一、背景

搜索和推荐是互联网应用的两个核心入口,大多数流量都来自于搜索和推荐这两个场景。京东零售按站点,分为主站、京喜、海外站以及一些垂直领域站点。
对于搜索业务来讲,每个站点下会有关键词搜索、下拉发现、以及店铺、优惠券、订单等细分页面的搜索;对推荐业务来讲,依照应用场域不同,划分了大大小小几百种推荐位。
以上每一种业务场景下,都包含了十多种策略环节,需要机器学习模型支持。基于海量的商品数据、海量的用户行为,作为机器学习的特征样本。
除了搜推广领域中典型的意图识别、召回、排序、相关性模型以外,京东搜索推荐为了更好的维护用户、商家、平台这三方的生态,在智能运营、智能风控、效果分析这些环节,也越来越多的引入模型进行决策。
二、京东搜索推荐机器学习现状

我们依据服务场景和服务时效的差异,将这些机器学习场景进行分成了三类:
- 一种模型是在用户访问搜索或推荐页面时,即时请求到的商品召回、排序、意图识别等模型, 这类模型在服务层面对响应时间要求极高,预估服务位于在线系统中。
- 另一种模型是对服务响应时间要求不高,但对模型的训练和预估有一定的时效性要求,比如实时用户画像、实时反作弊模型,这里我们把它称作是近线场景。
- 第三种是纯离线的模型场景,比如商品或用户的长期画像、针对于各种素材标签的知识图谱, 这些场景的训练和预测对时效要求相对较低,全在离线环境下进行。
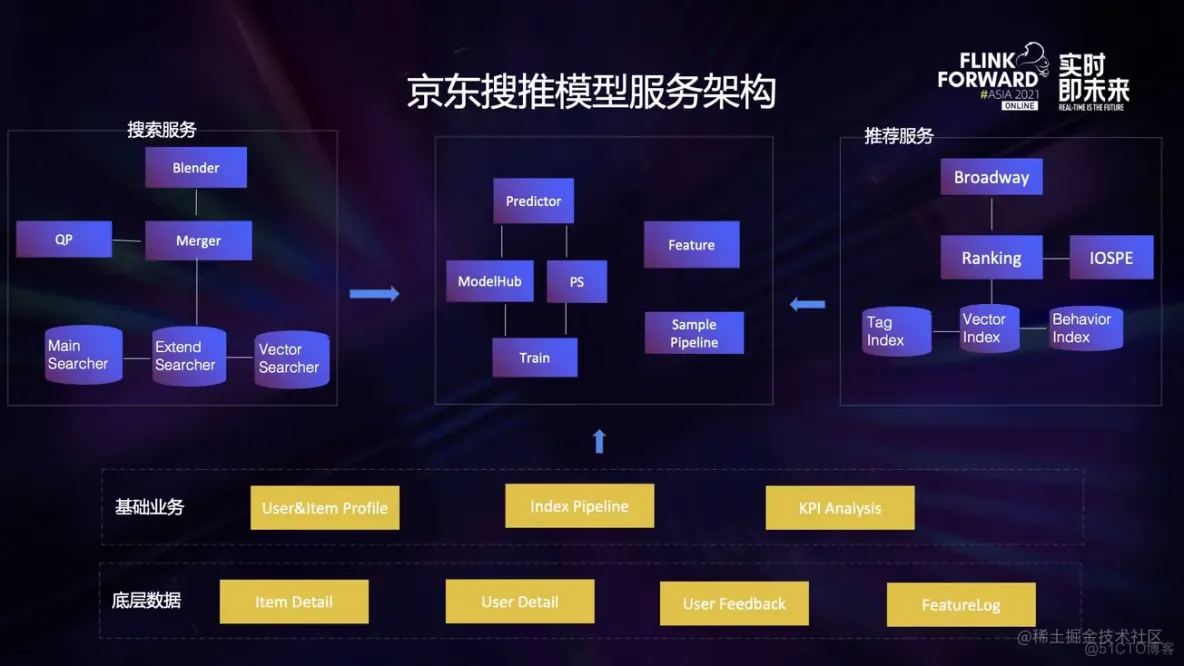
我们来看下当前主要的模型服务架构是怎么样的:
京东搜索和推荐系统由于业务系统本身的差异,分别由不同的 kernel 链式模块,组成为搜索系统和推荐系统。
一次用户搜索,会逐级请求链路上的各级服务,先对关键词过 QP 服务,走意图识别模型;再由召回服务并行请求各路的召回,会依次调用召回模型、相关性模型、粗排模型;然后排序服务汇总结果集后,会调用精排模型、重排模型等。
一次用户访问推荐的业务过程,有一些差异,但整体上流程比较接近。
这两个大业务下层,会共享一些离线、近线基础用途的模型,比如用户的画像、素材标签、各种指标分析。
他们访问的模型服务架构,都由训练 + 预估两部分组成,中间由模型仓库和参数服务桥接起来;特征方面,在线场景需要特征服务器,离线场景则由数据链路组成。

从模型形态上,我们可以把现有模型划分成两种形态:
- 左侧一类模型,单体规模相对复杂,采用数据并行的形式对同一组参数进行训练,使用自研参数服务器对超大规模稀疏参数进行训练,训练和预估的架构相互分离。
- 右侧一类模型,单体模型相对简单,数据量和业务粒度繁多,按不同业务粒度进行数据划分,分别建模,由流式计算框架来驱动数据流转,做到训练和预估的架构一体。
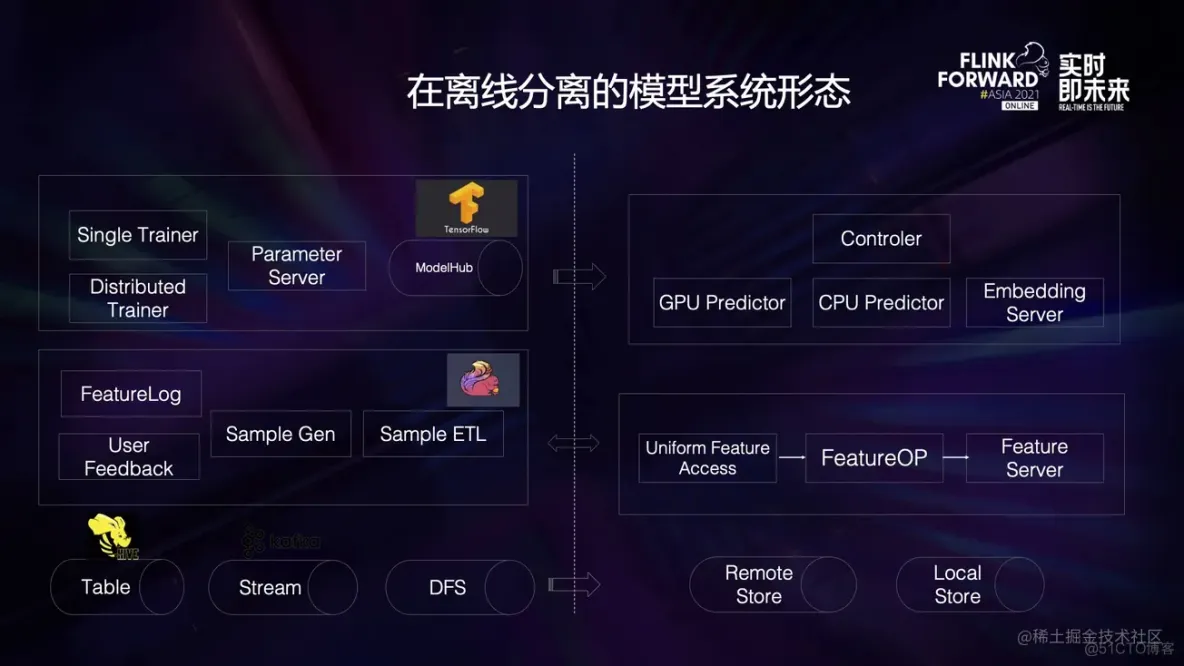
基于在线服务和离线训练的架构差异,多数模型系统会是这种在线和离线分离的系统形态。 训练过程是基于 Tensorflow、Pytorch 进行一层封装。
样本生产和预处理,是基于 Flink 构建出的样本链路框架,其中很多在线业务的特征,源于线上服务的 Featurelog 特征日志;模型训练和样本生产构成了离线部分, 依赖一些公共的基础组件比如 Hive、Kafka、HDFS;预估过程基于自研的预估引擎,在 CPU 或 GPU 上进行 Inference 计算,大规模稀疏向量由独立的参数服务器提供;特征服务为预估过程提供输入数据,也是由自研的特征服务构成,由于预估时特征来源和训练时不同,有一层统一的特征数据获取接口,以及对应的特征抽取库。
特征抽取和模型预估构成了在线部分和离线部分分离。

在模型迭代的形态上,对时效有较高要求的模型,一般是先离线使用历史累积的批式数据训练得到 Base 模型,部署上线之后,继续用实时数据流样本在其基础上持续的训练和迭代上线。
由于预估和训练在两套架构下,持续迭代的过程就涉及两套架构的交互、数据传递,以及一致性方面的要求。
训练以及预估需要结合数据状态,自主实现容错转移、故障恢复的能力。 如何将数据的分布式处理和模型的分布模式结合为一个整体,便于部署和维护,也是一个不易实现的功能。对不同模型,加载和切换预训练参数的模式也难做到统一。
三、基于 Alink 实现在线学习

首先,我们来分析一下在线学习系统的痛点:
- **离线/流式训练架构难以统一:**典型的在线学习首先由离线的大批数据训练出一个模型作为 basic model,之后在这个 basic model 的基础上持续的进行流式训练,但是这个链路下流式训练和离线训练是两套不同的系统、代码体系,比如说,一般 offline train 和 online train 是两套不同的架构体系。offline 的训练可能是一个普通的离线任务,在线的训练可能是单机启动的一个持续的训练任务,这两种任务系统不同、体系不同,甚至如果在线训练是用 Spark/Flink 跑的话,可能代码本身也不同。
- **数据模型:**上述讲到了整个训练架构难以统一,因此,一个业务引擎里面用户需要维护两套环境、两套代码,许多共性不能复用,数据的质量和一致性很难保障;且流批底层数据模型、解析逻辑可能不一致,导致我们需要做大量的拼凑逻辑,甚至为了数据一致性需要做大量的同比、环比、二次加工等的数据对比,效率极差,并且非常容易出错。
- **预估服务:**传统的模型预估都是需要部署一个单独的模型服务,然后由任务以 http/rpc 形式去调用来获取预估结果,但是这种模式需要多余的人力去维护服务端,且实时/离线预估场景下 rpc/http server 并不需要一直存在,它们只需要随着任务的开始而开始,随着任务的结束而结束就可以了;且离线训练出来的模型如何服务于在线又是一个令人头疼的问题。
- **模型升级:**模型任何形式的升级都会对模型带来一定的影响,在这里,我们主要讨论模型的升级对模型参数丢失带来的影响。
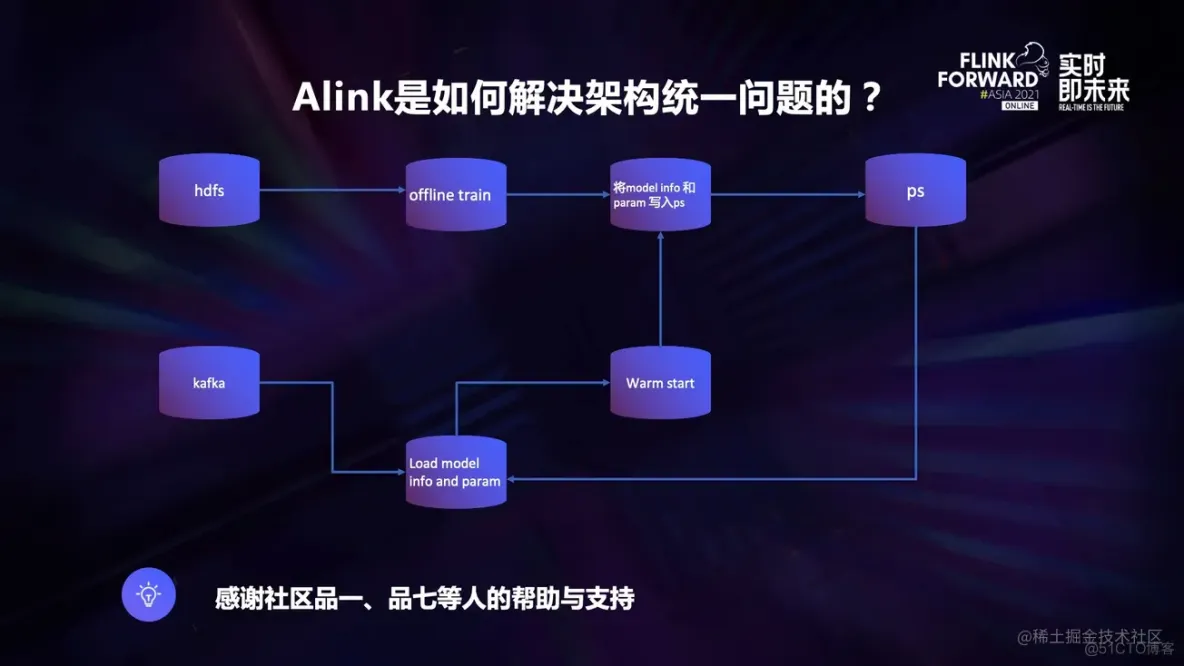
这是一个简单的在线学习的经典流程图,下面我来解释一下这个流程图在 Alink 链路是如何实现的:
- **离线训练任务:**该 Alink 任务去 hdfs load 训练数据,先将训练数据进行特征工程等的加工之后,将模型进行离线的训练,训练完成之后将 model info 和模型参数数据写入 parameter server,该任务天级运行,每次运行训练比如说 28 天的数据。
- **实时训练任务:**实时任务方面,该 Alink 任务从 kafka 读取样本数据,将样本数据进行一 定积累之后比如说小时级、分钟级、条数等进行小批量的训练,先去 parameter server pull 模型参数和超参数据,load 模型之后如果有预估需求的话,可能进行一次 predict,如果没有预估需求,可以直接进行模型训练,并且将训练之后的模型数据 push 给 parameter server。

接下来我们主要来看看实时学习的模型如何服务于在线预估的场景:
- 首先,实时的训练肯定不会影响模型结构的,即实时训练只会影响模型参数的更新;
- 第二,预估和训练的 ps 肯定是要分开的,因此,这个问题就变成了如何去同步预估和训练的 ps 的数据。
在这里业界大概有两种实现方案:
- 方案 A:这个是针对一些小模型的训练,可以让 Alink 的任务直接将训练好的参数同时 push 给离线 PS 和在线 PS 。
- 方案 B:引入一个类似 PS controller 的角色,该角色负责计算参数,同时将参数同时 push 给离线 PS 和在线 PS。
不过,我们也可以让 Alink 的训练任务写训练 PS,同时构造一个类似 ps server 的角色来同步参数,将 server 的更新同时写一个类似 kafka 的队列,启动一个预估 ps server 消费 kafka 队列 里面的参数信息,这样做到训练 PS 和预估 PS 之间的一个数据同步。
方案很多,选择自己合适的就好了。

下面我们来先看一下模型版本升级为什么会带来的参数丢失:
- 假设 1 号凌晨的时候训练的前 28 天的数据,训练完了之后将参数写入了参数服务器,1 号到 2 号之间一直在流式的训练,一直在增量写参数服务器,一直到 2 号凌晨。
- 2 号凌晨的时候开始训练前 28 天的数据,假设训练时间为 1h,此时如果直接写入 PS 的话,那么该 1h 的数据将被直接覆盖,对于一些时间不敏感的模型倒也还好,至少不会报错。 但是对于该业务里面 prophet 时间序列模型来说会出问题,因为该模型参数少了 1h 的数据, 模型可能会因此降级准确度。
其实总结起来就是模型迭代的时候,由于离线训练完成需要一定时间,如果直接覆盖的话,会造成这段时间的参数丢失。因此,我们必须保证 PS 里面的参数在时间上是连续的。
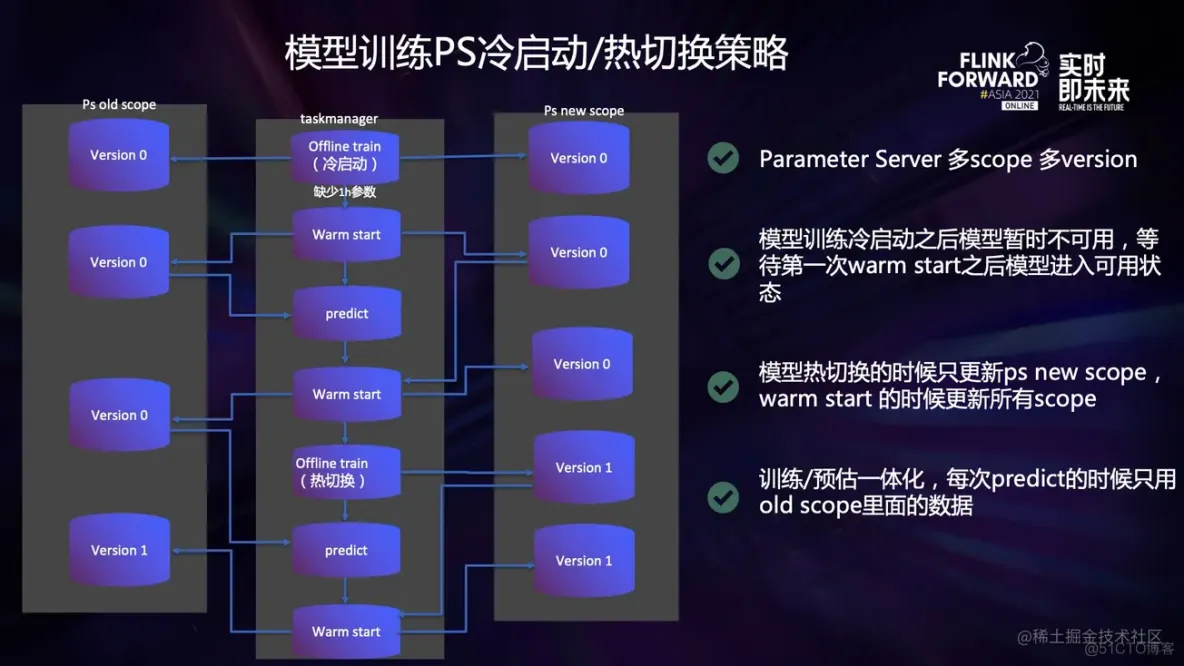
这个图里面我们主要介绍了 PS 冷启动和热切换的流程:
- 模型训练冷启动之后因为参数丢失问题模型暂时不可用,等待第一次 warm start 之后模型进入可用状态;
- Parameter Server 支持多 scope 多 versiion,模型热切换的时候只更新 ps new scope,warm start 的时候更新所有 scope;
- 模型每次 predict 的时候都只 pull old scope 的数据,进行 warm start 的时候 pull new scope 。
下面详细接受一下整个链路的流程:
- 冷启动的时候因为离线的任务训练模型需要一定时间,因此,这时候 PS 里面的参数缺少了该时间段的数据,所以只能先进行 warm start 将参数补全,并写入 PS old scope 和 PS new scope;
- 之后进行正常的预测和 warm start 过程,其中 predict 的时候只 pull ps old scope,因为 ps new scope 里面的数据会再热切换的时候被覆盖造成参数丢失,丢失参数的 ps 不能进行预测;
- 等到第二天凌晨的时候进行热切换,只更新 ps new scope;
- 之后正常 pull ps old scope 进行 predict,pull ps new scope 进行 warm start 的流程。

接下来我来介绍一下流式训练的痛点:
- 对于在线的训练不支持 failover。大家应该都知道,在线训练难免会因为各种各样的原因 (比如网络抖动) 中断,这种情况下,合适的 failover 策略是非常重要的。我们将 Flink 的 Failover 策略引入我们自研的模型训练算子,进而支持模型的 Failover。
- 合适的 pretrain 策略:任何模型的训练 embedding 层都是不需要每次从 PS 里面 pull 的, 一般业界会自研一些类似 local ps 的形式来在本地存储这些稀疏向量,当然我们也可以将这些 local ps 引入到 Flink 内部来解决这个问题,但是对于 flink 来说,我们在一些场景下完全可以用状态后端来代替 local ps。利用 Flink 的 state 和 parameter server (参数服务器) 融合,init 或者是 failover 的时候将 parameter server 的部分热数据 load 到 state 里面对模型进行 pretrain。
- 很难实现分布式的需求。如果是一些本身是支持分布式的架构倒还好,但是有一些算法本身是不支持分布式的 (比如 facebook 开源的 prophet),在这种情况下如果数据量大而且还不用分布式的话,跑完一大批数据可能会极其耗费时间;Alink 天然支持分布式,Alink 是基于 Flink 的上层算法库,因此,Alink 具有 Flink 所有的分布式功能,支持 Flink Master 的所有调度策略,甚至可以支持各种精细的数据分发策略。
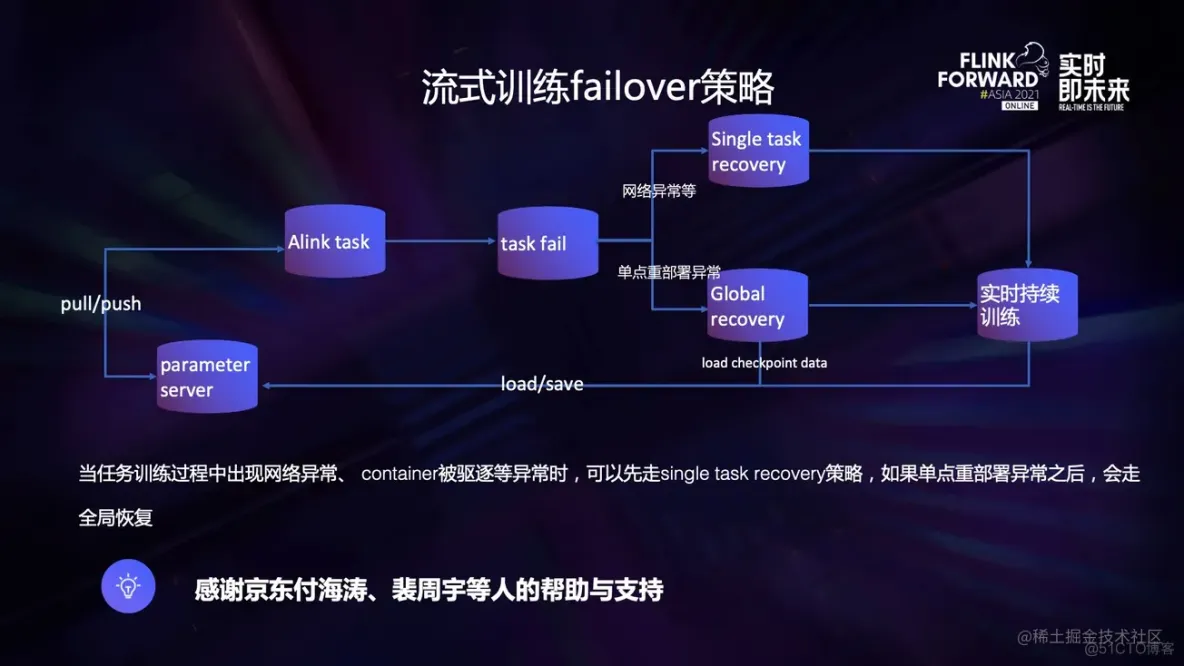
流式训练的 failover 策略:
在线分布式训练的时候经常会有某台机器因为某些原因 (如网络) 异常的情况,这种情况下如果要恢复一般有两种情况:
- 允许数据丢失
一般的训练任务都是允许少量数据丢失的,因此我们希望可以牺牲一些数据进而换来整体任务的持续训练,引入局部恢复的策略可以大大提高任务的持续性,避免了任务因为一些外部原因造成的单点故障而全部恢复的情况。 - 不允许数据丢失
在这里我们只讨论 at least once 的情况 (exactly once 要求 PS 支持事务),假如说业务对数据的要求比较高,我们可以采取 global failover 的策略,当然了,一般单点重部署异常的情况下也会走 global failover 的策略在该业务中,我们采用局部恢复的策略来优先保证任务的持续训练。
下面详细介绍一下训练任务的重启的时候策略:
- global recovery。这里就是 Flink 里面常用的 Failover 的概念,不再过多赘述。
- singal task recovery。在该情况下某个 taskmanager 因为网络异常出现了心跳超时,此时为了保证数据一致性,Flink 任务会发生 failover 并且从上次的 checkpoint 恢复,但是如果允许少量的数据丢失且为了保证任务的持续输出,可以开启局部恢复,此时任务只会重启该 taskmanager,可以保证训练的持续性。
- 单点重部署异常。如果任务出现了任何原因的故障,导致任务单点恢复的过程中出现了异常导致单点恢复失败,这种时候就发生了单点重部署异常,该异常无法解决,只能通过将任务 failover 来解决问题,此时可根据任务需要配置从 checkpoint 恢复或者是不恢复持续训练。
- 这里我着重介绍一下任务 failover 的时候从 checkpoint 恢复的场景:任务 fail 的时候首先执行 save 方法,将当前 PS 的状态 snapshot 保存起来,将 Flink 状态后端的数据也保存起来,任务恢复的时候执行 load 方法,将 PS 恢复。仔细想可以发现,该操作会造成部分参数的重复训练 (cp 的时间点和 save 的时间点不一致),希望大家注意。

基于 Alink 的流式训练 pretrain 策略大致可分为冷启动、全局恢复和单点恢复三个模式:
- 冷启动的时候大概是先从 PS 里面 pull 模型参数和超参信息,然后初始化 ListState、 MapState、ValueState 等状态后端,同时初始化 PS 的 scope 和 version 信息。
- 全局恢复也就是 Flink 默认的 Failover 策略,在该模式下任务首先会 save model,即将 PS 里面的模型信息序列化至硬盘上,之后 save flink 任务里面的状态后端的数据,然后初始化的时候就不需要再 pull 超参等信息了,而是直接选择从状态后端恢复超参,并且 reload 模型的 参数进行持续的训练。
- singal task recovery,该模式是允许少量的数据丢失且为了保证任务的持续输出才会采取的,在该模式下任务只会重启该 tm,可以最大程度的保证训练任务的稳定持续训练。

- 当前比较流行的 3D 并行、5D 并行架构里面,数据并行是最基础也是最重要的一个环节。
- Flink 最最基础的数据分发策略有包括 rebalence、rescale、hash、broadcast 等的多种选择, 且用户可以通过实现 streampartitioner 自由的控制数据的分发策略,用户可以通过 load balance 等自由的实现数据并行来解决数据倾斜带来的模型参数间互相等待的问题。
- 在该模式下,我们打通了 Alink 模式下分布式调用 python 方法的通路,可以最大程度的提高数据并行的效率。
- 数据并行是忽略流、批的,我们集成 Alink 的 mapper 组件,实现了 train 和 update model variable 批流一体化。
四、Tensorflow on Flink 应用

下面我先介绍一下 Tensorflow on Flink 预估服务和传统的在线预估链路的不同:
- 区别于在线预估,实时/离线预估不需要服务一直存在,且 load 到 tm 内部可以大幅节约人力维护和资源成本。
- 整个链路架构不同导致数据模型、数据处理、模型训练、模型推理等需要分别维护不同的系统和代码结构。
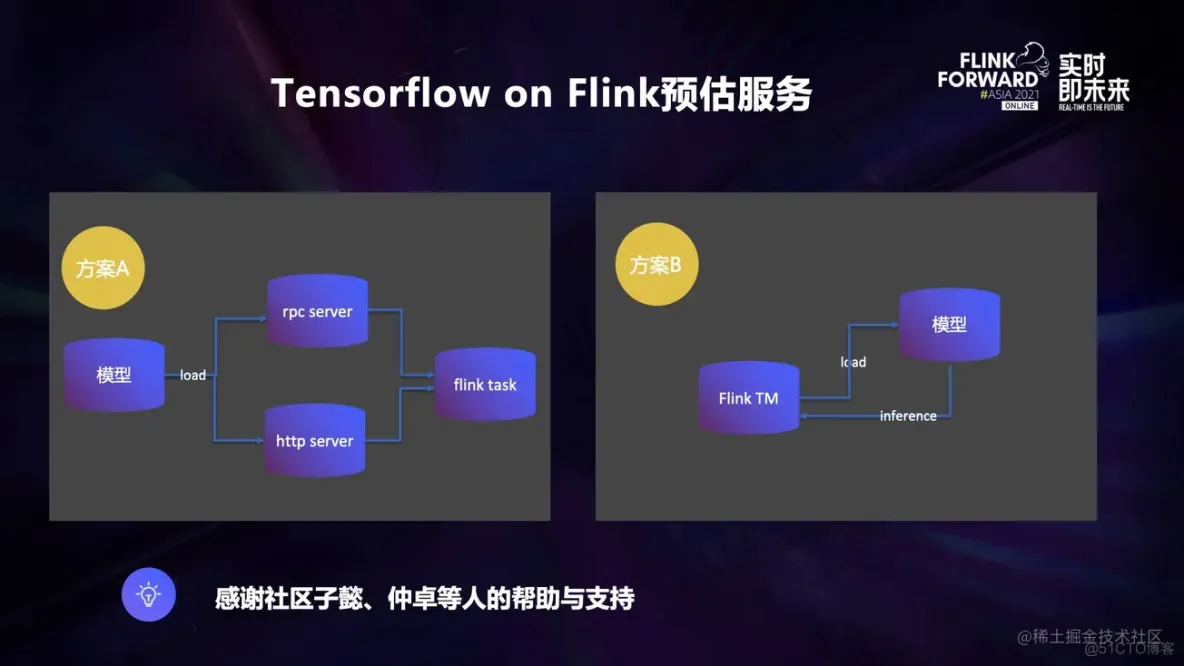
Tensorflow on Flink 预估服务目前有多个方案,比如:
- 方案 A:部署一个 rpc 或者是 http server,用 flink 通过 rpc 或者是 http 以 client 的方式去调用。
- 方案 B:将 Tensorflow 模型 load 到 flink tm 内部,直接调用。
其中方案 A 有如下弊端:
- rpc 或者是 http server 端需要多余的维护人力。
- 实时/离线预估和在线预估不同的点是该 rpc 或者是 http server 端并不需要一直存在, 它们只需要随着任务的开始而开始,随着任务的结束而结束就可以了,一直存在是对资源的浪费,但是如果改成这种架构,那么无疑会更加的耗费人力维护成本。
- 还是上面的架构不统一问题,rpc 或者是 http server 端和实时/离线数据处理往往不是一套系统,这就还是涉及到了之前一直强调的架构不同意问题,不再赘述。
五、规划

- 采用 Flink sql 实现批流一体的模型训练,争取使模型训练更加方便。
- Tensorflow Inference on Flink 实现支持大模型,基于 PS 实现动态 embedding 的存储:搜索、推荐等业务场景中存在大量的 id 类特征,id 类特征通常采用 embedding 的方式,这些特征在特定情况下会急剧膨胀,进而吞掉 taskmanager 的大部分内存,且原生 tensorflow 的 variable 使用起来会有诸如需要预先指定维度大小,不能支持动态扩容等不便,因此,我们计划将内嵌的 Parameter Server 替换为我们自研 PS,支持千亿规模的分布式 serving。
- 将 PS 里面的 embedding 动态 load 到 taskmanager 的 state 里面,实现降低对 PS 访问压力的需求:Flink 内部通常使用 keyby 操作来将某些固定的 key hash 到不同的 subtask 上,因此我们可以将这些 key 所对应的 embedding 缓存到 state 里面,降低对 PS 的访问压力。
六、鸣谢

- 首先感谢京东数据与智能部数据时效 Flink 优化团队的所有同事的帮助与支持。
- 感谢 Alink 社区全部同事的帮助与支持。
- 感谢阿里云计算平台事业部 Flink 生态技术团队所有同事的帮助与支持。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。



















































 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















