















































软件

产品


首先是检查是否 数据
import pandas as pdreviews = pd.read_csv("winemag-data-130k-v2.csv", index_col=0)reviews.head()
| country | description | designation | points | price | province | region_1 | region_2 | taster_name | taster_twitter_handle | title | variety | winery | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Italy | Aromas include tropical fruit, broom, brimston... | Vulkà Bianco | 87 | NaN | Sicily & Sardinia | Etna | NaN | Kerin O’Keefe | @kerinokeefe | Nicosia 2013 Vulkà Bianco (Etna) | White Blend | Nicosia |
| 1 | Portugal | This is ripe and fruity, a wine that is smooth... | Avidagos | 87 | 15.0 | Douro | NaN | NaN | Roger Voss | @vossroger | Quinta dos Avidagos 2011 Avidagos Red (Douro) | Portuguese Red | Quinta dos Avidagos |
| 2 | US | Tart and snappy, the flavors of lime flesh and... | NaN | 87 | 14.0 | Oregon | Willamette Valley | Willamette Valley | Paul Gregutt | @paulgwine | Rainstorm 2013 Pinot Gris (Willamette Valley) | Pinot Gris | Rainstorm |
| 3 | US | Pineapple rind, lemon pith and orange blossom ... | Reserve Late Harvest | 87 | 13.0 | Michigan | Lake Michigan Shore | NaN | Alexander Peartree | NaN | St. Julian 2013 Reserve Late Harvest Riesling ... | Riesling | St. Julian |
| 4 | US | Much like the regular bottling from 2012, this... | Vintner's Reserve Wild Child Block | 87 | 65.0 | Oregon | Willamette Valley | Willamette Valley | Paul Gregutt | @paulgwine | Sweet Cheeks 2012 Vintner's Reserve Wild Child... | Pinot Noir | Sweet Cheeks |
1、 从结果中选择某一列 进行 赋值
desc = reviews.description# ordesc = reviews["description"] # 这两个都可以desc.head()"""0 Aromas include tropical fruit, broom, brimston...1 This is ripe and fruity, a wine that is smooth...2 Tart and snappy, the flavors of lime flesh and...3 Pineapple rind, lemon pith and orange blossom ...4 Much like the regular bottling from 2012, this...Name: description, dtype: object"""2、从reviws的description列取第一个值
first_description = reviews.description.iloc[0]first_description'''"Aromas include tropical fruit, broom, brimstone and dried herb. The palate isn't overly expressive, offering unripened apple, citrus and dried sage alongside brisk acidity."'''3、取第一行的值,即第一行记录
first_row = reviews.iloc[0]first_row'''country Italydescription Aromas include tropical fruit, broom, brimston...designation Vulkà Biancopoints 87price NaNprovince Sicily & Sardiniaregion_1 Etnaregion_2 NaNtaster_name Kerin O’Keefetaster_twitter_handle @kerinokeefetitle Nicosia 2013 Vulkà Bianco (Etna)variety White Blendwinery NicosiaName: 0, dtype: object'''4、选取reviews中description列的前10行值。
first_description = reviews.description.iloc[:10]first_description'''0 Aromas include tropical fruit, broom, brimston...1 This is ripe and fruity, a wine that is smooth...2 Tart and snappy, the flavors of lime flesh and...3 Pineapple rind, lemon pith and orange blossom ...4 Much like the regular bottling from 2012, this...5 Blackberry and raspberry aromas show a typical...6 Here's a bright, informal red that opens with ...7 This dry and restrained wine offers spice in p...8 Savory dried thyme notes accent sunnier flavor...9 This has great depth of flavor with its fresh ...Name: description, dtype: object'''5、选取索引1,2,3,5,8的记录行
index = [1,2,3,5,8]sample_reviews = reviews.iloc[index]# sample_reviews = reviews.loc[index]'''这里loc 和 iloc的区别是:iloc: 是你选择的是第1,2,3,5,8行而loc: 则是根据你的索引 比如你的索引是从1500开始往后递增的 那么用上面的1,2,3,5,8就会报错 应该用[1501,1502,1503,1505,1508]'''# result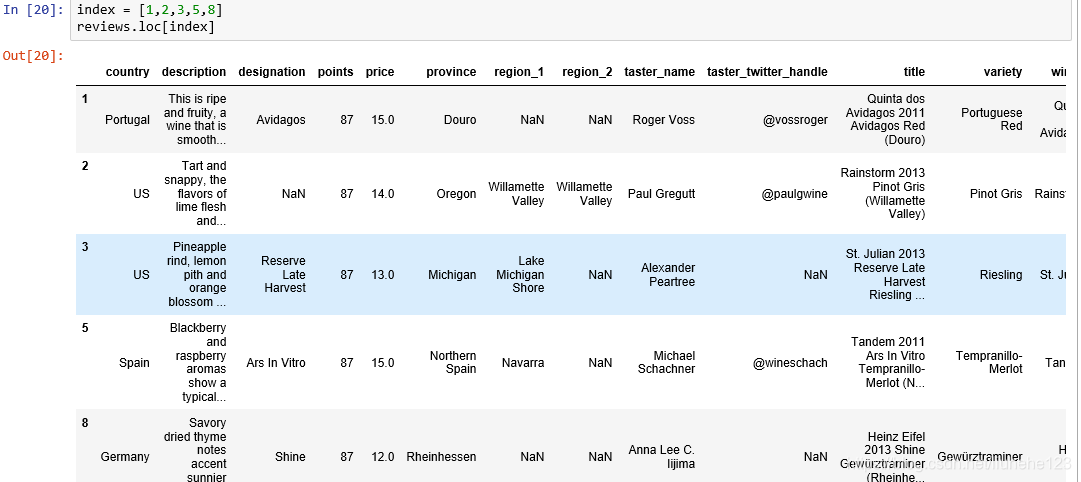
6、创建一个变量df,df包含reviews的 `country`, ` province `, `region_1`, and `region_2`列,并保留索引 0 1 10 100的记录,换言之产生一个如下的DataFrame:

cols = ['country', 'province', 'region_1', 'region_2']indices = [0, 1, 10, 100]reviews.loc[indices, cols]# 运行结果如下:
| country | province | region_1 | region_2 | |
|---|---|---|---|---|
| 0 | Italy | Sicily & Sardinia | Etna | NaN |
| 1 | Portugal | Douro | NaN | NaN |
| 10 | US | California | Napa Valley | Napa |
| 100 | US | New York | Finger Lakes | Finger Lakes |
7、 创建包含country、variety列且保留前100行数据的变量df:
cols = ['country', 'variety']df = reviews.loc[:99, cols]# or cols_idx = [0, 11]df = reviews.iloc[:100, cols_idx]
| country | variety | |
|---|---|---|
| 0 | Italy | White Blend |
| 1 | Portugal | Portuguese Red |
| 2 | US | Pinot Gris |
| 3 | US | Riesling |
| 4 | US | Pinot Noir |
| 5 | Spain | Tempranillo-Merlot |
.........................................................................
8、创建一个DataFrame 名字叫做italian_wines,包含 ‘Italy’列 即 酒的产地。提示: `reviews.country`
italian_wines = reviews[reviews.country == 'Italy']italian_wines.head()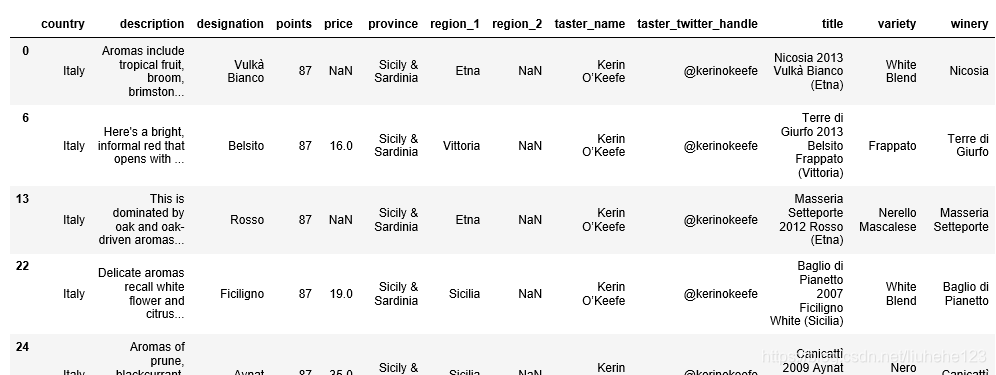
9、创建一个DataFrame名字叫做top_oceania_wines,包含至少95行以上产地来自Australia或new zealand的 信息 。
top_oc = reviews[ (reviews.country.isin(['Australia','new zealand'])&(reviews.points >= 95))]
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















