















































软件

产品


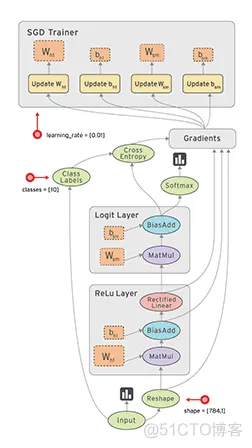
为了形象的理解神经网络,我们提出了层的概念,虽然这更加的形象了,但同时也给初学者带来了很多困扰和不太理解的地方,主要就是在涉及到代码的时候。
层的责任可以理解为三个,一是从某个地方拿到需要用于运算的数据;二是对这些数据进行运算;三是将运算的结果经过处理后输出到其他地方。那么取数据的地方和输出的地方是哪里呢?其实就是某些变量。
标准的神经网络分为三种层,分别为输入层(input layer)、隐藏层(hidden layer)和输出层(output layer)。
输入层:从我们自定义的变量中取得数据,将数据进行矩阵运算,再应用于激活函数,接着将结果存入到变量
隐藏层:从输入层输出的变量中获取数据,并进行运算和使用激活函数后,将结果输出到变量供下一个隐藏层使用,此过程根据你定义的隐藏层的层数会迭代执行多次。
输出层:从最后个隐藏层的输出变量中获取数据,经过运算和使用激活函数后,根据业务需要得到对应个数的输出结果。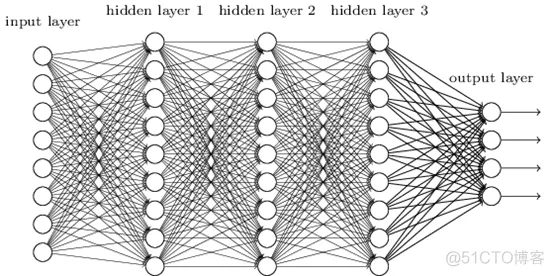
对于神经网络,在处理字符等类型数据的时候,我们首先需要将字符数字化,然后再作为训练的数据输入网络进行训练。如何将字符数字化,根据自己的需要可以采用多种方案,比较常见的方案是采用one-hot编码,以及参照这种思想自定义的其他格式。在神经网络中,我们对字符数字化都是将字符或词语编码成向量,如果采用one-hot,词向量的大小一般由字符的个数来决定。
如果我们对“我们在这里很好”这句话进行one-hot编码,首先将这句话分为:“我们”、“在”、“这里”、“很好”四个词语,然后对每个词语进行one-hot编码,编码后的格式可能为:[[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]]。不难发现,one-hot编码的思想等同于每个词语依次分别放到表格的每列里面,表示哪个词语就将词语所在的列设置为1,其它列则设置为0。
在实际使用的场景下,我们可以参照这种思想来对输入的数据进行变换,我们可以根据词语的重要性使用不同的编号,例如上面如果“我们”比其他的都重要,那么可以将“我们”设置编号为3,则得到的向量就为:[[3,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]]
在此我们引出第一个变量input_vec_size,该变量定义每个词向量的大小,在这里就是4。
训练的数据在进行训练前需要先将其批量化处理,批量化的方法下面举例说明。我们对下面的歌唱进行批量化:“西边的太阳快要落山了, 微山湖上静悄悄。 弹起我心爱的土琵琶, 唱起那动人的歌谣”
为了方便演示我们把里面的标点符号去掉,同时字符数字化的操作也省略掉,后面看到的这些词就当作是已经是数字化后的结果。
接下来我们先认识下几个变量:
[
[西,边,的,太,阳,快,要,落,山,了,微,山,湖,上,静,悄,悄]
[弹,起,我,心,爱,的,土,琵,琶,唱,起,那,动,人,的,歌,谣]
]
接着我们根据num_steps来分割每一行,得到如下格式:
西边的 | 太阳快 | 要落山 | 了微山 | 湖上静 | 悄悄
弹起我 | 心爱的 | 土琵琶 | 唱起那 | 动人的 | 歌谣
如此一来,每次输入到神经网络的数据就是一个小的二维数组的batch数据,如:
[
[西,边,的]
[弹,起,我]
]
我们再将每个字进行向量化,得到如下结果(input_vec_size=6)
[
[[1,0,0,0,0,0],[0,1,0,0,0,0],[0,0,1,0,0,0]]
[[0,0,0,1,0,0],[0,0,0,0,1,0],[0,0,0,0,0,1]]
]
这个三维的矩阵([batch_size,num_steps,input_vec_size])就是LSTM的训练输入。
数据的批量化示例图如下: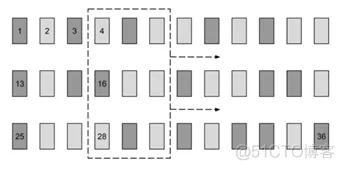
注:输入的矩阵可以是[batchsize,numsteps,inputvecsize]或[numsteps,batchsize,inputvecsize]。由于tf.nn.dynamicrnn函数的参数timemajor默认值为False,所以默认输入格式是[batchsize,numsteps,inputvecsize];如果使用[numsteps,batchsize,inputvecsize]效率会稍微高一点,因为内部的计算也会转换成这个结构。同时请注意,隐藏层输入的是什么结构,最终隐藏层输出的结构也一致。
1,初始化对象
def __init__(self,batch_size,num_steps,input_vec_size,num_classes,lstm_size,num_layers,is_training=True,
learning_rate=0.001,grad_clip=5):
print("--tensorflow version:", tf.__version__)
print("--tensorflow path:", tf.__path__)
#batch的大小和截断长度
self.batch_size = batch_size
#等同其他地方的time_steps
self.num_steps = num_steps
#词向量大小(等同其他地方的input_size) embedding_size
self.input_vec_size = input_vec_size
#输出的类型数(词数)
self.num_classes = num_classes
#LSTM隐藏层神经元数:num_units,hidden_size
self.lstm_size = lstm_size
#LSTM隐藏层层数
self.num_layers = num_layers
#是否是训练状态
self.is_training = is_training
#学习率
self.learning_rate = learning_rate
#梯度裁剪
self.grad_clip = grad_clip
2,构建输入数据(实际数据占位符,变量)
def build_inputs(self,batch_size, num_steps, input_vec_size, num_classes):
# 输入定义数据占位符(TensorFlow默认使用GPU可能导致参数更新过慢,所以建议参考项目中的代码,尤其在定义Variables时注意要绑定CPU)
with tf.device("/cpu:0"):
# 输入的词矩阵,维度为batch_size * num_steps * input_vec_size
inputs = tf.placeholder(tf.float32, shape=(batch_size, num_steps, input_vec_size), name='inputs')
#预期输出 batch_size * num_classes
labels = tf.placeholder(tf.float32, shape=(batch_size, num_classes), name='labels')
#节点不被dropout的概率
keep_prob = tf.placeholder(tf.float32, name='keep_prob')
return inputs,labels,keep_prob
3,创建输入层
def build_input_layer(self,input_data, num_steps, input_vec_size, lstm_size):
with tf.variable_scope("input_wb"):
with tf.device("/cpu:0"):
input_wight = tf.Variable(tf.truncated_normal([input_vec_size, lstm_size]))
input_bias = tf.Variable(tf.zeros([lstm_size, ]))
tf.summary.histogram("input_weight",input_wight)
tf.summary.histogram("input_bias", input_bias)
#首先将向量转换为矩阵
inputs_data = tf.reshape(input_data, shape=[-1, input_vec_size])
#执行运算
rnn_inputs = tf.matmul(inputs_data, input_wight) + input_bias
#add 将输入运用sigmoid激活函数
#rnn_inputs = tf.nn.sigmoid(rnn_inputs)
#将数据再转换为隐藏层需要的格式 [batch_size,num_steps,lstm_size]
self.rnn_inputs = tf.reshape(rnn_inputs, shape=[-1, num_steps, lstm_size])
return self.rnn_inputs
4,构建隐藏层
def build_lstm_layer(self,lstm_size, num_layers, batch_size, keep_prob):
lstm_cell = tf.nn.rnn_cell.LSTMCell(lstm_size, state_is_tuple=True)
with tf.name_scope('dropout'):
if self.is_training:
# 添加dropout.为了防止过拟合,在它的隐层添加了 dropout 正则
lstm_cell = tf.nn.rnn_cell.DropoutWrapper(lstm_cell, output_keep_prob=keep_prob)
tf.summary.scalar('dropout_keep_probability', keep_prob)
#堆叠多个LSTM单元
stacked_lstm = tf.nn.rnn_cell.MultiRNNCell([lstm_cell for _ in range(num_layers)], state_is_tuple=True)
#初始化 LSTM 存储状态.batch_size,stacked_lstm.state_size
initial_state = stacked_lstm.zero_state(batch_size, tf.float32)
return stacked_lstm, initial_state
5,构建输出层
'''
构造输出层,与LSTM层 进行全连接
:param lstm_output lstm层的输出结果,[batch_size,num_steps,lstm_size]
:return:
'''
def build_output_layer(self,hidden_output, lstm_size, num_classes):
with tf.variable_scope("softwax"):
softmax_w = tf.Variable(tf.truncated_normal([lstm_size,num_classes]))
softmax_b = tf.Variable(tf.zeros(num_classes))
hidden_output = tf.transpose(hidden_output, [1, 0, 2])
hidden_output = tf.gather(hidden_output, int(hidden_output.get_shape()[0]) - 1)
#计算logits
logits = tf.matmul(hidden_output,softmax_w) + softmax_b
#输出层softmax返回概率分布
softmax_out = tf.nn.softmax(logits,name='predictions')
return softmax_out, logits
注意:下面的方式可以实现“多目标”的场景
def build_output_layer(self,hidden_output, lstm_size, num_classes):
with tf.variable_scope("output_wb"):
with tf.device("/cpu:0"):
output_w = tf.Variable(tf.truncated_normal([lstm_size, num_classes]))
output_b = tf.Variable(tf.zeros(num_classes))
tf.summary.histogram("output_weight", output_w)
tf.summary.histogram("output_bias", output_b)
# 将输出的维度进行转换(B,T,D) => (T,B,D)
hidden_output = tf.transpose(hidden_output, [1, 0, 2])
#这里取最后个num_steps得到的数据
hidden_output = tf.gather(hidden_output, int(hidden_output.get_shape()[0]) - 1)
#计算并得出结果
output_vec = tf.matmul(hidden_output, output_w) + output_b
#预测结果
product = tf.nn.sigmoid(output_vec)
return output_vec, product
6,构造损失(成本)函数
def build_loss(self,output_vec, labels):
#根据logits和labels计算损失。
#logits:[batch_size,num_classes]; labels:[batch_size,num_classes]
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(
logits=output_vec, labels=labels))
return loss
注意:下面的方式可以实现“多目标”的场景
def build_loss(self,output_vec, labels):
# 根据output_vec和labels计算损失。
#output_vec 未经过sigmod或softmax处理的输出
#logits:[batch_size,num_classes]; labels:[batch_size,num_classes]
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits=output_vec, labels=labels))
return loss
7,构造优化器
def build_optimizer(self,loss, learning_rate, grad_clip):
# 构造加速训练的优化方法
with tf.name_scope('train'):
optimizer = tf.train.AdamOptimizer(learning_rate)
'''
optimizer = tf.train.AdadeltaOptimizer(learning_rate)
optimizer = tf.train.AdagradOptimizer(learning_rate)
optimizer = tf.train.FtrlOptimizer(learning_rate)
optimizer = tf.train.RMSPropOptimizer(learning_rate)
'''
#optimizer.apply_gradients(zip(grads,tvar))
#该函数是简单的合并了compute_gradients()与apply_gradients()函数,返回为一个优化更新后的var_list
#如果global_step非None,该操作还会为global_step做自增操作
train_op = optimizer.minimize(loss)
return train_op
8,定义精准度评估函数
'''
定义计算模型预测结果准确度
'''
def accuracy_eval(self, product, y):
correct_pred = tf.equal(tf.argmax(product, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
return accuracy
9,构建模型
def build_model(self):
self.inputs, self.labels = self.build_inputs(self.batch_size, self.num_steps, self.input_vec_size, self.num_classes)
#输入层
rnn_inputs = self.build_input_layer(self.inputs, self.num_steps, self.input_vec_size, self.lstm_size)
#隐藏层
stacked_lstm, self.initial_state = self.build_lstm_layer(self.lstm_size, self.num_layers, self.batch_size, self.keep_prob)
hidden_output, self.final_state = tf.nn.dynamic_rnn(stacked_lstm, rnn_inputs, initial_state=self.initial_state)
#输出层
output_vec, self.predict = self.build_output_layer(hidden_output, self.lstm_size, self.num_classes)
if self.is_training :
# 使用损失函数
self.loss = self.build_loss(output_vec, self.labels)
#使用优化器
self.train_op = self.build_optimizer(self.loss, self.learning_rate, self.grad_clip)
return self.predict
10,将字符批量化
'''return 可迭代的元祖
x:[batch_size,num_steps,input_vec_size]的X训练数据
y:[batch_size,num_classes]
'''
def get_batches(batch_size,num_steps,input_vec_size):
n_batches = 12 #通过计算得出的批量数
for num in range(n_batches):
yield x, y
11,训练和保存模型
class Training:
def __init__(self, batch_size, num_steps, input_vec_size, num_classes, lstm_size, num_layers,epoch_size=1000,
learning_rate=0.001, keep_prob=0.75,grad_clip=5, checkpoint_dir='./checkpoints/v2',log_dir='./logs/v2'):
self.epoch_size = epoch_size
self.keep_prob = keep_prob
#检查点文件的存放目录
self.checkpoint_dir = checkpoint_dir
self.log_dir = log_dir
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
#训练轮数计数器变量(不需要被训练)
self.global_step = tf.Variable(0,name='global_step',trainable=False)
#创建模型
self.model = SitePrectModel(batch_size=batch_size, num_steps=num_steps, input_vec_size=input_vec_size,
num_classes=num_classes, lstm_size=lstm_size, num_layers=num_layers,
learning_rate=learning_rate,is_training=True,grad_clip=grad_clip)
self.model()
#初始化或重新加载会话
self.init_or_load_session()
#加载数据
self.data_util = DataUtil(batch_size)
def __call__(self, *args, **kwargs):
print('start training')
self.summary_writer = tf.summary.FileWriter(self.log_dir,tf.get_default_graph())
self.summary_log = tf.summary.merge_all()
self.current_epoch = 0
self.counter = 0
for epoch in range(self.epoch_size):
print('>>>>>>>训练轮数:{}'.format(epoch))
self.current_epoch = epoch
state = self.sess.run(self.model.initial_state)
batches = self.data_util.get_batches()
for x, y in batches:
self.counter += 1
state, product = self.optimization(x,y,state)
if self.counter % 20 == 0:
feed_dict = {self.model.inputs: x,
self.model.labels: y,
self.model.keep_prob:1.}
accuracy = self.sess.run(self.model.accuracy,feed_dict=feed_dict)
if (epoch+1)%100 == 0:
self.evaluation()
self.evaluation()
print('training end')
'''
初始化或加载Session
'''
def init_or_load_session(self):
self.sess = tf.Session()
self.saver = tf.train.Saver()
ckpt = tf.train.latest_checkpoint(checkpoint_dir=self.checkpoint_dir)
if ckpt:
print('restore session from ',ckpt)
self.saver.restore(self.sess, ckpt)
else:
print('initialize all variables')
self.sess.run(tf.initialize_all_variables())
def evaluation(self):
self.saver.save(self.sess,self.checkpoint_dir+'/model{}.ckpt'.format(self.current_epoch),
global_step=self.global_step)
def optimization(self,batch_x,batch_y,state):
feed_dict = {self.model.inputs: batch_x,
self.model.labels: batch_y,
self.model.keep_prob: self.keep_prob,
self.model.initial_state:state}
final_state, train_op, batch_loss, product,summary_log = self.sess.run([self.model.final_state,
self.model.train_op,
self.model.loss,
self.model.product,
self.summary_log],
feed_dict=feed_dict)
if self.counter % 100 == 0:
self.summary_writer.add_summary(summary_log, self.current_epoch)
print('训练误差: {:.4f}... '.format(batch_loss))
return final_state,product
12,开始训练
#训练模型
batch_size = 4 # 单个batch中序列的个数
num_steps = 1 # 单个序列中的字符数目
input_vec_size = 151 # 隐层节点个数,输入神经元数(单词向量的长度)
num_classes = 30 # 输出神经元数(最后输出的类别总数,例如这的基站数)
lstm_size = 160
num_layers = 6 # LSTM层个数
learning_rate = 0.0001 # 学习率
#feed in 1 when testing, 0.75 when training
keep_prob = 0.75 # 训练时dropout层中保留节点比例
epoch_size = 100 # 迭代次数
training = Training(batch_size=batch_size, num_steps=num_steps, input_vec_size=input_vec_size,
num_classes=num_classes, lstm_size=lstm_size, num_layers=num_layers,
learning_rate=learning_rate,epoch_size=epoch_size)
training()
tensorboard --logdir=./logs/v2
http://localhost:6006/
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















