















































软件

产品


GcC 脚本之家
喜欢Tensorflow带给我的小时候玩积木的感觉

前言
编译tensorflow遇到的bug本来就多,在Windows平台上bugs更是加大力度。明明官方教程中在配置完环境后只需执行两行bazel命令,第一行命令却产生不少error。笔者踩了不少坑后,总结出了一些解决方法形成此教程。
Tensorflow源码编译bug多一直被广大用户诟病,不同版本对应不同的编译器,gpu版本还需要安装对应的cuda和cudnn库。因此笔者强烈建议先到官网查看编译配置,具体点击下面链接:Build from source on Windows(https://tensorflow.google.cn/install/source_windows)下面列出前5个官方已经测试过的配置:
CPU
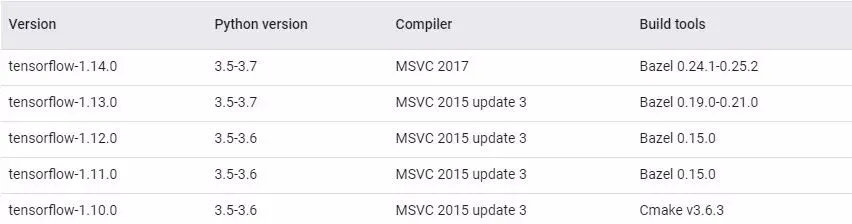
图1.1 tensorflow-cpu的编译配置
GPU
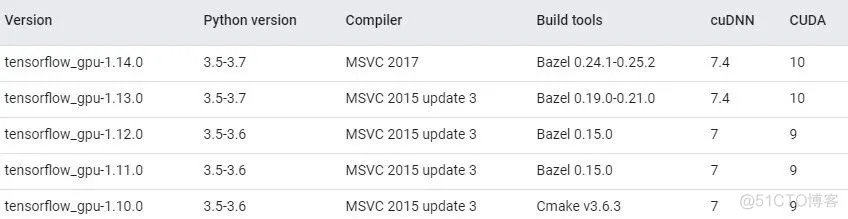
下面列出笔者所使用的编译配置
| 软件 | 版本 |
|---|---|
| Tensorflow源码 | 1.14.0-rc1 |
| Visual Studio | 2019加装msvc2017 |
| Bazel | 0.25.0 |
| msys2 | x86_64-20190524 |
| JDK | 1.8.0_171 |
| Python | 3.5.2Anaconda custom (64-bit) |
| cuda | 9.0.176_win10 |
| cudnn | 9.0-windows10-x64-v7.6.2.24 |
从表中也可以看到,使用了即使用cudnn7.6配合cuda9.0笔者也编译成功了。
02入门Bazel
在开始编译之前,有必要先了解Bazel的基本操作,出现error时才能有一个大概判断。笔者就曾到stackoverflow上问了两个stupid问题。在此笔者只讲Bazel的几个主要的操作或概念。
Tensorflow源码的编译过程产生了大量的缓存,可能占用25G以上的存储空间,而缓存路径默认在C盘。笔者第一次遇到C盘空间不足时,把C盘的Matlab搬出去。折腾几次后老老实实到查看官方文档,才知道可以用<--outputuserroot>指定缓存目录,不过编译过程依然在C盘产生了一些文件占用了几个G。详情可参考Output Directory Layout(https://docs.bazel.build/versions/master/output_directories.html)
BUILD中定义了一些编译的目标,包括其名称、头文件、源文件和依赖库等。在tensorflow-1.14.0-rc0/tensorflow/python/BUILD中定义了大量编译目标,各种算子等等的shared object。比如下面这个
cc_library( name = "numpy_lib", srcs = ["lib/core/numpy.cc"], hdrs = ["lib/core/numpy.h"], deps = [ "//tensorflow/core:framework", "//tensorflow/core:lib", "//third_party/py/numpy:headers", "//third_party/python_runtime:headers", ],)1.编译第三方库numpy。
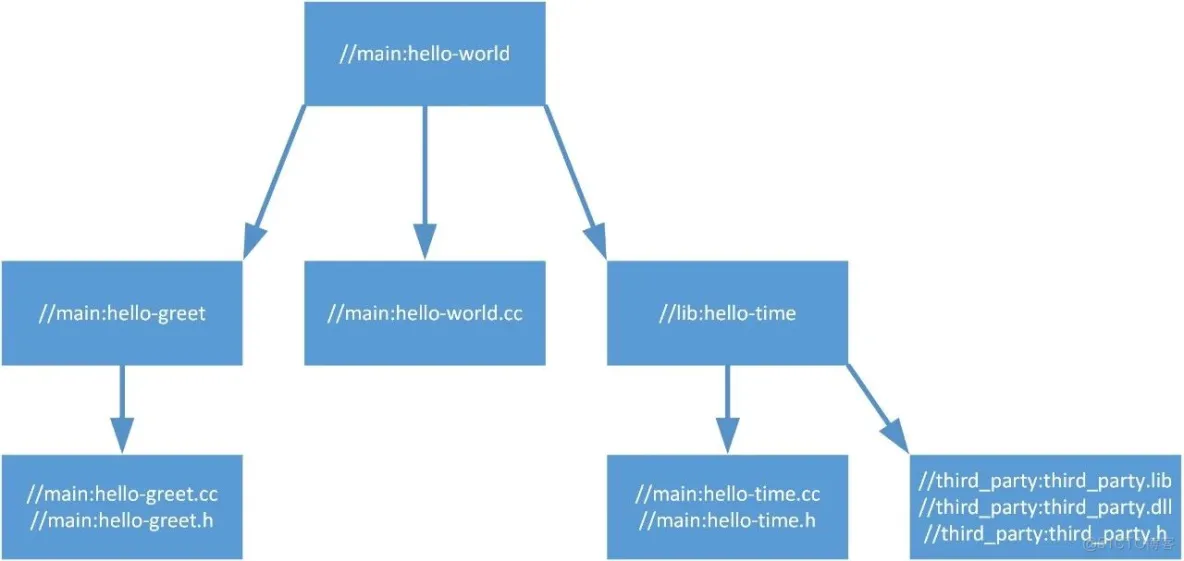
用cc_binary、cc_library 或 cc_import可以编译可执行程序、共享库或导入依赖库。值得一提的是,也可以按需要编译动态链接库脱离Tensorflow源码池建立工程。现在假设有如下文件目录:
└──project0 ├── main │ ├── BUILD │ ├── hello-world.cc │ ├── hello-greet.cc │ └── hello-greet.h ├── lib │ ├── BUILD │ ├── hello-time.cc │ └── hello-time.h ├── dll │ ├── third_party.dll │ ├── third_party.lib │ └── third_party.h └── WORKSPACE1.WORKSPACE用来指定代码根目录。其中BUILD的定义分别为
1.基本的属性有:
| 属性 | 作用 |
|---|---|
| name | 定义目标的唯一标识符或者名称 |
| srcs | 指定源文件 |
| hdrs | 指定头文件 |
| deps | 指定依赖库 |
| visibility | 可用来设定对其他目标的可见性,不常用 |
用一个图简单说明上面四个目标的关系:
接着打开命令行,定位到WORKSPACE文件所在目录,执行
bazel build //main:hello-world1.编译完成后在/bazel-bin/main/hello-world找到编译完成的可执行文件。详情可参考Introduction to Bazel: Building a C++ Project(https://docs.bazel.build/versions/master/tutorial/cpp.html),C / C++ Rules(https://docs.bazel.build/versions/master/be/c-cpp.html)。
完成了上面的内容后,下面才真正开始编译源码。第三节只讲编译操作,编译错误的处理在第四节。
命令行定位到/tensorflow-1.14.0-rc0/,执行
python configure.py1.这个脚本会询问诸如使用哪个路径下的Python、是否要支持cuda、用哪个版本的cuda、是否要支持xla等,读者可根据需要做配置。脚本正常运行后,目录中生成.tf_configure.bazelrc文件,保存了刚才的配置,比如这样:
build --action_env PYTHON_BIN_PATH="D:/Python/Anaconda3/python.exe"build --action_env
PYTHON_LIB_PATH="D:/Python/Anaconda3/lib/site-packages"build --python_path="D:/Python/Anaconda3/python.exe"
build:xla --define with_xla_support=truebuild --action_env TF_NEED_OPENCL_SYCL="0"build --action_env
TF_NEED_ROCM="0"build --action_env TF_NEED_CUDA="1"build --action_env TF_NEED_TENSORRT="0"build
--action_env CUDA_TOOLKIT_PATH="C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v9.0"build
--action_env TF_CUDA_COMPUTE_CAPABILITIES="3.5,7.0"build --action_env TF_CUDA_CLANG="0"build
--config=cudabuild:opt --copt=/arch:AVXbuild:opt --define with_default_optimizations=truebuild
--config monolithicbuild --copt=-w --host_copt=-wbuild --copt=-DWIN32_LEAN_AND_MEAN
--host_copt=-DWIN32_LEAN_AND_MEAN --copt=-DNOGDI --host_copt=-DNOGDIbuild
--verbose_failuresbuild --distinct_host_configuration=falsebuild:v2
--define=tf_api_version=2test --flaky_test_attempts=3test --test_size_filters=small,
mediumtest --test_tag_filters=-benchmark-test,-no_oss,-oss_serialtest --build_tag_filters=-benchmark-test,
-no_osstest --test_tag_filters=-no_windows,-gputest --build_tag_filters=-no_windows,-gpubuild
--action_env TF_CONFIGURE_IOS="0"1.在生成tensorflow-python的whl安装包之前,首先要编译其生成器。使用下面的命令:
CPU版本tensorflow
bazel build --config=opt --output_user_root=f:mpazel //tensorflow/tools/pip_package:build_pip_package1.GPU版本tensorflow
bazel build --config=opt --config=cuda --output_user_root=f:mpazel --define=no_tensorflow_py_deps=true //tensorflow/tools/pip_package:build_pip_package1.编译时,CPU和内存占用可能达到100%,注意电脑散热。此外,如果RAM少于16GB,编译时Win10的UI可能直接卡主,可以在build命令添加--local_ram_resources=2048限制内存使用。而根据CPU主频越高和核数越多,编译耗时越短,笔者的笔记本(i7@2.6Ghz x4)花了十几个小时...... 编译完成后,在tensorflow-1.14.0-rc0/bazel-bin/tensorflow/tools/pip_package中,可以找到build_pip_package.exe,它就是用来生成whl安装包的工具。
利用千辛万苦得到的build_pip_package.exe生成安装包:
bazel-binensorflowoolspip_packageuild_pip_package f:/tmp/tensorflow_pkg1.安装tensorflow-python:
pip3 install f:/tmp/tensorflow_pkg/tensorflow-1.14.0rc0-cp35-cp35m-win_amd64.whl1.成功安装后,怀着激动的心情,做个乘法哈哈
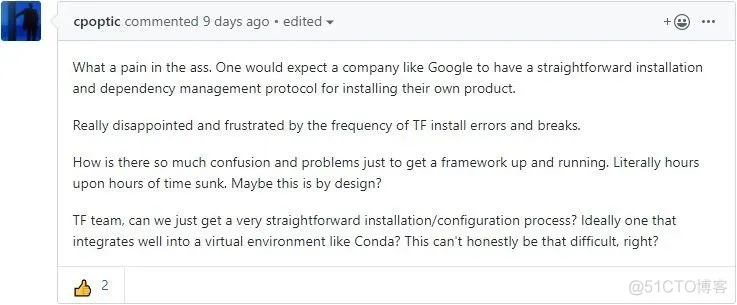
然而实际上编译过程并不是两句cmd命令就可以完成的orz。不知道为什么谷歌一个大公司,把编译搞得这么痛苦。下面是一位暴躁老哥在github issue的吐槽,他用了“What a pain in the ass.”
如果遇到的问题本文找不到,可以到官网找找解决思路Build and install error messages(https://tensorflow.google.cn/install/errors)。
虽然中断编译,只要不bazel clean,都不会编译from scratch,但是依然有些文件重新编译,非常耗时。笔者花了三天,断断续续才编译完,有个别算子不知为何编译时间需要两三个小时以上。相比于CPU版本的编译,GPU版本的error多了不少。但是为了速度,当然要编译GPU版本啦。查看报错时,有两点要注意:
1) 如果error信息中出现中文乱码,需要设置cmd的编码;
2) 如果出现(??????),再运行一次编译命令,可能看到(Permisson Denied),此时重启计算机可继续编译。
笔者编译时遇到的第一个error来自azel-tensorflow-1.14.0-rc0externalgrpcsrccoresialtshandshakerhandshaker.pb.c(118):error C2118:负下标不论如何,先打开问题文件看看:
#if !defined(PB_FIELD_16BIT) && !defined(PB_FIELD_32BIT)/*
If you get an error here, it means that you need to define PB_FIELD_16BIT *
compile-time option. You can do that in pb.h or on compiler command line. * *
The reason you need to do this is that some of your messages contain tag *
numbers or field sizes that are larger than what can fit in the default *
8 bit descriptors.*/PB_STATIC_ASSERT((pb_membersize(grpc_gcp_StartClientHandshakeReq,
target_identities) < 256&& pb_membersize(grpc_gcp_StartClientHandshakeReq,
local_identity) < 256&& pb_membersize(grpc_gcp_StartClientHandshakeReq,
local_endpoint) < 256&& pb_membersize(grpc_gcp_StartClientHandshakeReq,
remote_endpoint) < 256&& pb_membersize(grpc_gcp_StartClientHandshakeReq,
rpc_versions) < 256&& pb_membersize(grpc_gcp_ServerHandshakeParameters,
local_identities) < 256&& pb_membersize(grpc_gcp_StartServerHandshakeReq,
handshake_parameters[0]) < 256&& pb_membersize(grpc_gcp_StartServerHandshakeReq,
local_endpoint) < 256&& pb_membersize(grpc_gcp_StartServerHandshakeReq,
remote_endpoint) < 256&& pb_membersize(grpc_gcp_StartServerHandshakeReq,
rpc_versions) < 256&& pb_membersize(grpc_gcp_StartServerHandshakeReq_HandshakeParametersEntry, value)
< 256&& pb_membersize(grpc_gcp_HandshakerReq, client_start) < 256&& pb_membersize(grpc_gcp_HandshakerReq,
server_start) < 256&& pb_membersize(grpc_gcp_HandshakerReq, next) < 256&&
pb_membersize(grpc_gcp_HandshakerResult, peer_identity) < 256&& pb_membersize(grpc_gcp_HandshakerResult,
local_identity) < 256&& pb_membersize(grpc_gcp_HandshakerResult, peer_rpc_versions) < 256&&
pb_membersize(grpc_gcp_HandshakerResp, result) < 256&& pb_membersize(grpc_gcp_HandshakerResp, status) < 256),
YOU_MUST_DEFINE_PB_FIELD_16BIT_FOR_MESSAGES_grpc_gcp_Endpoint_grpc_gcp_Identity_grpc_gcp_
StartClientHandshakeReq_grpc_gcp_ServerHandshakeParameters_grpc_gcp_StartServerHandshakeReq
_grpc_gcp_StartServerHandshakeReq_HandshakeParametersEntry_grpc_gcp_NextHandshakeMessageReq
_grpc_gcp_HandshakerReq_grpc_gcp_HandshakerResult_grpc_gcp_HandshakerStatus_grpc_gcp_HandshakerResp)#endif1.看到这么长一个assert,着实吓了一跳。还好谷歌在注释里说了此处出现error,这需要定义PB_FIELD_16BIT以处理数值超过八位的问题,那么负下标也就可以理解了。那么我们只需按照注释说的,在handshaker.pb.h定义PB_FIELD_16BIT即可:
#define PB_FIELD_16BIT 655361.估苟了一下,发现是缺少c-ares库( https://c-ares.haxx.se ),下载解压,把
ares.h、ares_build.h、are_rules.h、ares_version.h1.添加到MSVC的包含目录里C:ProgramFiles(x86)MicrosoftVisualStudio14.0VCinclude,然后继续编译。
仔细观察所有出链接错误的函数名末尾都有_ares,推测是缺少c-ares的DLL。上一个问题里我们仅仅添加了头文件,因此最后链接时找不到库。我们需要自己安装这个库。根据该库的README.msvc,我们需要打开命令行定位到C:ProgramFiles(x86)MicrosoftVisualStudio14.0VCin利用文件夹中的nmake编译c-ares源码,假设c-ares路径为f:c-ares,执行以下命令:
nmake -f f:c-aresMakefile.msvc1.编译完成的动态链接库及三个例程在f:c-aresmsvc中,我们只需要msvccaresdll-release里的库。在我讲库文件加入到MSVC的目录中后,依然报错。在查看了Bazel文档后发现可以在BUILD中,利用上文第二节提到的cc_import()手动导入库。我们先将c-ares库拷贝到tensorflow-1.14.0-rc0ensorflowpython,接着在tensorflowpythonBUILD的4588行,tf_py_wrap_cc前手动导入cares库:
cc_import( name = "mycares", hdrs = ["myares/ares.h"],
interface_library = "myares/msvc/cares/dll-release/cares.lib",
shared_library = "myares/msvc/cares/dll-release/cares.dll",)1.再次编译不再出现LNK2019,然后迎接新error。
很明显这是cuda库的dll,奇怪的是cudart64_.dll末尾的下划线,一般来说下划线之后都会接上版本号之类的符号。笔者用的是cuda9.0,那么本应该是cudart64_90.dll,故猜测是没有给Bazel指定cuda版本。一番估苟之后,看到一位老哥说给Bazel两个flag指定cuda和cudnn。在3.1节里提到的.tf_configure.bazelrc文件里保存了编译配置,将两个flag加进去:
#tensorflow-1.14.0-rc0/.tf_configure.bazelrc......build --action_env TF_CUDNN_VERSION=7build
--action_env TF_CUDA_VERSION=9.01.继续编译不再找不到,然后迎接新error。
这次同样是找不到库,但是没有说是那个库[汗]。仔细观察Traceback:
发现问题来自Python脚本的import语句,加载_pywrap_tensorflow_internal库失败。一开始笔者以为是相对路径有问题导致脚本找不到库,直接把库拷贝到pywrap_tensorflow_internal.py所在文件夹和WORKSPACE文件夹,但都没有用。又尝试指定绝对路径加载也失败。尝试多次后,猜测不一定是_pywrap_tensorflow_internal库找不到,而是该库的依赖库找不到。因此笔者用DependencyWalker查看其依赖库,发现有不少缺失的库。但是,有一个库比较瞩目,它就是4.1.3里我们自己编译的c-ares库
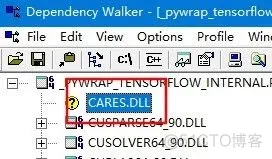
这就可以理解了,之前我们只在BUILD中指定了绝对路径导入了该库,而现在Python脚本从环境变量里的路径是找不到该库的。因此手动将cares.dll拷贝到其中一个环境变量路径里,比如c:Windows,等待了几分钟之后,编译完成。再安装3.3的步骤就就可以安装tensorlfow-python了。
1) Tensorflow源码编译过程其实并不复杂,但是各种工具由于版本众多,相互不兼容导致了许多error。解决这些要求对Bazel这个工具的使用有一定的了解。因此建议读者使用官方测试过的配置进行编译,避免各种诡异的error。
2) 还有多平台支持导致各种库的调用易出现问题。c-ares库在linux平台上的安装只需要一句命令,但在Win10上需要手动编译和安装,第四节中有三个问题都是c-ares库导致的。遇到此类问题时,找找办法让库能被脚本或者编译器找到即可。
3) 如果想用整个Tensorflow库,那么可以用官方编译的c库( https://tensorflow.google.cn/install/lang_c )即插即用。
4) 熟悉了Bazel的使用后,可以用它将一部分函数封装到DLL里,体积更小,还能方便脱离Tensorflow源码池建立工程,并在不同的Win10电脑上运行模型。当然,生产部署一般还是用serving和lite多。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















