















































软件

产品


| 运算符 | 描述 |
|---|---|
| + | 加法 |
| − | 减法 |
| * | 乘法 |
| / | 除法 |
| ^或** | 求幂 |
| %% | 求余 |
| %/% | 整数除法 |
| 函数 | 描述 |
|---|---|
| length(x) | 求 x 中元素的个数 |
| mean(x) | 求 x 的算术平均值 |
| median(x) | 求 x 的中位数 |
| var(x) | 求 x 的样本方差 |
| sd(x) | 求 x 的样本标准差 |
| range(x) | 求 x 的全距 |
| min(x) | 求 x 的最小值 |
| max(x) | 求 x 的最大值 |
| quantile(x) | 求 x 的分位数 |
| sum(x) | 求 x 中所有元素的和 |
| scale(x) | 将 x 标准化 |
工作空间(workspace)就是 R 的工作环境,所有创建的对象都被临时保存在工作空间(也可称为全局环境,.GlobalEnv)中。
ls( ) :列出当前工作空间中的所有对象getwd( ) :查看当前的工作目录setwd( ) :设定当前的工作目录向量Vector:存储数值型、字符型、逻辑型数据的一维 数组 。标量可以看作是只含有一个元素的向量。函数 c( ) 可用来创建向量,每一个向量中的数据类型必须一致
因子factor:即分类变量,名义型变量是没有顺序关系的分类变量,有序型变量是有层级和顺序关系的分类变量
矩阵Matrix、多维数组 和 列表(允许不同类型数据混合), 数据框(dataframe)
'''向量赋值'''x1 <- c(2, 4, 1, -2, 5)x2 <- c("one", "two", "three")x3 <- c(TRUE, FALSE, TRUE, FALSE)x4 <- 1:5 # 等价于x4 <- c(1, 2, 3, 4, 5)x5 <- seq(from = 2, to = 10, by = 2) # 等价于x5 <- c(2, 4, 6, 8, 10)x6 <- rep("a", times = 4) # 等价于x6 <- c("a", "a", "a", "a") #下标取值x[5] #从1开始计数x[c(4, 6, 7)] #取第4,6,7x[-(1:4)] #去掉前四个元素 '''因子赋值'''sex <- c(1, 2, 1, 1, 2, 1, 2)sex.f <- factor(sex, levels = c(1, 2), #levels 表示原变量的分类标签值 labels = c("Male", "Female")) #labels 表示因子取值的标签 levels(sex.f) #查看因子的属性sex.f1 <- relevel(sex.f, ref = "Female") #改变因子水平的排序:改变参考组status.f <- factor(status,levels = c(1, 2, 3),labels = c("Poor", "Improved", "Excellent"),ordered = TRUE) #有序因子 ordered=True '''矩阵'''M <- matrix(1:6, nrow = 2, byrow=FALSE) #byrow默认按列将数值进行排列dim(M) #查看维度mat1 %*% mat2 #矩阵乘法t(mat1) #转置det( )、solve( ) #行列式和逆矩阵rowSums、colSums、rowMeans、ColMeans #按行、列求和或者求平均 '''数组:带标签的矩阵'''dim1 <- c("A1", "A2", "A3")dim2 <- c("B1", "B2", "B3", "B4")dim3 <- c("C1", "C2")print(array(1:24, dim = c(3, 4, 2), dimnames = list(dim1, dim2, dim3)))# --> , , C1 B1 B2 B3 B4A1 1 4 7 10A2 2 5 8 11A3 3 6 9 12 , , C2 B1 B2 B3 B4A1 13 16 19 22A2 14 17 20 23A3 15 18 21 24 '''列表: 很多函数返回值是列表'''list1 <- list(a = 1, b = 1:5, c = c("red", "blue", "green")) '''数据框'''ID <- 1:5sex <- c("male", "female", "male", "female", "male")age <- c(25, 34, 38, 28, 52)pain <- c(1, 3, 2, 2, 3) pain.f <- factor(pain, levels = 1:3, labels = c("mild", "medium", "severe")) patients <- data.frame(ID, sex, age, pain.f) #引用某一个列:$patients$age 数据类型的判断与 转换 函数
| 判断 | 转换 |
|---|---|
| is.numeric( ) | as.numeric( ) |
| is.character( ) | as.character( ) |
| is.logical( ) | as.logical( ) |
| is.factor( ) | as.factor( ) |
| is.vector( ) | as.vector( ) |
| is.matrix( ) | as.matrix( ) |
| is.array( ) | as.array( ) |
| is.data.frame( ) | as.data.frame( ) |
| is.list( ) | as.list( ) |
| is.table( ) | as.table( ) |
#查看内置数据集data(package = "datasets")#调用iris数据data(iris)各种分布的数据:rnorm( )、runif( )、rbinom( )、 rpois( )
r1 <- rnorm(n = 100, mean = 0, sd = 1)r2 <- runif(n = 10000, min = 0, max = 100)r3 <- rbinom(n = 80, size = 100, prob = 0.1)r4 <- rpois(n = 50, lambda = 1) #查看hist(r1)head(r1)txt或csv文件:write.table( ) 和 write.csv( )
R 数据文件:save()
save(patients, file = "patients.rdata")rio 包以提供一个类似万能工具的包为目标,用统一的 import( ) 函数和 export( ) 函数简化了用户导入和导出数据的工作。此外,该包里的 convert( ) 函数可以实现不同 文件格式 之间的转换。rio 包支持多种文件格式,包括 SAS、SPSS、Stata、Excel、MATLAB、Minitab 等其他软件中使用的数据文件格式
library(rio) #install_formats( )可以安装data("infert")str(infert) #str常用于查看数据集的大小以及各个变量的类型 #导出export(infert, "infert.csv")#转换convert("infert.csv", "infert.sav")#导入infert.data <- import("infert.sav")View(iris) #查看nrow(iris)ncol(iris)dim(iris)names(iris) #列名str(iris) #结构attributes(iris) #数据属性summary(iris)head(iris)tail(iris) colnames() #重命名列install.packages("Hmisc") library(Hmisc)describe(iris) #需要Hmisc包 mean(iris$Sepal.Length)median(iris$Sepal.Length)range(iris$Sepal.Length) #数据范围区间quantile(iris$Sepal.Length, c(0.1,0.3,0.6))var(iris$Sepal.Length)cov(iris$Sepal.Length, iris$Petal.Length) #covariancecor(iris$Sepal.Length, iris$Petal.Length) #correlation table(iris, useNA='ifany') #计数统计 colSums() #按列求和rowSums() #按行求和aggregate(iris$Sepal.Length ~ iris$Species, summary,data=iris) #向量化操作apply(x, MARGIN, FUN, ...) #MARGIN是维度的下标,1表示行, 2表示列apply(mydata,1,mean) #求矩阵行均值apply(mydata,2,mean) #求矩阵列均值 lapply(X, FUN, ...) #用于对列表对象执行操作#密度图plot(density(iris$Sepal.Length),main='Density of Sepal Length') #盒图boxplot(Sepal.Length ~ Species, data = iris)boxplot(Sepal.Length ~ Species, data = iris)$out #查看异常值 #散点图 (x,y,color,marker)plot(iris$Sepal.Length, iris$Sepal.Width, col = iris$Species, pch = as.numeric(iris$Species)) #散点图矩阵(两两每列)pairs(iris) #柱状图barplot(iris$Sepal.Length, horiz=FALSE, las=2)ggplot2的作图一般步骤为:
ggplot()函数中, 并指定参与作图的每个变量分别映射到哪些图形特性, 比如映射为x坐标、y坐标、颜色、形状等。 这些映射称为aesthetic mappings或aesthetics。geom_开头, 如geom_point()表示散点图。 图形类型简称为geom。 将ggplot()部分与geom_xxx()部分用加号连接。 到此已经可以作图,下面的步骤是进一步的细化设定。coord_cartesian(), scale_x_log10()等。 仍用加号连接。labs()。 仍用加号连接。#分割字符串strsplit(x,'[$]')#查看缺失值NAis.na(iris)which(is.na(iris)) #返回缺失值位置 #填充缺失值NAx[is.na(x)] <- mean(x, na.rm=TRUE) #筛除缺失值NAcomplete.cases(df) #返回各行布尔值, df[complete.cases(), ]na.omit(df) #返回不含缺失值的各行 #查看空值(没有赋值), 空格字符串不是空值!is.null() #除去字符型数据前后的空格library(raster)trim(iris)Methods:
# IQRboxplot(iris$Sepal.Width)$out #输出异常值boxplot(iris$Sepal.Width, outline=False) #忽略异常 # z-scorescale(iris$Sepal.Width) #(样本-样本均值)/样本标准差#查看是否重复值duplicated(df,by=c("id","value")) #重复值索引which(duplicated(df)) #除去重复值, 两种方法df[!duplicated(df,by=c("id","value")),]unique(df)#极大极小缩放min_max_norm <- function(x){ (x-min(x))/(max(x)-min(x))}lapply(iris,min_max_norm) #标准化scale()#Ordinal Encoding factor_Breakfast <- factor(Breakfast,order = TRUE,levels=c('Never','Rarely','Most days','Every day'))encode_Breakfast <- as.numeric(factor_Breakfast)encode_Breakfast #One-Hot Encoding 法1model.matrix(~iris$Species-1,iris)) #返回独热编码#法2library(mltools)library(data.table)one_hot(as.data.table(as.factor(iris$Species))) #返回独热编码 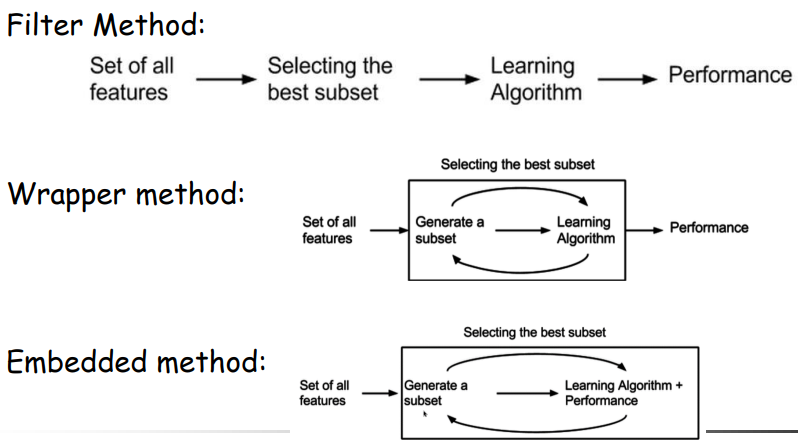
set.seed(1234) idx <- sample(c(TRUE, FALSE), nrow(iris), replace=TRUE, prob=c(0.7,0.3))train <- iris[idx, ]test <- iris[!idx, ]#KNNlibrary(class)knn_output <- knn(train[,1:4],test[,1:4],train[,5],k=3) #决策树library(rpart)model1 <- rpart(Species~., data = train, method = 'class')dt_output <- predict(model1, test[,1:4],type = 'class') #随机森林library(randomForest)model2 <- randomForest(Species ~ ., data = train, ntree=200, importance = TRUE)rf_output <- predict(model2, test[,1:4]) #线性回归model1 <- lm(Balance~.,data=train)lm_output <- predict(model1,test) #混淆矩阵table(knn_output,test$Species) #具体统计分析和混淆矩阵library(caret)confusionMatrix(knn_output, test$Species, mode='everything')
 confusionMatrix
confusionMatrix
#线性回归library(performance)check_model(fit) library(caret)RMSE()MAE()统计回归分析:
#遍历赋值x <- c(1,2,3,4,5)y <- c(6,7,8,9,10) #一元回归模型fit = lm(y~x) #置信区间confint(fit)#统计总结summary(fit) #逻辑回归模型model = glm(cbind(y,1-y) ~x1+x2, family=binomial, data=df )R语言数据挖掘分析常用函数和包有哪些? - 知乎
https://zhuanlan.zhihu.com/p/40522720
R 语言必学的 10 大包是什么? - 知乎
https://www.zhihu.com/question/24136262
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















