。
tensorflow框架简介
为了巩固自身在深度学习领域的地位,gogole在2015年年底开源了内部机器学习框架DistBeilef,在相继发布了分布式版本和1.0版本后,短短一年半时间里,tensorflow在github上的star已经逼近6w,将其他的老牌深度学习框架远远甩在自己的身后,成为当下最流行的深度学习项目。不仅在图像领域,甚至是强化学习、自然语言处理等场景,tensorflow都有丰富的应用场景。
tensorflow后端采用更高效的C++、CUDA编写,前端提供python、c++、go以及java等多种开发语言。它可以在众多的异构平台上方便的移植,比如android、ios、cpu服务器以及gpu集群。除了提供常见的深度学习算法,如cnn、rnn外,tensorflow还实现了常见的机器学习算法,如线性回归、随机森林等。
tensorflow编程模型简介
构建图
我们可以使用一个有向图(或称计算图)来形象刻画每个tensorflow程序的计算过程,而代表不同含义的节点和有向边构成了这个或复杂或简单的图。计算图中的节点有两种形式,一种是运算操作,一种是表示变量。有向边可以看做是节点之间的关系。计算图中的每个节点可以有多个输入和输出,每个节点表示了一种运算操作,节点可以算是运算操作的实例化。由于计算图中的边流动(flow)的数据被称为张量(tensor),所以计算图也被称为tensorflow。
对于一个计算图来说,需要数据(tensor),运算操作(operation)以及边来刻画计算的过程,下面我们结合一个简单的例子来说明如何执行tensorflow的计算过程。
import tensorflow as tf
b = tf.Variable(tf.zeros([100])) # 100维的向量,都初始化为0
w = tf.Variable(tf.random_uniform([784,100],-1,1)) # 784x100的矩阵
x = tf.placeholder(name="x") # 输入的占位符placeholder
relu = tf.nn.relu(tf.matmul(w,x)+b) # Relu(Wx+b)
C =[...]
上面首先定义了两个变量,矩阵w和b,然后将w和x相乘后加上b后使用relu进行又线性到非线性的转换,在此先值得relu是一个函数就行。然后经过一些计算后得到C。那上面的计算图可以用下图来表示:
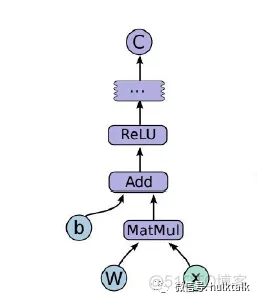
启动图
构造好计算图后,这时候图并没有真正实行,我们需要创建session,在会话中通过传入数据,真正执行图。
如果我们要执行上面的计算图,需要定义一个会话,在会话里启动图。
s = tf.Session()
for step in range(0,10):
input=...construct 100-D input array... #为输入创建一个100维的向量
result=s.run(C,feed_dict={x:input})
实现
为了计算上面的图,我们需要一个client,通过Session的接口与master和多个worker连接。master则负责指导所有的worker,同时与client交互。每个worker可以与多个硬件设备相连。tensorflow目前支持的硬件设备包括x86架构的cpu、手机的ARM CPU、GPU、TPU(Tensor Processing Unit, goole开发的深度学习定制芯片)。tensorflow实现了单机和分布式两种模式。其中单机模式是指client、master以及worker全部在一个机器上的一个进程。而分布式模式允许client、maste和worker在不同机器的不同进程上。下图是两种模式的示意图:

当只有一个硬件设备的时候,计算图会按照依赖的关系依次执行,但是如果遇到多个设备的时候,tensorflow使用代价估计策略和用户指定策略来分配设备。此外不同设备可能涉及到交换数据和通信,tensorflow也有很好的方法来进行数据传输和通信,在此就不展开。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















