















































软件

产品


对于许多开发者来说,TensorFlow是他们接触的第一个机器学习框架。TensorFlow框架尽管意义非凡,引起极大关注和神经网络学习风潮,但对一般开发者用户太不友好。

软件开发者毕竟不是科学家,很多时候简单易学易用是程序员选择的第一要素。目前,两个主要的深度学习库Keras和Pytorch获得了大量关注,主要是因为它们的使用比较简单。
keras出身就像是一个天生丽质的姑娘,是多个计算后台框架的”前端”,轻量且容易入门。

keras是神经网络的一个模型计算框架,严格来说不是神经网络框架。本身没有重量级计算,它使用其他AI框架作为计算后台,傻瓜式的使用。它的计算后台还支持 Theano、CNTK(微软的一个AI计算后台)等,也就是说keras是多个计算后台的门面。官方设计哲学为Simple. Flexible. Powerful,是深度学习入门的绝佳技术路线

举个tensorflow1.0的例子(伪代码)
定义Variable、constant、placeholder等。初始化global_variables_initializersession回话状态。再关闭session。
其中神经网络的各个层需要单独定义,还有一些激活函数、损失函数等概念。看到这些对于一个AI刚入门的开发者确实有些茫然。
keras是google的一个大佬开发的一个高度封装的模型框架,已开源到github上。起初的计算后台为Theano(和tensorflow差不多的一个框架),后来经过一系列的剧情,现在默认的计算后台就为tensorflow了。另外由于tensorflow1.0的细节过于繁琐混乱,升级版的tensorflow2.0基本抛弃了上述编写语法。其自家小弟tensorflow.keras 已经和keras版本同步了。
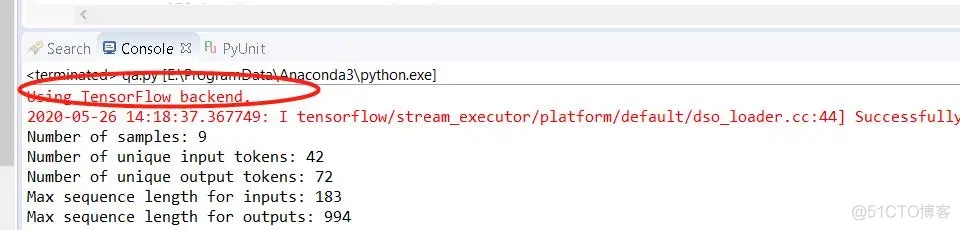
backend为Tensorflow的keras
Pytorch是一个机器学习框架(类似于Theano、tensorflow等)。与Keras一样,它也抽象出了深层网络编程的许多混乱部分(大神踩过的坑,我们就没有必要踩了)。就学习难易和语言高级程度而言,Pytorch介于Keras和TensorFlow之间。但比起Keras具有更大的灵活性和控制能力,但又不必进行任何复杂的声明式编程,如果想深入了解机器学习pytorch库就是不错的选择。
keras比较适合入门级学习,如程序员、系统开发者等非专业开发者,结合其后端(tensorflow等)部署,在工业领域在目前应用范围广。
目前,在学术界Pytorch已经超越其他框架,应为它轻部署,重验证。而keras相当于一个大前端,直接使用keras对于专业人员(科学家、学者、工程师)来说,屏蔽了许多细节,不利于研究,一般不是很合适。
为了定义深度学习模型,Keras提供了函数式API。使用函数式API,神经网络被定义为一系列顺序化的函数,一个接一个地被应用。定义神经网络是非常直观的,因为使用API可以将层定义为函数。如下图示例(伪代码)
#定义modelmodel = keras.Sequential([ keras.layers.Flatten(input_shape=(28, 28)), keras
.layers.Dense(128, activation='relu'), keras.layers.Dense(10)])#编译compilemodel.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])#拟合fitmodel.fit(train_images, train_labels, epochs=10)#评估evaluatetest_loss,
test_acc = model.evaluate(test_images, test_labels, verbose=2)print('Test accuracy:', test_acc)
#预测predictpredictions = model.predict(test_images)
在Pytorch中,你将网络设置为一个继承来自Torch库的torch.nn.Module的类。与Keras类似,Pytorch提供给你将层作为构建块的能力,但是由于它们在Python类中,示例如下(伪代码)。
class Net(nn.Module): def __init__(self): super(Net, self).__init__()pass
def forward(self, x): return xmodel = Net()
Keras API向开发者隐藏了许多琐碎的细节(免得踩坑)。这使得定义网络层是简单,默认的设置通常足以让你入门,对应开发者来说就学习是1+1=2,而产量是>2的。

Pytorch在这些方面更宽容一些。你需要知道每个层的输入和输出大小,但是这是一个比较容易的方面,你可以很快掌握它。你不需要构建一个抽象的计算图,避免了在实际调试时无法看到该抽象的计算图的细节。另外,你可以在Torch张量和Numpy数组之间来回切换,它们是内存共享的。如果你需要实现一些自定义的东西,那么在TF张量和Numpy数组之间来回切换可能会很麻烦,这要求开发人员对TensorFlow会话有一个深入的理解。
如果你没有更加奇特的需求,只想简单了解尝试一下,强烈推荐keras,它的一个.fit(),简直让你爱不释手。
Pytorch在每次训练开始就有前向传播、反向传播、计算损失并更新权重等等,不熟悉框架时就要踩坑。

keras的tensorflow版本,cpu和gpu是自动过渡的,不需要手工调整。
Pytorch必须显式地为每个torch张量和numpy变量启用GPU,一般使用“.to()”方法。但这种方式容易使代码变得混乱,如果不同的操作在CPU和GPU之间来回移动,那么很容易踩坑。
Keras是最容易使用和快速入门的前端框架。你甚至可以在不接触后端(tensorflow等)的任何一行代码的情况下实现神经网络的分类、聚类、自然语言处理等问题。
如果想深入了解神经网络的各个细节及执行历史,那么Pytorch可能是你首选。
一般建议keras入门,pytorch进阶。

免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















