















































软件

产品


当今的GPU已经针对单址或连续地址的大量内存处理(亦称为流式操作,streaming operation)进行了优化,这与CPU面向内存随机访问的设计理念刚刚好背道而驰。再者,考虑到要对顶点与 像素 分别进行单独的处理,因此GPU现已经采用了大规模并行处理架构。例如,NVIDIA公司开发的"Fermi"架构最多可支持16个流式多处理器(streaming multiprocessor, SM),而每个流式处理器又均含有32个 CUDA 核心,也就是共512个CUDA核心[NVIDIA09]。
显然,图形的绘制优势完全得益于GPU架构,因为这架构就是专为绘图而精心设计的。但是,一些非图形应用程序同样可以从GPU并行架构所提供的强大计算能力中收益。我们将GPU用于非图形应用程序的情况称为通用GPU程序设计(通用GPU编程,General Purpose GPU programming, GPGPU programming)。当然,并不是所有算法都适合由GPU来执行,只有数据并行算法(data-parallel algorithm)才能发挥出GPU并行架构的优势。也就是说,当拥有大量待执行相同操作的数据时,才最适宜采用并行处理。示例:①像素着色:因为每个被绘制的像素都要经过像素着色器的统一处理;②模拟波浪:之前我们模拟波浪时,对每一个栅格元素进行一遍相同的运算,让GPU来执行这个计算过程是不错的选择;③粒子系统:我们可以简化粒子之间的关系模型,使它们彼此毫无关联,以此使每个例子的物理特征都可以分别独立地计算出来。
对于GPGPU编程而言,用户通常需要将计算结果返回CPU供其访问。这就需要将数据从显存复制到系统内存,虽说这个过程(GPU->CPU,参考👇图)的速度较慢,但是与GPU运算时所节省的时间来讲是微不足道的。
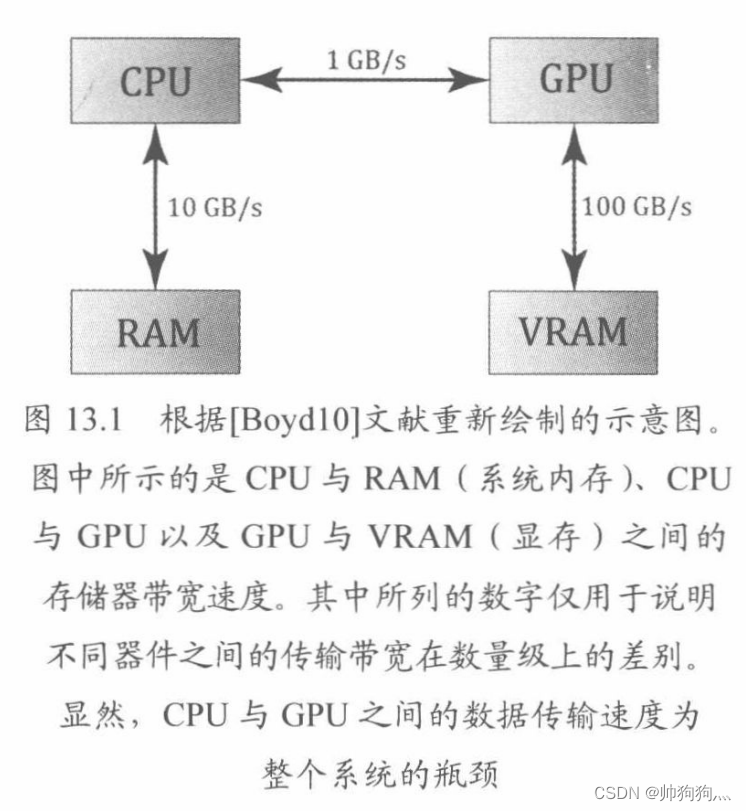
针对图形处理任务来说,我们一般将运算结果作为渲染流水线的输入,所以无须再由GPU向CPU传输数据。例如,我们可以用计算着色器(compute shader)对纹理进行模糊处理(blur),再将着色器资源视图(SRV)与模糊处理后的纹理相绑定,以作为着色器的输入。
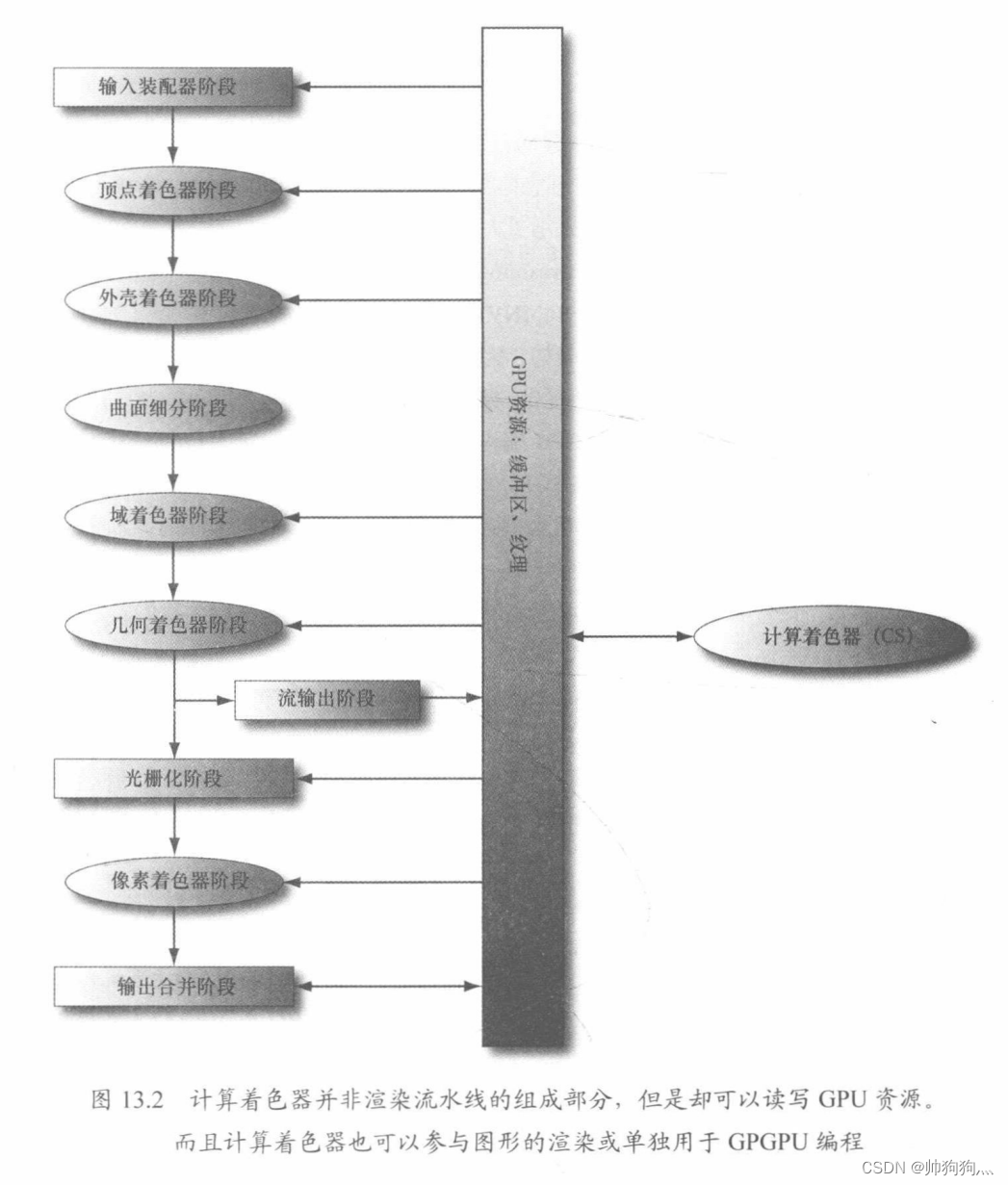
计算着色器虽然是一种可编程的着色器,但是Direct3D并没有将它直接归为渲染流水线中的一部分。虽然如此,位于流水线之外的计算着色器却可以读写GPU资源,而且,由于计算着色器是D3D的组成部分,所以它也可以读写Direct3D资源,由此,我们可以将其输出的数据直接绑定到渲染流水线上。
在GPU编程的过程中,根据程序具体的执行需求,可将线程划分为线程组(thread group)构成的网格。一个线程组运行于一个多处理器之上。因此,对于拥有16个多处理器的GPU来说,我们至少应将任务分解为16个线程组,以此令每个多处理器都充分地运转起来。但是,要获得更佳的性能,我们还应当令每个多处理器至少拥有两个线程组,使它能够切换到不同的线程组进行处理,以连续不停地工作[Fung10](线程组可能在运行时发生停顿,例如,着色器在执行下一条指令之前会等待纹理处理的结果,这时可以切换到另一个线程组)。
每个线程组中都有一块共享内存,供组内的线程访问。但是,线程不能访问其他组的共享内存。同组内的线程间能够进行同步操作,不同组的线程间却不能实现这一点。事实上,我们也无法控制不同线程组间的处理顺序,因为这些线程组可能正运行在不同的多处理器上。
一个线程组中含有n个线程。硬件实际上会将这些线程分为多个warp(每个warp中有32个线程),而且多处理器会以SIMD32的方式(即32个线程同时执行相同的指令序列)来处理warp。每个CUDA(Compute Unified Device Architecture, 显卡厂商NVIDIA推出的运算平台)核心都可处理一个线程,前面也提到了,“Fermi”架构中的每个多处理器都具有32个CUDA核心(因此,CUDA核心就像一条专设的SIMD"计算通道")。在Direct3D中,我们能够以非32的倍数值来指定线程组的大小。但是处于性能的原因,我们应当总是将线程组的大小设置为warp尺寸的整数倍[Fung10]。
对于各种型号的图形硬件来说,线程数为256的线程组是一种普遍适于工作的初始状态。我们可以以此值为基础,再根据具体需求尝试将其调整为其他大小。值得注意的是,修改每个线程组中的线程数量也会对线程组的分派(dispatch,调度)次数产生影响[组线程数量于分派函数参数的设置配合很有讲究],这直接关乎计算着色器的工作效率。

在Direct3D中可通过调用下列方法来启动线程组:
- void ID3D12GraphicsCommandList::Dispatch(
- UINT ThreadGroupCountX,
- UINT ThreadGroupCountY,
- UINT ThreadGroupCountZ,
- );
👆此方法开启一个由线程组构成的3D网格,但是我们在本书中仅关注线程组2D网格。
使用示例:下面调用会分配一个在x方向上为3,y方向上为2,即总数为3×2=6个线程组的网格:
cmdList->Dispatch(3, 2, 1);cpp运行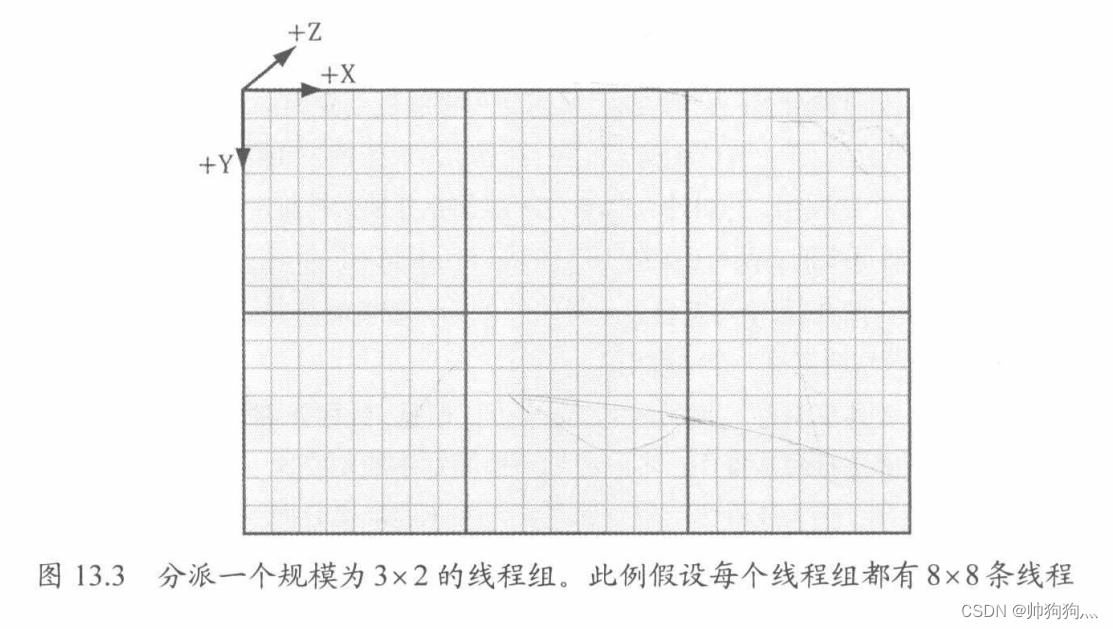
示例:将两个纹理进行简单累加计算,假设纹理具有相同的大小
- cbuffer cbSettings
- {
- // 计算着色器能访问的常量缓冲区数据
- };
-
- // 数据源及着色器的输出
- Texture2D gInputA;
- Texture2D gInputB;
- RWTexture2D<float4> gOutput;
-
- // 线程组中的线程数。组中的线程可以被设置为1D、2D或3D的网格布局
- [numthreads(16, 16, 1)]
- void CS(int3 dispatchThreadID : SV_DispatchThreadID) // 线程ID
- {
- // 对两种源像素中横纵坐标分别为x、y处的纹素进行求和,并将结果保存到相应的gOutput纹素中
- gOutput[dispatchThreadID.xy] =
- gInputA[dispatchThreadID.xy] +
- gInputB[dispatchThreadID.xy];
- }
可见,一个计算着色器由下列要素构成:
我们可以根据需求定义出不同的线程组布局,比如单行(Y,Z=1)、单列(X,Z=1)或者2D线程组(Z=1)等等。因为前面讨论的两种显卡对线程组中总线程数的要求,所以把64当作线程组内线程数(wavefront大小,2倍warp大小),进行设置对两种显卡都适用。
注意:[numthreads(16, 16, 1)]与cmdList->Dispatch(16,16,1)是不同的!
numthreads是一个线程组中的线程分布,也就是说,一个线程组被分为16×16×1的结构
而Dispatch是指在线程组网格中,线程组的分布情况,也就是一共有16×16×1个线程组
反正一般我们处理比如4x4的纹理,我们就设置[numthreads(4,4,1)],使索引一一对应
计算流水线状态对象:
为了开启计算着色器,我们还需要使用特定的“计算流水线状态描述”。此描述中的字段远少于D3D12_GRAPHICS_PIPELINE_STATE_DESC 结构体 。这是因为计算着色器位于图形流水线之外,因此所有的图形流水线状态都不适用于计算着色器,也就无须以此对它进行设置。
注意区分D3D12_GRAPHICS_PIPELINE_STATE_DESC与D3D12_COMPUTE_PIPELINE_STATE_DESC
将渲染(图形)流水线与计算流水线视作两种不同的流水线。另外,D3D12_COMPUTE_PIPELINE_STATE_DESC共有5个字段
示例:创建计算流水线状态对象
- D3D12_COMPUTE_PIPELINE_STATE_DESC wavesUpdatePSO = {};
- wavesUpdatePSO.pRootSignature = mWavesRootSignature.Get();
- wavesUpdatePSO.CS =
- {
- reinterpret_cast<BYTE*>(mShaders["wavesUpdateCS"]->GetBufferPointer()),
- mShaders["wavesUpdateCS"]->GetBufferSize()
- };
- wavesUpdatePSO.Flags = D3D12_PIPELINE_STATE_FLAG_NONE;
- ThrowIfFailed(md3dDevice->CreateComputePipelineState(
- &wavesUpdatePSO, IID_PPV_ARGS(&mPSOs["wavesUpdate"])
- ));
根签名定义了什么参数才是着色器所期望的输入(CBV/SRV等)。而CS字段就是所指定的计算着色器。下列代码展示了一个将着色器编译为字节码的示例:
- mShaders["wavesUpdateCS"] = d3dUtil::CompileShader(
- L"Shaders\\WaveSim.hlsl", nullptr, "UpdateWaveCS", "cs_5_0"
- );
能与CS绑定的资源类型有缓冲区与纹理两种。我们已经用过诸如顶点、索引与常量这几 类 缓冲区,在第9章中也尝试过纹理资源。
①纹理输入:
上一节示例中,我们定义了两个输入纹理资源:
我们通过给输入纹理gInputA与gInputB分别创建SRV,并将它们作为参数传入根参数,我们就能将两个纹理绑定为着色器的输入资源。如下,注意,我们绑定到计算流水线而不是渲染流水线上,所以函数略有不同:
- cmdList->SetComputeRootDescriptorTable(1, mSrcA);
- cmdList->SetComputeRootDescriptorTable(2, mSrcB);
注意:SRV都是只读资源!-- 设计者就这么定义的
着色器资源视图 (SRV) 和无序的访问视图 (UAV) - UWP applications | Microsoft Docs
②纹理输出与无序访问视图:
上一节示例中,我们定义了一个输出资源:
RWTexture2D<float4> gOutput;cpp运行
计算着色器处理输出资源的方式比较特殊,它们的类型还有一个特别的前缀"RW",意为读与写。顾名思义,我们可以对计算着色器中的这类资源元素进行读写操作。相比之下,gInputA/B仅为只读属性。当然,别忘记用尖括号模板语法,如<float4>来指定输出资源的类型与维数。如果输出的是DXGI_FORMAT_R8G8_SINT类型的2D整形资源,则在HLSL文件中这样写:
RWTexture2D<int2> gOutput;cpp运行
输出资源与输入资源的绑定方法是全然不同的。为了绑定在计算着色器中要执行写操作的资源,我们需要将其与称为无序访问视图(Unordered Access View, UAV)的新型视图关联在一起。在代码中,我们用描述符句柄来表示无序访问视图,且通过结构体D3D12_UNORDERED_ACCESS_VIEW_DESC来对它进行描述。创建UAV与创建SRV很相似。
示例:为纹理创建UAV
- // 首先:纹理是一种D3D资源
- D3D12_RESOURCE_DESC texDesc;
- ZeroMemory(&texDesc, sizeof(D3D12_RESOURCE_DSEC));
- texDesc.Dimension = D3D12_RESOURE_DIMENSION_TEXTURE2D;
- texDesc.Alignment = 0;
- texDesc.Width = mWidth;
- texDesc.Height = mHeight;
- texDesc.DepthOrArraySize = 1;
- texDesc.MipLevels = 1;
- texDesc.Format = DXGI_FORMAT_R8G8B8A8_UNORM;
- texDesc.SampleDesc.Count = 1;
- texDesc.SampleDesc.Quality = 0;
- texDesc.Layout = D3D12_TEXTURE_LAYOUT_UNKNOWN;
- texDesc.Flags = D3D12_RESOURCE_FLAG_ALLOW_UNORDERED_ACCESS;
-
- ThrowIfFailed(md3dDevice->CreateCommittedResource(
- &CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT),
- D3D12_HEAP_FLAG_NONE,
- &texDesc,
- D3D12_RESOURCE_STATE_COMMON,
- nullptr,
- IID_PPV_ARGS(&mBlurMap0)
- ));
-
- // SRV
- D3D12_SHADER_RESOURCE_VIEW_DESC srvDesc = {};
- srvDesc.Shader4ComponentMapping = D3D12_DEFAULT_SHADER_4_COMPONENT_MAPPING;
- srvDesc.Format = mFormat;
- srvDesc.ViewDimension = D3D12_SRV_DIMENSION_TEXTURE2D;
- srvDesc.Texture2D.MostDetailedMip = 0;
- srvDesc.Texture2D.MipLevels = 1;
-
- // UAV
- D3D12_UNORDERED_ACCESS_VIEW_DESC uavDesc = {};
- uavDesc.Format = mFormat;
- uavDesc.ViewDimension = D3D12_UAV_DIMENSION_TEXTURE2D;
- uavDesc.Texture2D.MipSlice = 0;
-
- md3dDevice->CreateShaderResourceVIEW(mBlurMap0.Get(), &srvDesc, mBlur0CpuSrv);
- md3dDevice->CreateUnorderedAccessView(mBlurMap0.Get(), nullptr, &uavDesc, mBlur0CpuUav);
从代码👆可以看出,如果一个纹理需要与UAV相绑定,则此纹理必须用标志D3D12_RESOURCE_FLAG_ALLOW_UNORDERED_ACCESS来创建。在👆的示例中,我们将纹理分别绑定为一个UAV与一个SRV(但是两者却不能同时生效)。这是一种很常见的手段,因为我们通常会在计算着色器中对纹理执行某些操作(UAV绑定到CS),而后还可能用此纹理对几何体进行贴图,因此需要再将它以SRV绑定到VS或PS。
回顾一下,类型为D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV的描述符堆可以混合存放三种视图,因此我们能将UAV描述符置于这种堆中。置于堆后,我们就能方便地将描述符句柄作为参数传至根参数,使资源绑定到流水线上,以供分派调用(dispatch call)使用。
渲染流水线与计算流水线的区别,其中对应的绘制请求与线程组分派也分别被称为绘制调用draw call与分派调用 dispatch call。
示例:用于CS的根签名
- void BlurApp::BuildPostProcessRootSignature()
- {
- CD3DX12_DESCRIPTOR_RANGE srvTable;
- srvTable.Init(D3D12_DESCRIPTOR_RANGE_TYPE_SRV, 1, 0);
-
- CD3DX12_DESCRIPTOR_RANGE uavTable;
- uavTable.Init(D3D12_DESCRIPTOR_RANGE_TYPE_UAV, 1, 0);
- CD3DX12_ROOT_PARAMETER slotRootParameter[3];
-
- slotRootParameter[0].InitAsConstants(12, 0);
- slotRootParameter[1].InitAsDescriptorTable(1, &srvTable);
- slotRootParameter[2].InitAsDescriptorTable(1, &uavTable);
-
- CD3DX12_ROOT_SIGNATURE_DESC rootSigDesc(3, slotRootParameter,
- 0, nullptr,
- D3D12_ROOT_SIGNATURE_FLAG_ALLOW_INPUT_ASSEMBLER_INPUT_LAYOUT);
-
- ComPtr<ID3DBlob> serializedRootSig = nullptr;
- ComPtr<ID3DBlob> errorBlob = nullptr;
- HRESULT hr = D3D12SerializeRootSignature(&rootSigDesc, D3D_ROOT_SIGNATURE_VERSION_1,
- serializedRootSig.GetAddressOf(), errorBlob.GetAddressOf());
-
- if(errorBlob != nullptr)
- {
- ::OutputDebugStringA((char*)errorBlob->GetBufferPointer());
- }
- ThrowIfFailed(hr);
-
- ThrowIfFailed(md3dDevice->CreateRootSignature(
- 0,
- serializedRootSig->GetBufferPointer(),
- serializedRootSig->GetBufferSize(),
- IID_PPV_ARGS(mPostProcessRootSignature.GetAddressOf())));
- }
这个根签名的定义为:根参数槽0指向一个常量缓冲区、根参数槽1指向一个SRV、根参数槽2指向一个UAV。在分派调用开始之前,我们先要为计算着色器绑定常量数据与资源描述符以供其使用:
- cmdList->SetComputeRootSignature(rootSig);
-
- cmdList->SetComputeRoot32BitConstants(0, 1, &blurRadius, 0);
- cmdList->SetComputeRoot32BitConstants(0, (UINT)weights.size(), weights.data(), 1);
-
- cmdList->SetComputeRootDescriptorTable(1, mBlur0GpuSrv);
- cmdList->SetComputeRootDescriptorTable(2, mBlur1GpuUav);
-
- UINT numGroupsX = (UINT)ceilf(mWidth/256.f);
- cmdList->Dispatch(numGroupsX, mHeight, 1);
③利用索引对纹理进行采样:
纹理元素可以借助2D索引加以访问,上述程序中,我们基于分派的线程ID来索引纹理。而每个线程都要被指定一个唯一的调度ID(调度标识符)。
- [numthreads(16, 16, 1)]
- void CS(int3 dispatchThreadID : SV_DispatchThreadID)
- {
- gOutput[dispatchThreadID.xy] =
- gInputA[dispatchThreadID.xy] +
- gInputB[dispatchThreadID.xy];
- }
假设我们为处理纹理而分发了足够多的线程组(即利用一个线程来处理一个单独的纹素),那么这段代码会将两个纹理图像的对应数据进行累加,再将结果存于纹理gOutput中。
系统对计算着色器中的索引越界行为有着明确的定义。越界的读操作总是返回0,而向越界处写入数据时却不会实际执行任何操作(no-ops)[Boyd08]。
由于计算着色器运行在GPU上,因此便可以将它作为访问GPU的一般工具,特别是在通过纹理过滤来对纹理进行采样的时候。这个过程中存在的两点问题:
①我们不能使用Sample方法,而是采用SampleLevel方法:SampleLevel需要第3个额外的参数,用以指定纹理的mipmap层级,因为GS并不可直接参与渲染,所以无法通过像Sample方法那样(根据屏幕上纹理所覆盖的像素数量而自动选择最佳的mipmap层级),所以必须手动指定mipmap层级。mipmap层级的参数,0表示最高级别,1表示第二级别,以此类推,如果是小数,则使用线性过滤在两个mipmap层级之间插值;
②当我们对纹理进行采样时,会使用范围为[0,1]^2的归一化纹理坐标,而非整数索引。此时,为了计算出u、v,我们可以将纹理大小width、height设置为一个常量缓冲区变量,再利用整数索引(x,y)来求取归一化纹理坐标 -- u=x/width v=y/height
下列代码展示了一个使用整数索引的计算着色器,而第二个功能相同的版本则采用了纹理坐标与SampleLevel函数。这里我们假设纹理的大小为512×512,且仅使用最高的mipmap层级:
- // 版本1:使用整数索引
- cbuffer cbUpdateSettings
- {
- float gWaveConstant0;
- float gWaveConstant1;
- float gWaveConstant2;
-
- float gDisturbMag;
- int2 gDisturbIndex;
- };
-
- RWTexture2D<float> gPrevSolInput : register(u0);
- RWTexture2D<float> gCurrSolInput : register(u1);
- RWTexture2D<float> gOutput : register(u2);
-
- [numthreads(16, 16, 1)] // 一个线程组里有16×16×1=256个线程
- void CS(int3 dispatchThreadID : SV_DispatchThreadID)
- {
- int x = dispatchThreadID.x;
- int y = dispatchThreadID.y;
-
- gOutput[int2(x,y)] =
- gWaveConstant0 * gPrevSolInput[int2(x,y)].r +
- gWaveConstant1 * gPrevSolInput[int2(x,y)].r +
- gWaveConstant2 * (
- gCurrSolInput[int2(x,y+1)].r +
- gCurrSolInput[int2(x,y-1)].r +
- gCurrSolInput[int2(x+1,y)].r +
- gCurrSolInput[int2(x-1,y)].r
- );
- }
-
-
- // 版本2:使用函数SampleLevel与纹理坐标
- cbuffer cbUpdateSettings
- {
- float gWaveConstant0;
- float gWaveConstant1;
- float gWaveConstant2;
-
- float gDisturbMag;
- int2 gDisturbIndex;
- };
-
- SampleState samPoint : register(s0);
-
- RWTexture2D<float> gPrevSolInput : register(u0);
- RWTexture2D<float> gCurrSolInput : register(u1);
- RWTexture2D<float> gOutput : register(u2);
-
- [numthreads(16, 16, 1)]
- void CS(int3 dispatchThreadID : SV_DispatchThreadID)
- {
- // 相当于SampleLevel()取代运算符[]
- int x = dispatchThreadID.x;
- int y = dispatchThreadID.y;
-
- // 除以长/宽 512×512
- float2 c = float2(x,y)/512.f;
- float2 t = float2(x,y-1)/512.f;
- float2 b = float2(x,y+1)/512.f;
- float2 l = float2(2-1,y)/512.f;
- float2 r = float2(x+1,y)/512.f;
-
- gOutput[int2(x,y)] =
- gWaveConstant0 * gPrevSolInput.SampleLevel(samPoint, c, 0.f).r +
- gWaveConstant1 * gPrevSolInput.SampleLevel(samPoint, c, 0.f).r +
- gWaveConstant2 * (
- gCurrSolInput.SampleLevel(samPoint, b, 0.f).r +
- gCurrSolInput.SampleLevel(samPoint, t, 0.f).r +
- gCurrSolInput.SampleLevel(samPoint, r, 0.f).r +
- gCurrSolInput.SampleLevel(samPoint, l, 0.f).r
- );
- }
④结构化缓冲区资源:
👇示例展示如何通过HLSL来定义结构化缓冲区:
- struct Data
- {
- float3 v1;
- float2 v2;
- };
-
- StructuredBuffer<Data> gInputA : register(t0);
- StructuredBuffer<Data> gInputB : register(t1);
- RWStructuredBuffer<Data> gOutput : register(u0);
-
结构化缓冲区是一种由相同类型元素所构成的简单缓冲区 -- 本质上是一种数组。正如我们所看到的,该元素类型可以是用于以HLSL定义的结构体。
我们可以把为顶点缓冲区与索引缓冲区创建SRV的方法同样用于创建结构化缓冲区的SRV。除了"必须指定D3D12_RESOURCE_FLAG_ALLOW_UNORDERED_ACCESS标志"这一条之外,将结构化缓冲区用作UAV也与之前的操作基本一致。设置此标志的目的是用于把资源转换为D3D12_RESOURCE_STATE_UNORDERED_ACCESS状态。
- struct Data
- {
- XMFLOAT3 v1;
- XMFLOAT2 V2;
- };
-
- // 生成一些数据来填充SRV缓冲区
- std::vector<Data> dataA(NumDataElements);
- std::vector<Data> dataB(NumDataElements);
- for(int i=0; i < NumDataElements; ++i)
- {
- dataA[i].v1 = XMFLOAT3(i, i, i);
- dataA[i].v2 = XMFLOAT2(i, 0);
-
- dataB[i].v1 = XMFLOAT3(-i, i, 0.F);
- dataB[i].v2 = XMFLOAT2(0, -i);
- }
-
- UINT64 byteSize = dataA.size() * sizeof(Data);
-
- // 创建若干缓冲区用作SRV
- mInputBufferA = d3dUtil::CreateDefaultBuffer(
- md3dDevice.Get(),
- mCommandList.Get(),
- dataA.data(),
- byteSize,
- mInputUploadBufferA
- );
-
- mInputBufferB = d3dUtil::CreateDefaultBuffer(
- md3dDevice.Get(),
- mCommandList.Get(),
- dataB.data(),
- byteSize,
- mInputUploadBufferA
- );
-
- // 创建用作UAV的缓冲区
- ThrowIfFailed(md3dDevice->CreateCommittedResource(
- &CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT),
- D3D12_HEAP_FLAG_NONE,
- &CD3DX12_RESOURCE_DESC::Buffer(byteSize,
- D3D12_RESOURCE_FLAG_ALLOW_UNORDERED_ACCESS),
- D3D12_RESOURCE_STATE_UNORDERED_ACCESS,
- nullptr,
- IID_PPV_ARGS(&mOutputBuffer)
- ));
结构化缓冲区可以像纹理那样与流水线相绑定。我们为它们创建SRV或UAV的描述符,再将这些描述符作为参数传入需要获取描述符表的根参数。或者,我们还能定义以根描述符为参数的根签名,由此便可以将资源的虚拟地址作为根参数直接进行传递,而无须涉及描述符堆(这种方式仅限于创建缓冲区资源的SRV或UAV,并不适用于纹理)。
根签名描述:
- CD3DX12_ROOT_PARAMETER slotRootParameter[3];
-
- slotRootParameter[0].InitAsShaderResourceView(0);
- slotRootParameter[1].InitAsShaderResourceView(1);
- slotRootParameter[2].InitAsUnorderedAccessView(0);
-
- CD3DX12_ROOT_SIGNATURE_DESC rootSigDesc(3, slotRootParameter, 0, nullptr,
- D3D12_ROOT_SIGNATURE_FLAG_NONE);
-
- // 接下来,我们就能绑定所创建的缓冲区以供分派调用使用:
- mCommandList->SetComputeRootSignature(mRootSignature.Get());
- mCommandList->SetComputeRootShaderResourceView(0, mInputBufferA->GetGPUVirtualAddress());
- mCommandList->SetComputeRootShaderResourceView(1, mInputBufferB->GetGPUVirtualAddress());
- mCommandList->SetComputeRootUnorderedAccessView(2, mOutputBuffer->GetGPUVirtualAddress());
-
- mCommandList->Dispatch(1, 1, 1);
-
还有一种名为原始缓冲区(raw buffer)的资源,从本质上来讲,它是用字节数组来表示数据的。我们可以通过字节偏移量来找到所需数据的位置,再将它按适当的类型进行强制转换以获取数据。对于有多种不同类型的数据存于同一缓冲区的情况来说,这种资源可谓是一股清流啊!要创建原始缓冲区资源,必须用DXGI_FORMAT_R32_TYPELESS的格式,而在创建对应的UAV时,一定要使用D3D12_BUFFER_UAV_FLAG_RAW标志。本书不会使用这种原始缓冲区资源,想要了解请参考SDK文档。
⑤将计算着色器的执行结果复制到系统内存:
一般来说,在用CS对纹理进行处理之后,我们就会将结果在屏幕上显示出来,并根据呈现的效果来验证计算着色器的准确性。但是,如果使用结构化缓冲区参与运算,或使用GPGPU进行通用计算,则计算结果可能根本无法显示出来。所以当前燃眉之急是如何将GPU端显存(通过UAV向结构化缓冲区写入数据时,缓冲区其实是位于显存中的)里的运算结构回传至系统内存。
首先以堆属性D3D12_HEAP_TYPE_READBACK来创建系统内存,再通过ID3D12GraphicsCommandList::CopyResource方法将GPU资源复制到系统内存资源之中。其次,系统内存资源必须与待复制的资源有着相同的类型与大小。最后,还需用映射API函数对系统内存缓冲区进行映射,使CPU可以顺利地读取其中地数据。
本章包含一个名为"VecAdd"地结构化缓冲区演示程序,它的功能比较简单,就是将分别存于两个结构化缓冲区中地向量地对应分量进行求和运算:
- struct Data
- {
- float3 v1;
- float2 v2;
- };
-
- StructuredBuffer<Data> gInputA : register(t0);
- StructuredBuffer<Data> gInputB : register(t1);
- RWStructuredBuffer<Data> gOutput : register(u0);
-
- [numthreads(32, 1, 1)]
- void CS(int3 dtid : SV_DispatchThreadID)
- {
- gOutput[dtid.x].v1 = gInputA[dtid.x].v1 + gInputB[dtid.x].v1;
- gOutput[dtid.x].v2 = gInputA[dtid.x].v2 + gInputB[dtid.x].v2;
- }
为了方便起见,我们使每个结构化缓冲区中仅含32个元素。因此,只需分派一个线程组即可(因为一个线程组即可同时处理32个数据元素)。待程序中的所有线程都完成CS的运算任务之后,我们将结果复制到系统内存,再保存于文件当中。
示例:创建系统内存缓冲区,以及怎样将GPU中的计算结果复制到CPU的内存:
- // 创建一个系统内存缓冲区,以便读回处理结果
- ThrowIfFailed(md3dDevice->CreateCommittedResource(
- &CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_READBACK), // readback
- D3D12_HEAP_FALG_NONE,
- &CD3DX12_RESOURCE_DESC::Buffer(byteSize),
- D3D12_RESOURCE_STATE_COPY_DESC,
- nullptr,
- IID_PPV_ARGS(&mReadBackBuffer)
- ));
-
- // .. 待CS处理完毕
- struct Data
- {
- XMFLOAT3 v1;
- XMFLOAT2 v2;
- };
-
- // 按计划将数据从默认缓冲区复制到回读缓冲区(即系统内存缓冲区)中
- mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIRER::Transition(
- mOutputBuffer.Get(),
- D3D12_RESOURCE_STATE_COMMON,
- D3D12_RESOURCE_STATE_COPY_SOURCE
- ));
-
- mCommandList->CopyResource(mReadBackBuffer.Get(), mOutputBuffer.Get());
-
- mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(
- mOutputBuffer.Get(),
- D3D12_RESOURCE_STATE_COPY_SOURCE,
- D3D12_RESOURCE_STATE_COMMON
- ));
-
- // 命令记录完成
- ThrowIfFailed(mCommandList->Close());
-
- // 将命令列表添加到命令队列中用于执行
- ID3D12CommandList* cmdsLists[] = { mCommandList.Get() };
- mCommandQueue->ExecuteCommandLists(_countof(cmdsLists), cmdsLists);
-
- FlushCommandQueue();
-
- // 对数据进行映射,以便CPU读取
- Data* mappedData = nullptr;
- ThrowIfFailed(mReadBackBuffer->Map(0, nullptr, reinterpret_cast<void**>(&mappedData)));
-
- std::ofstream fout("results.txt");
- for(int i = 0; i < NumDataElements; ++i)
- {
- fout << "(" << mappedData[i].v1.x << ", " <<
- mappedData[i].v1.y << ", " <<
- mappedData[i].v1.z << ", " <<
- mappedData[i].v2.x << ", " <<
- mappedData[i].v2.y << ") " << std::endl;
- }
-
- mReadBackBuffer->Unmap(0, nullptr);
在这个演示程序中,我们用下列初始数据来填写两个输入缓冲区:
- std::vector<Data> dataA(NumDataElements);
- std::vector<Data> dataB(NumDataElements);
- for(int i=0; i<NumDataElements; ++i)
- {
- dataA[i].v1 = XMFLOAT3(i,i,i);
- dataA[i].v2 = XMFLOAT2(i,0);
- dataB[i].v1 = XMFLOAT3(-i,i,0.f);
- dataB[i].v2 = XMFLOAT2(0, -i);
- }
我们可以在文本文件中观察CS处理的结果。
注意:X、Y、Z是符合左手坐标系,且X、Y类似uv纹理纹理坐标系一样。且调度线程ID假设是(x,y,z):代表的是第y行,第x列,而不是第x行,第y列[⭐:这个顺序与普通矩阵的记法刚好相反]
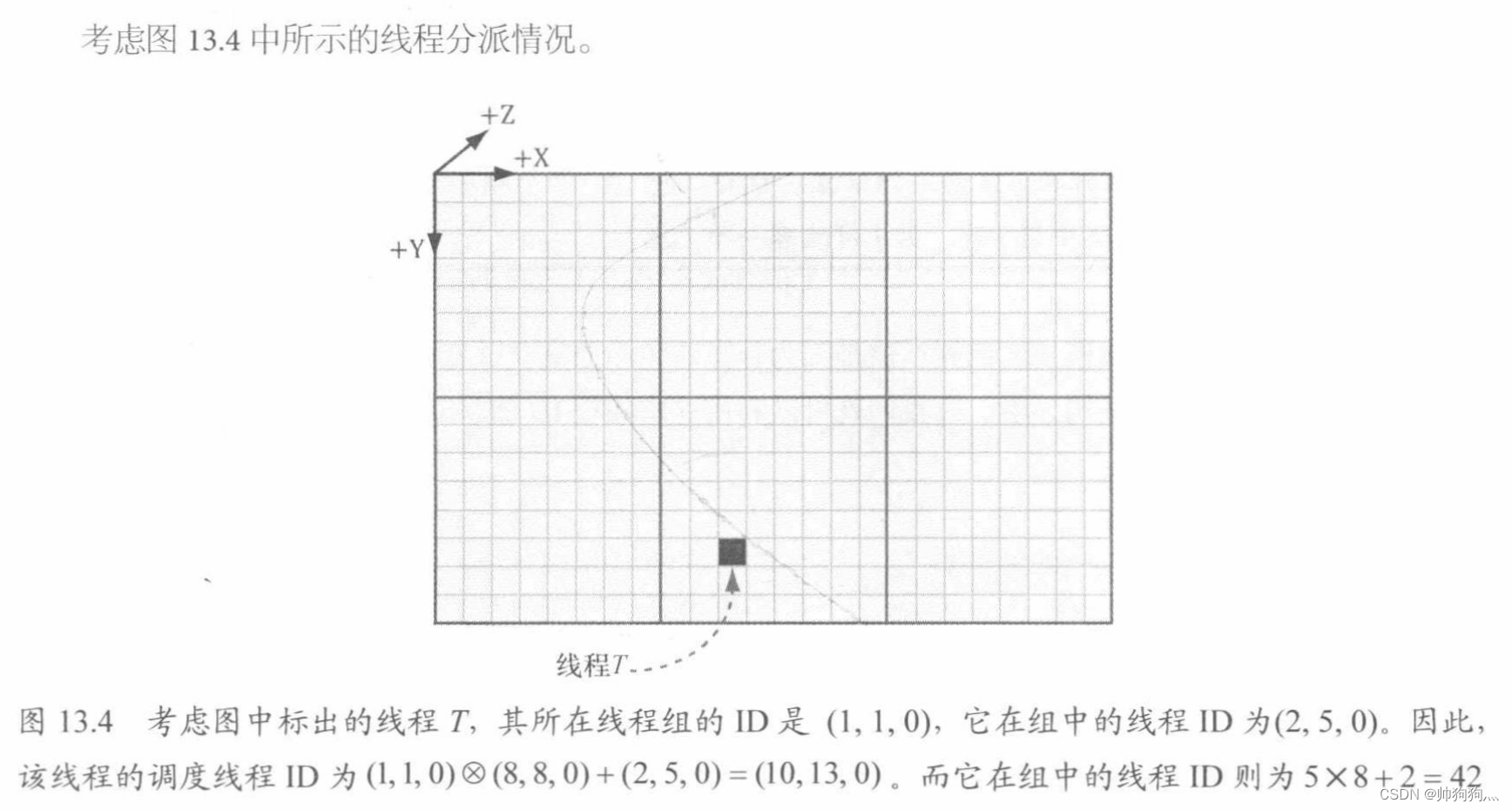
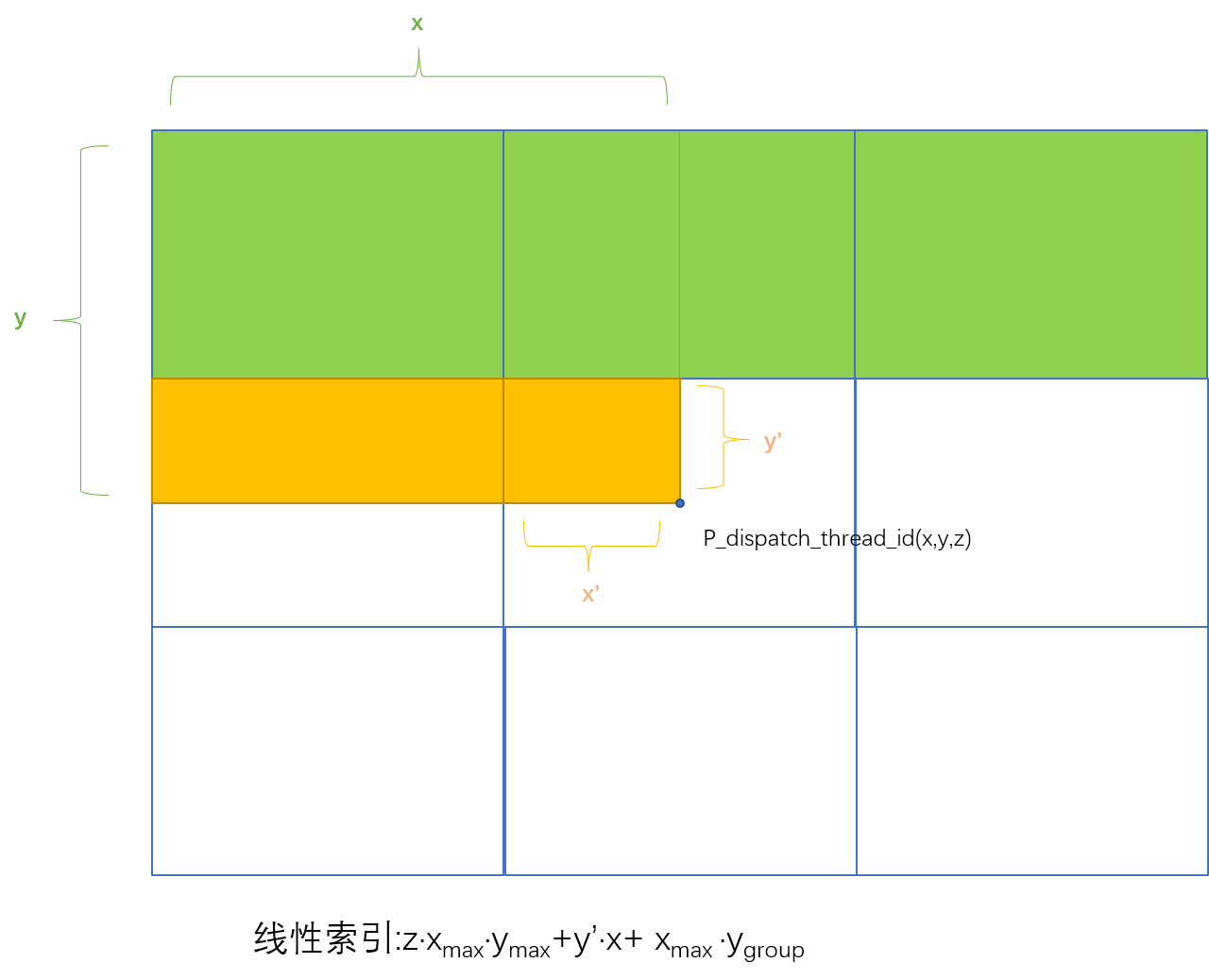
假设线程组的规模ThreadGroupSize=(X,Y,Z),那么我们便可以根据线程组ID与组内线程ID,通过以下方法推算出调度线程ID:
- dispatchThreadID.xyz = groupID.xyz * ThreadGroupSize.xyz + groupThreadID.xyz;
- // 调度线程ID = 线程组ID × 每个线程组中线程个数 + 组内线程ID
为什么需要给这些线程ID值呢?这是因为计算着色器通常会以若干数据结构作为输入,再将计算结果输出到另一些数据结构之中。而我们就可以利用这些线程ID值来对这些数据结构进行索引:
- Texture2D gInputA;
- Texture2D gInputB;
- RWTexture2D gOutput;
-
-
- [numthreads(16, 16, 1)]
- void CS(int3 dispatchThreadID : SV_DispatchThreadID) // 调度线程ID 0~16*16-1
- {
- gOutput[dispatchThreadID.xy] =
- gInputA[dispatchThreadID.xy] +
- gInputB[dispatchThreadID.xy];
- }
利用SV_GroupThreadID系统值即可极为便利地对线程的本地存储器(local storage memory)进行索引(参考下下节)。
假设我们通过以下结构体定义了一个存有粒子数据地缓冲区:
- struct Particle
- {
- float3 Position;
- float3 Velocity;
- float3 Acceleration;
- };
并希望基于粒子的速度与恒定加速度在计算着色器中对其位置进行更新。此外我们还假定不必考虑粒子的更新顺序以及它们被写入输出缓冲区的顺序。
消费结构化缓冲区(consume structured buffer, 一种输入缓冲区)与追加结构缓冲区(append structured buffer, 一种输出缓冲区)便应运而生。若使用了这两种缓冲区,我们也就不必再索引问题上花心思了:
- struct Particle
- {
- float3 Position;
- float3 Velocity;
- float3 Acceleration;
- };
-
- float TimeStep = 1.f/60.f;
-
- ConsumeStructuredBuffer<Particle> gInput;
- AppendStructuredBuffer<Particle> gOutput;
- [numthreads(16, 16, 1)]
- void CS()
- {
- // 对输入缓冲区中的数据元素之一进行处理(即消费,从缓冲区中移除一个元素)
- Particle p = gInput.Comsume();
-
- p.Velocity += p.Acceleration * TimeStep;
- p.Position += p.Velocity*TimeStep;
-
- // 将规范化向量追加到输出缓冲区
- gOutput.Append(p);
- }
数据元素一旦被处理(即消费),其他线程就不能对它进行任何操作了(因为从消费缓冲区中移除了)。而且,一个线程也只能处理一个数据元素。除此之外,我们无法知晓数据元素的具体处理顺序与追加顺序。一般某元素在输入缓冲区的位置与处理后写入输出缓冲区的位置并不是一一对应的。
追加结构化缓冲区的空间是不能动态扩展的,只是它有足够的空间来容纳我们追加的所有元素。
每个线程组都有一块称为共享内存(shared memory)或线程本地存储器(thread local storage)的内存空间。这种内存的访问速度很快,可认为与硬件告诉缓存的速度不相上下。在CS代码中,共享内存的声明如下:
groupshared float4 gCache[256];cpp运行数组大小可依用户的需求而定,但是线程组共享内存的上限为32kb。由于共享内存是线程组里的本地内存,所以要通过SV_GroupThreadID语义对它进行索引。据此,我们可以使组内的每个线程都来访问共享内存中的同一个元素。
使用过多的共享内存会引发性能问题[Fung10],下面给出例子对此进行详解。假设有一款最多支持32KB共享内存的多处理器,而用户的计算着色器则需要共享内存20KB。因为20KB+20KB=40KB>32KB,这意味着最多只能为每个多处理器设置一个线程组,而没有足够的共享内存供另一个线程组使用。{一个线程组共同使用一个区域的共享内存,因为CS需要20KB,所以一个线程组的共享内存至少是20KB,而多处理器的总共享内存只有32KB,所以只能跑一个线程组} -- 这样一来限制了GPU的并发性,多处理器无法在多个线程组之间进行切换而屏蔽处理过程中的延迟。因此,虽然这款硬件在技术上仅支持32KB的共享内存,但是通过缩减内存的使用量却能令性能得到优化。
共享内存常用的应用场景是存储纹理数据。在特定的算法中,例如模糊图像(blur),需要对同一个纹素进行多次拾取。纹理采样是一种速度较慢的GPU操作,因为内存带宽与内存延迟还未能像GPU的计算能力那样得到极大的改善[Möller08]。但是,我们可以将线程组所需的纹理样本全部预加载至共享内存块,以此来避免密集的纹理拾取操作所带来的性能下滑。接下来,算法流程便会在共享内存块中查找纹理样本并进行处理,此时的处理速度就很快乐。
共享内存中如何处理同步问题:同步命令
- Texture2D gInput;
- RWTexture2D<float4> gOutput;
-
- groupshared float4 gCache[256];
-
- [numthreads(256, 1, 1)]
- void CS(int3 groupThreadID : SV_GroupThreadID,
- int3 dispatchThreadID : SV_DispatchThreadID)
- {
- // 每个线程都对纹理进行采样,将采集数据存储在共享内存中
- gCache[groupThreadID.x] = gInput[dispatchThreadID.xy];
-
- // 同步命令:等待组内的所有线程都完成各自的任务
- GroupMemoryBarrierWithGroupSync();
-
- // 此时,读取共享内存的任意元素并执行计算任务都是安全的
- float4 left = gCache[groupThreadID.x - 1];
- float4 right = gCache[groupThreadID.x + 1];
-
- ...
- }
①图像模糊理论:
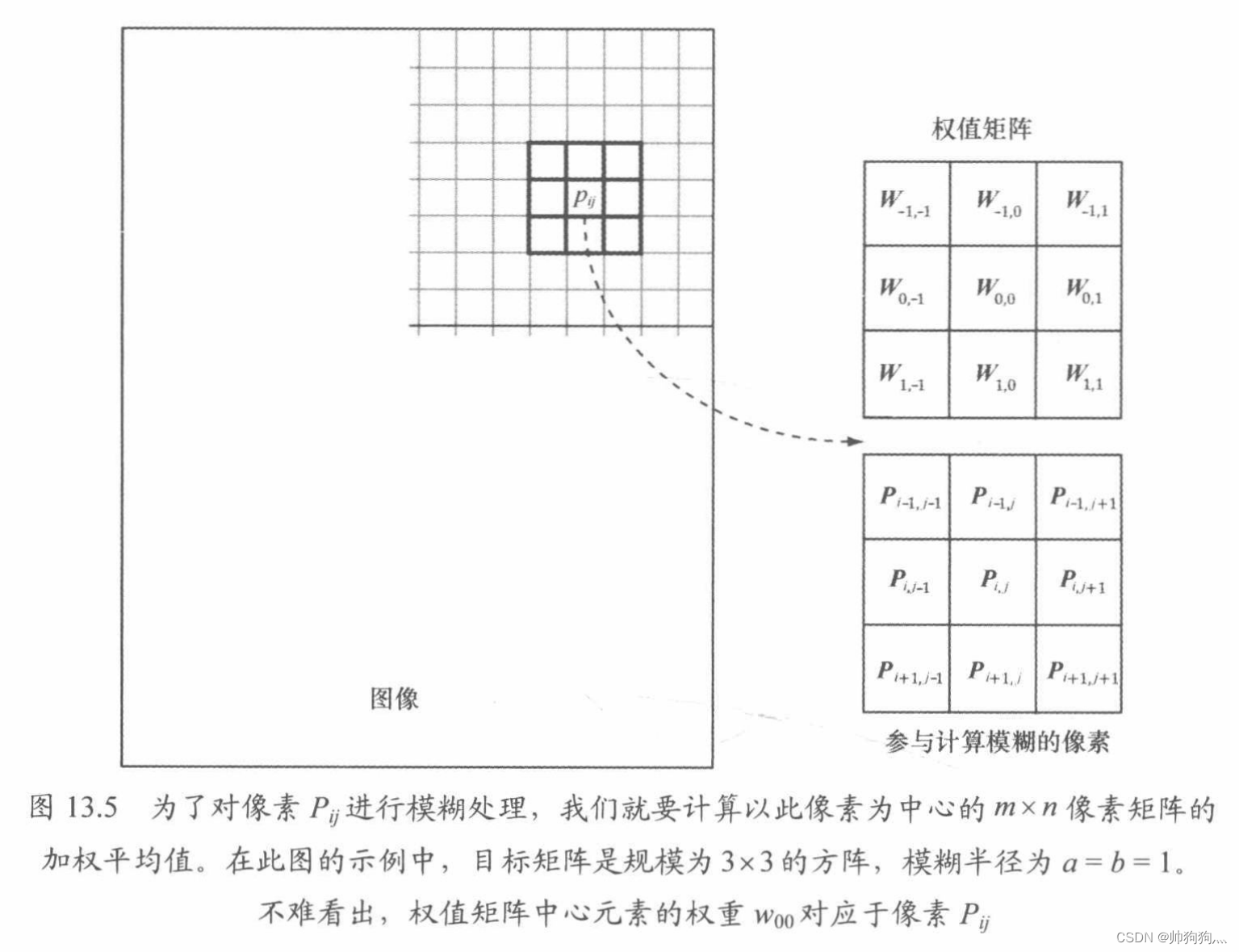
图像的模糊算法描述如下:针对源图像中的每一个像素 ,计算以它为中心的m×n矩阵的加权平均值[类似马赛克]。此加权平均值便是经模糊处理后图像第i行、第j列的像素颜色。用数学公式来表示即为:
满足:
其中:m=2a+1且n=2b+1。将m与n强制为奇数,以此来保证m×n矩阵总是具有"中心"项。我们称a为垂直模糊半径,b为水平模糊半径。若a=b,则只需指定模糊半径(blur radius)即可确定矩阵的大小。m×n权值矩阵称为模糊核(blur kernel, 模糊内核)。权值和必为1,如果小于1,则模糊后的图像会随着颜色的确实而显得更暗,大于1则更亮。
在保证权值和为1的前提下,我们就能用多种不同的方法来计算它。在大多数图像编辑软件中,我们能发现一种广为人知的模糊算法:高斯模糊(Gaussian blur)。此算法借助高斯函数 来获取权值。图展示了取不同σ值时高斯函数的对应图像。
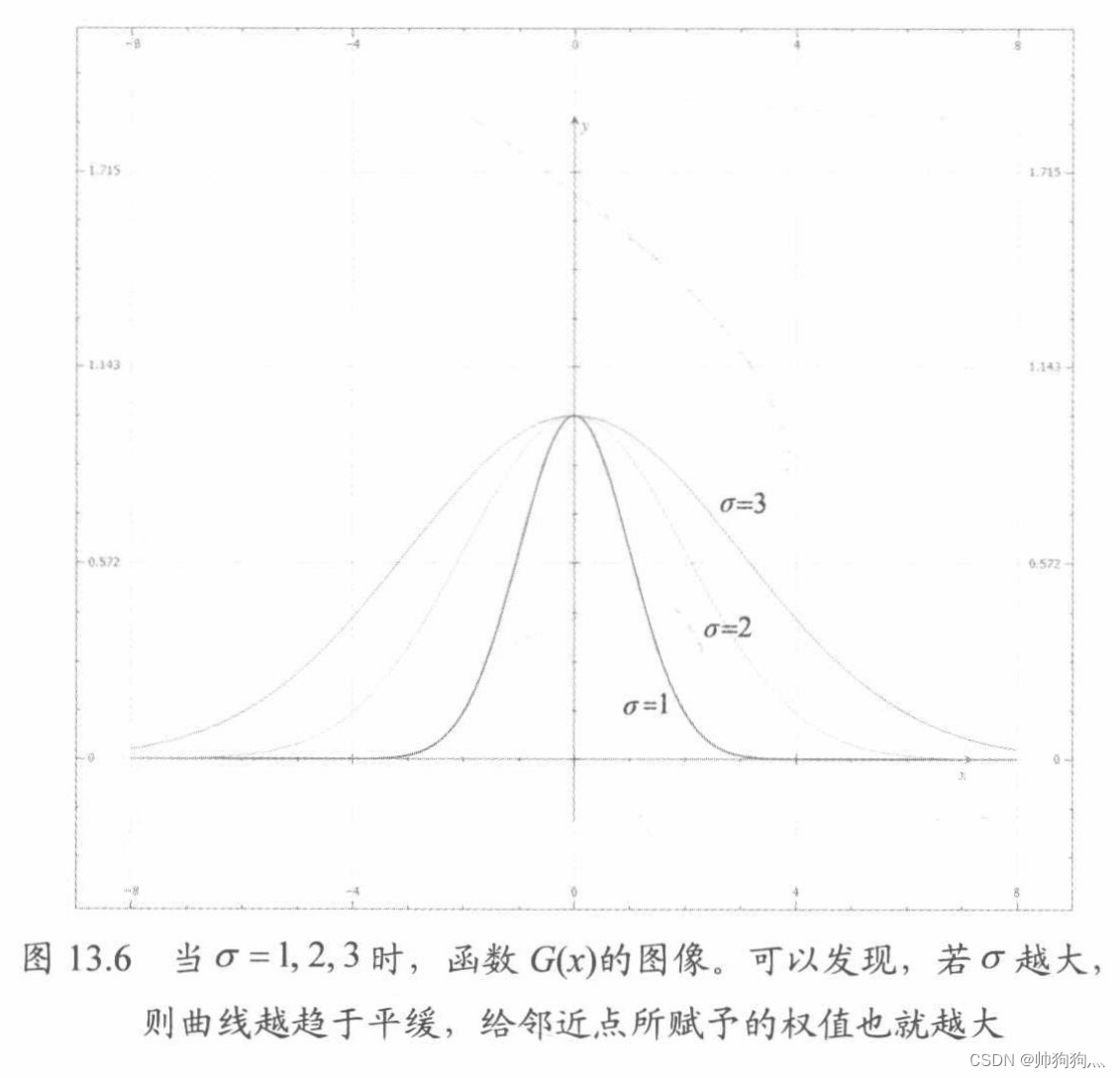
注意,观察图像,明显给σ不同的值,权值之和不为1。解决办法:除以各项权值之和。
示例,假设我们进行1×5的高斯模糊,且设σ=1。分别对x=-2,-1,0,1,2求取G(x)的值[各项的权值],我们有:
,以此求出
高斯模糊最著名的莫过于它的可分离性,根据这条性质,我们可以像下面那样将它分为两个1D模糊过程:
对公式简化一番,我们得到:
假设模糊核为一个9×9矩阵,如果像之前,就需要对81个样本进行2D模糊计算,但是采用模拟分离,只需要对9+9=18个样本。之前提过,拾取纹理样本是代价高昂的操作,所以通过分离模糊过程来减少采样操作是一种受用户欢迎的优化手段。有些时候,尽管模糊方法不具有分离性,但是只要保证最终图像在视觉上足够精确,我们还是能以优化性能为目的而简化其模糊过程。
②渲染到纹理技术:
之前我们一直都在程序中向后台缓冲区渲染数据,后台缓冲区其实是一种位于交换链中的纹理,在D3DApp的部分代码如下:
- Microsoft::WRL::ComPtr<ID3D12Resource> mSwapChainBuffer[SwapChainBufferCount];
- CD3DX12_CPU_DESCRIPTOR_HANDLE rtvHeapHandle(mRtvHeap->GetCPUDescriptorHandleForHeapStart());
- for(UINT i = 0; i < SwapChainBufferCount; i++)
- {
- ThrowIfFailed(mSwapChain->GetBuffer(i, IID_PPV_ARGS(&mSwapChainBuffer[i])));
- md3dDevice->CreateRenderTargetView(mSwapChainBuffer[i].Get(), nullptr, rtvHeapHandle);
- rtvHeapHandle.Offset(i, mRtvDescriptorSize);
- }
通过将后台缓冲区的渲染目标视图(RTV)与渲染流水线的输出合并(Output Merger,OM)阶段相绑定,使Direct3D将数据渲染至后台缓冲区中:
mCommandList->OMSetRenderTargets(1, &CurrentBackBufferView(), true, &DepthStencilView());cpp运行再通过IDXGISwapChain::Present方法呈现后台缓冲区,将其中的数据呈现在屏幕上
用作渲染目标的纹理一定要以D3D12_RESOURCE_FLAG_ALLOW_RENDER_TARGET标志来创建。
通过认真分析上述👆代码可以发现,可以畅通无阻地创建另一个纹理,再为它创建RTV(渲染目标视图),再将它绑定到渲染流水线的OM阶段之上。由此,我们就能够将数据绘制到这种全然不同的“离屏”(off-screen)纹理之中。这就是著名的渲染到纹理(render-to-texture)。这种纹理与后台缓冲区的唯一不同之处在于:在执行提交操作(present,呈现)的过程中,它无法显示在屏幕上。
渲染到纹理的作用:我们可以将生成的纹理为几何体贴图,另外,还可以实现各种特殊效果,比如将鸟瞰图绘制在屏幕右下角的小方框中。其他比较经典的应用:①阴影贴图shadow mapping②屏幕空间环境光遮蔽(screen space ambient occlusion, SSAO)③动态反射与立方体图(dynamic reflections with cube maps)。
我们使用渲染到纹理技术实现模糊算法的具体步骤如下:首先将场景按寻常方式渲染到离屏纹理上,该纹理会被输入至计算着色器中并执行模糊算法。待纹理经模糊处理后,我们会将所得纹理绘制为全屏四边形(full screen quad)并送到后台缓冲区,由此便可根据模糊效果来检验模糊的实现。流程中的关键步骤:
假设离屏纹理与后台缓冲区的大小及格式相匹配,我们就能采用间接绘制到离屏纹理的方式代之:像之前一样先将纹理渲染到后台缓冲区,再把后台缓冲区的内容用CopyResource方法复制到离屏纹理。接下来,在离屏纹理上开展计算工作,再将模糊后的纹理绘制为全屏四边形送至后台缓冲区,以生成最终的屏幕输出。
- // 将input(这里是后台缓冲区资源)复制到BlurMap0
- cmdList->CopyResource(mBlurMap0.Get(), input);
上述过程中,我们先使用渲染流水线,再使用计算着色器,最后再换回普通的渲染流水线。一般来讲,我们应该尝试避免在渲染与计算工作之间的往复切换行为,因为切换会产生开销。但是,对于上述过程来说,确实不能完全避免切换行为,所以我们可以尝试将切换的次数降到最低。
③图像模糊的实现概述:
假设模糊算法具有可分离性,我们将模糊操作分为两个1D模糊运算。实现这种算法需要两个可读写的纹理缓冲区,所以需要为两个纹理分别创建SRV与UAV。我们称这两个纹理为A和B。模糊算法的处理如下:
纹理A与B在某些时刻分别充当了计算着色器的输入与输出,但是无法同时担任两种角色(在将一个资源同时绑定为着色器的输入与输出之时,Direct3D便会报错)。我们甚至可以对处理后的图像再次(多次)进行模糊处理,使它变得愈加模糊,直到达到满意的效果。
由于渲染到纹理的场景与窗口工作区要保持着相同的分辨率,因此我们需要不时重新构建离屏纹理,而模糊算法所用的第二个纹理B的缓冲区也是如此。通过OnResize方法来实现:
- void BlurApp::OnResize()
- {
- D3DApp::OnResize();
-
- // 窗口大小有了变换,所以需要更新纵横比,并重新计算投影矩阵
- XMMATRIX P = XMMatrixPerspectiveFovLH(
- 0.25*MathHelper::Pi, AspectRatio(),
- 1.f, 1000.f
- );
- XMStoreFloat4x4(&mProj, P);
- if(mBlurFilter != nullptr)
- {
- mBlurFilter->OnResize(mClientWidth,mClientHeight);
- }
- }
-
- void BlurFilter::OnResize(UINT newWidth, UINT newHeight)
- {
- if((mWidth != newWidth) || (mHeight != newHeight))
- {
- mWidth = newWidth;
- mHeight = newHeight;
-
- // 以新的大小来重新构建离屏纹理资源
- BuildResources();
-
- // 既然创建了新的资源,我们也应当为其创建新的描述符
- BuildDescriptors();
- }
- }
变量mBlurFilter是我们所编写的BlurFilter辅助类实例,此类不仅封装了纹理AB的SRV、UAV和纹理资源,还提供了开启计算着色器实际模糊运算的方法。这个辅助类BlurFilter的具体实现:
- void BlurFilter::BuildDescriptor(
- CD3DX12_CPU_DESCRIPTOR_HANDLE hCpuDescriptor,
- CD3DX12_GPU_DESCRIPTOR_HANDLE hGpuDescriptor,
- UINT descriptorSize
- )
- {
- // 保存对描述符的引用
- mBlur0CpuSrc = hCpuDescriptor;
- mBlur0CpuUav = hCpuDescriptor.Offset(1, descriptorSize);
- mBlur1CpuSrv = hCpuDescriptor.Offset(1, descriptorSize);
- mBlur1CpuUav = hCpuDescriptor.Offset(1, descriptorSize);
-
- mBlur0GpuSrc = hGpuDescriptor;
- mBlur0GpuUav = hGpuDescriptor.Offset(1, descriptorSize);
- mBlur1GpuSrv = hGpuDescriptor.Offset(1, descriptorSize);
- mBlur1GpuUav = hGpuDescriptor.Offset(1, descriptorSize);
-
- BuildDescriptors();
- }
-
- void BlurFilter::BuildDescriptors()
- {
- D3D12_SHADER_RESOURCE_VIEW_DESC srvDesc = {};
- srvDesc.Shader4ComponentMapping = D3D12_DEFAULT_SHADER_4_COMPONENT_MAPPING;
- srvDesc.Format = mFormat;
- srvDesc.ViewDimension = D3D12_SRV_DIMENSION_TEXTURE2D;
- srvDesc.Texture2D.MostDetailedMip = 0;
- srvDesc.Texture2D.MipLevels = 1;
-
- D3D12_UNORDERED_ACCESS_VIEW_DESC uavDesc = {};
-
- uavDesc.Format = mFormat;
- uavDesc.ViewDimension = D3D12_UAV_DIMENSION_TEXTURE2D;
- uavDesc.Texture2D.MipSlice = 0;
-
- md3dDevice->CreateShaderResourceView(mBlurMap0.Get(), &srvDesc, mBlur0CpuSrv);
- md3dDevice->CreateUnorderedAccessView(mBlurMap0.Get(), nullptr, &uavDesc, mBlur0CpuUav);
-
- md3dDevice->CreateShaderResourceView(mBlurMap1.Get(), &srvDesc, mBlur1CpuSrv);
- md3dDevice->CreateUnorderedAccessView(mBlurMap1.Get(), nullptr, &uavDesc, mBlur1CpuUav);
- }
在BlurApp.cpp中调用:
- mBlurFilter->BuildDescriptors(
- CD3DX12_CPU_DESCRIPTOR_HANDLE(mCbvSrvUavDescriptorHeap->GetCPUDescriptorHandleForHeapStart(), 3, mCbvSrvUavDescriptorSize),
- CD3DX12_GPU_DESCRIPTOR_HANDLE(mCbvSrvUavDescriptorHeap->GetGPUDescriptorHandleForHeapStart(), 3, mCbvSrvUavDescriptorSize),
- mCbvSrvUavDescriptorSize
- );

假设要处理的图像宽为w,高为h。正如我们将在下一小节中所看到的计算着色器代码所写,对于1D纵向模糊而言,一个线程组用256个线程[比如:numthread(16,16,1)]来处理水平方向上的线段,而且每个线程又负责图像中的一个像素的模糊操作。因此,为了图像的每个像素都能得到模糊处理,我们需要在x方向上分派ceil(w/256)个线程组(ceil:向上取整函数),且在y方向上调度h个线程组。对于多余的未使用的线程,我们无能为力,因为线程组大小是固定的。因此我们只能把注意力放在着色器代码中越界问题的钳制检测(clamping check)之上。
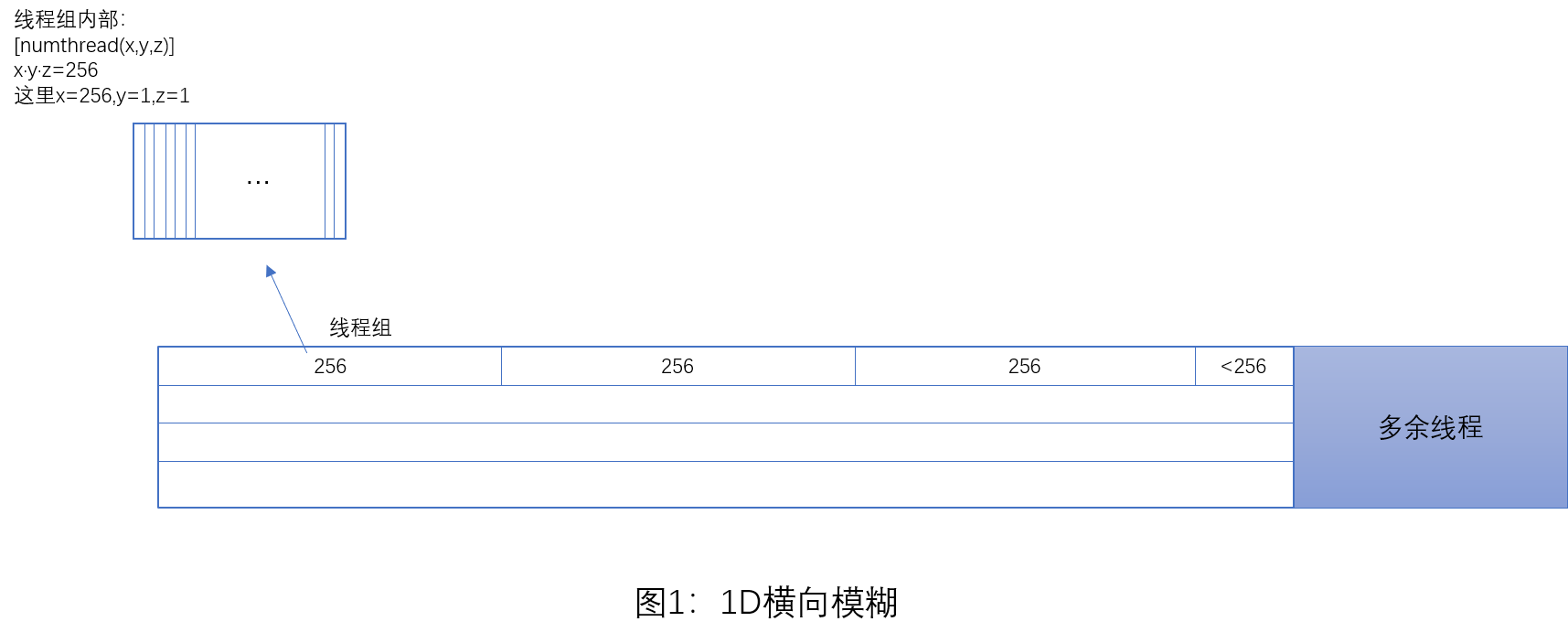
对于👆图1的情况,假设对一个800×600像素的纹理进行处理,我们所采用的横向线程组的规模(是指线程组内部线程分布规模)为256×1,那么,我们需要在x方向上分派ceil(800/256)=4个线程组,在y方向上调度600个线程组。反正原则是:一个线程对应一个像素,将临近的256个或者其他数量的线程归结到一个线程组中。纵向同理,我们可以使用规模为1×256的线程组,然后纵向分配。
下列代码不仅计算了每个方向上要分派的线程组数量,还真正地开启了CS的模糊运算:
- void BlurFilter::Execute(ID3D12GraphicsCommandList* cmdList,
- ID3D12RootSignature* rootSig,
- ID3D12PipelineState* horzBlurPSO,
- ID3D12PipelineState* vertBlurPSO,
- ID3D12Resource* input, // 后台缓冲区资源
- int blurCount)
- {
- auto weights = CalcGaussWeights(2.5f);
- int blurRadius = (int)weights.size() / 2;
-
- cmdList->SetComputeRootSignature(rootSig); // 设置计算根签名
-
- // 设置对应的根参数
- cmdList->SetComputeRoot32BitConstants(0, 1, &blurRadius, 0);
- cmdList->SetComputeRoot32BitConstants(0, (UINT)weights.size(), weights.data(), 1);
-
- // 资源转换(后台缓冲区资源):渲染目标->复制源
- cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(input,
- D3D12_RESOURCE_STATE_RENDER_TARGET, D3D12_RESOURCE_STATE_COPY_SOURCE));
-
- // 资源转换(离屏纹理):COMMON->复制目的地
- cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(mBlurMap0.Get(),
- D3D12_RESOURCE_STATE_COMMON, D3D12_RESOURCE_STATE_COPY_DEST));
-
- // 使用CopyResource复制后台缓冲区内容到离屏纹理
- cmdList->CopyResource(mBlurMap0.Get(), input);
-
- // 资源转换(离屏纹理):复制目的地->读状态的逻辑OR组合
- cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(mBlurMap0.Get(),
- D3D12_RESOURCE_STATE_COPY_DEST, D3D12_RESOURCE_STATE_GENERIC_READ));
-
- // 资源转换(blur算法的中间纹理):COMMON->用于无序访问
- cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(mBlurMap1.Get(),
- D3D12_RESOURCE_STATE_COMMON, D3D12_RESOURCE_STATE_UNORDERED_ACCESS));
-
- for(int i = 0; i < blurCount; ++i)
- {
- //
- // 水平方向的模糊处理
- //
-
- cmdList->SetPipelineState(horzBlurPSO);
-
- cmdList->SetComputeRootDescriptorTable(1, mBlur0GpuSrv);
- cmdList->SetComputeRootDescriptorTable(2, mBlur1GpuUav);
-
- // 若每个线程组能处理256个像素(GS中定义的,注意线程组中线程:256*1*1),那么处理一行像素需要分配的线程组个数
- UINT numGroupsX = (UINT)ceilf(mWidth / 256.0f);
- cmdList->Dispatch(numGroupsX, mHeight, 1);
-
- // 资源转换(离屏纹理):读状态的逻辑或->无序访问
- cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(mBlurMap0.Get(),
- D3D12_RESOURCE_STATE_GENERIC_READ, D3D12_RESOURCE_STATE_UNORDERED_ACCESS));
-
- // 资源转换(中间纹理):无序访问->读状态的逻辑或
- cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(mBlurMap1.Get(),
- D3D12_RESOURCE_STATE_UNORDERED_ACCESS, D3D12_RESOURCE_STATE_GENERIC_READ));
-
- //
- // 垂直方向的模糊处理
- //
-
- cmdList->SetPipelineState(vertBlurPSO);
-
- cmdList->SetComputeRootDescriptorTable(1, mBlur1GpuSrv);
- cmdList->SetComputeRootDescriptorTable(2, mBlur0GpuUav);
-
- UINT numGroupsY = (UINT)ceilf(mHeight / 256.0f);
- cmdList->Dispatch(mWidth, numGroupsY, 1);
-
- // 👇资源转换是因为可能进行多次模糊处理 -- 所以还不如直接将资源转换放在dispatch的附近
- // 资源转换(离屏纹理):无序访问->读状态的逻辑或
- cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(mBlurMap0.Get(),
- D3D12_RESOURCE_STATE_UNORDERED_ACCESS, D3D12_RESOURCE_STATE_GENERIC_READ));
-
- // 资源转换(中间纹理):读状态的逻辑或->无序访问
- cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(mBlurMap1.Get(),
- D3D12_RESOURCE_STATE_GENERIC_READ, D3D12_RESOURCE_STATE_UNORDERED_ACCESS));
- }
- }
其中BlurFilter::CalcGaussWeights函数:计算高斯模糊的因子
- std::vector<float> BlurFilter::CalcGaussWeights(float sigma)
- {
- float twoSigma2 = 2.0f*sigma*sigma; // 2σ^2
-
- // Estimate the blur radius based on sigma since sigma controls the "width" of the bell curve. -- 用σ来估计模糊半径,因为σ控制了分布曲线
- // For example, for sigma = 3, the width of the bell curve is
- int blurRadius = (int)ceil(2.0f * sigma);
-
- assert(blurRadius <= MaxBlurRadius); // 模糊半径控制在范围内,起码在线程组的一行或列
-
- std::vector<float> weights; // 权重
- weights.resize(2 * blurRadius + 1);
-
- float weightSum = 0.0f;
-
- for(int i = -blurRadius; i <= blurRadius; ++i)
- {
- float x = (float)i;
-
- weights[i+blurRadius] = expf(-x*x / twoSigma2);
-
- weightSum += weights[i+blurRadius];
- }
-
- // Divide by the sum so all the weights add up to 1.0.
- for(int i = 0; i < weights.size(); ++i)
- {
- weights[i] /= weightSum;
- }
-
- return weights;
- }
④计算着色器程序:
首先要讲解的是按部就班实现模糊算法的低效方案,即每个线程都简单地计算出以正在处理的像素为中心的行矩阵(1D横向模糊处理,纵向模糊处理与之类似就不在此赘述)的加权平均值。这个方法的缺点是需要多次拾取同一纹素。
我们可以通过共享内存来优化上述算法,这样,每个线程就可以在共享内存中读取或存储其所需的纹素数据。从共享内存中读取数据的速度飞快。
除此之外,还有一件棘手的事,利用具有n=256个线程的线程组执行模糊运算的时候,共需要n+2R个纹素数据,这里的R就是模糊半径,如下图:

解决办法其实并不复杂,我们只需分派出能容下n+2R个元素的共享内存,并且有2R个线程要各获取两个纹素数据。唯一麻烦的地方就是在索引共享内存时要多花些心思,因为组内线程ID此时不能与共享内存中的元素一一对应了。
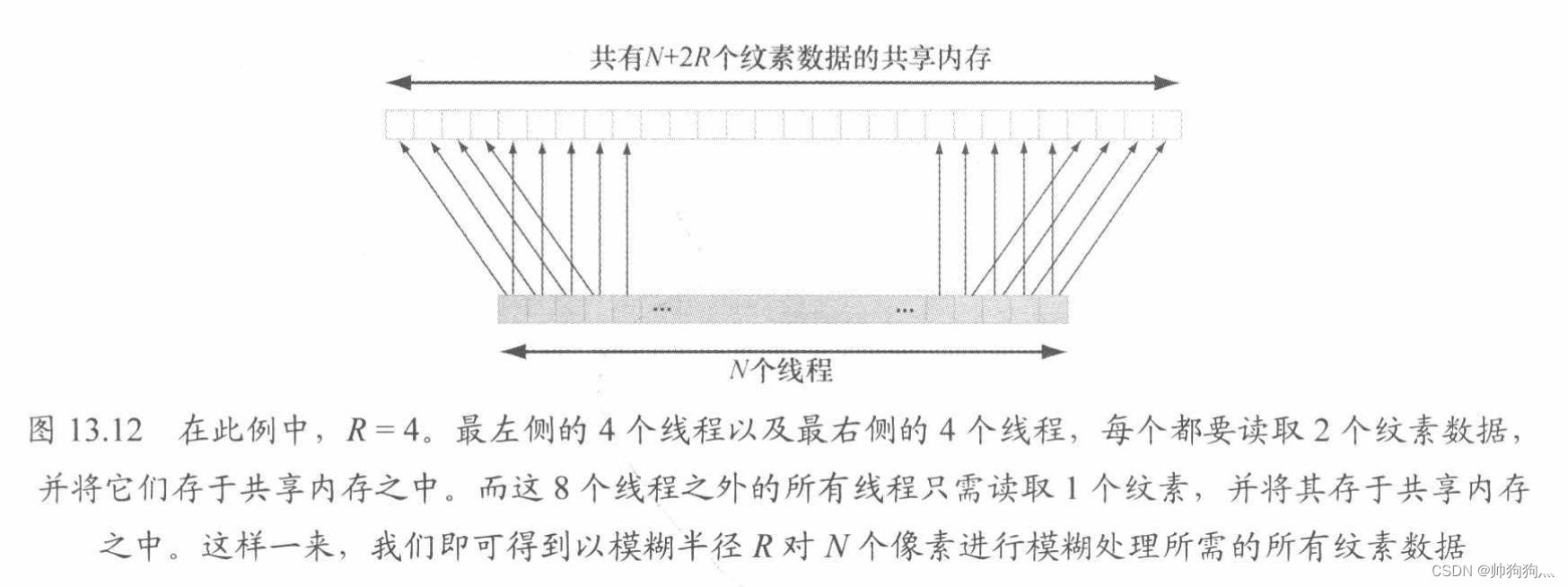
现在要讨论的是最后一种情况,即👇图中最左侧与最右侧的线程组在索引输入图像时发生越界的情形:
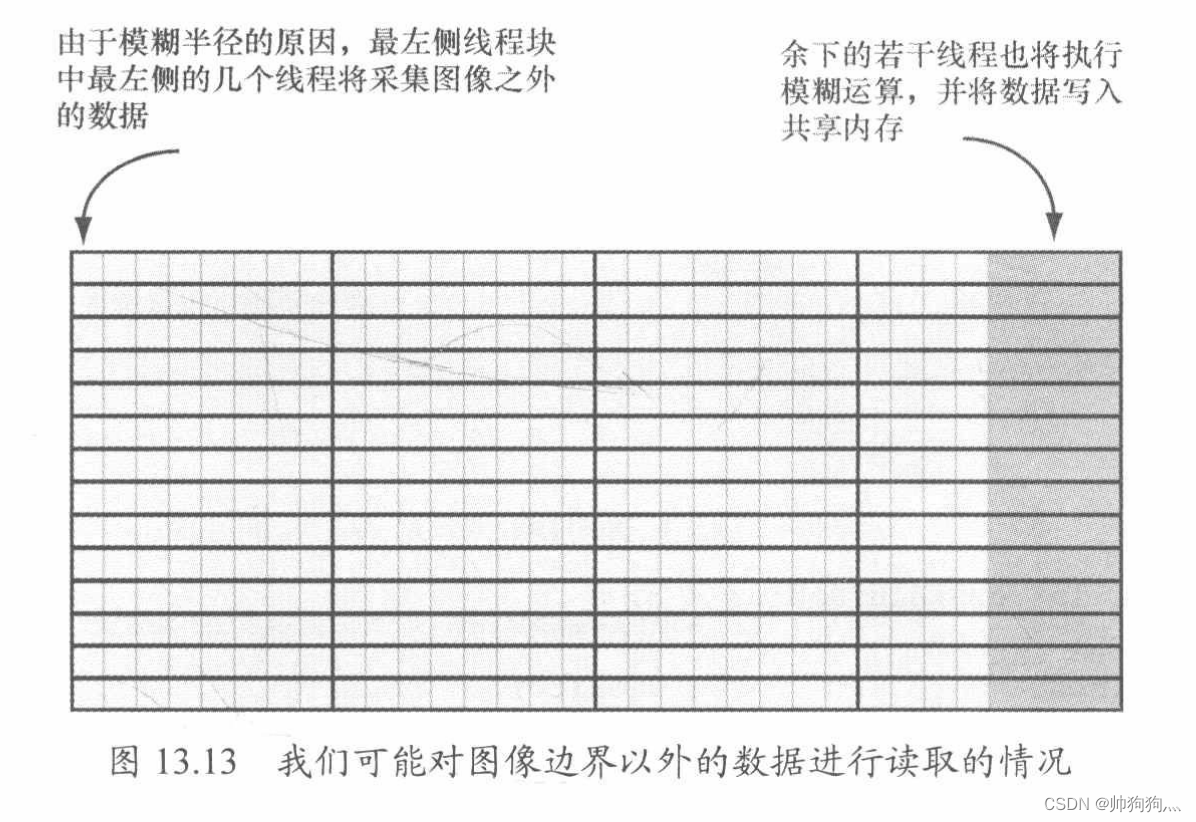
从越界的索引处读取数据并不是非法操作 -- 写操作:不执行任何操作;读操作:返回0。然而,我们在读取越界数据时并不希望得到数据0,这意味着0的颜色(黑色)会影响到边界处的模糊结果。我们此时期盼能实现类似钳位(clamp)纹理寻址模式的效果,即在读取越界的数据时,能够得到一个边界纹素相同的数据。这个方案可通过对索引进行钳制来加以实现:、
- // 针对图像左侧边界处的越界采样情况进行钳位操作
- int x = max(dispatchThreadID.x - gBlurRadius, 0);
- gCache[groupThreadID.x] = gInput[int2(x, dispatchThreadID.y)];
-
- // 针对图像右侧边界处的越界采样情况进行钳位操作
- int x = min(dispatchThreadID.x + gBlurRadius, gInput.Length.x-1);
- gCache[groupThreadID.x+2*gBlurRadius] = gInput[int2(x, dispatchThreadID.y)];
-
- // 对图像边界处存在的越界采样情况进行钳位操作
- gCache[groupThreadID.x+gBlurRadius] = gInput[min(dispatchThreadID.xy, gInput.Length.xy-1)];
完整的着色器代码如下:
- // 计算模糊半径最多为5个像素的可分离高斯模糊
- cbuffer cbSettings : register(b0)
- {
- // 我们不能把根常量映射到位于常量缓冲区中的数组元素因此要将每一个元素一一列出
- int gBlurRadius;
-
- // 最多支持11个模糊权值 2*5+1
- float w0;
- float w1;
- float w2;
- float w3;
- float w4;
- float w5;
- float w6;
- float w7;
- float w8;
- float w9;
- float w10;
- };
-
- static const int gMaxBlurRadius = 5;
-
-
- Texture2D gInput : register(t0);
- RWTexture2D<float4> gOutput : register(u0);
-
- #define N 256
- #define CacheSize (N + 2*gMaxBlurRadius)
- groupshared float4 gCache[CacheSize];
-
- [numthreads(N, 1, 1)]
- void HorzBlurCS(int3 groupThreadID : SV_GroupThreadID,
- int3 dispatchThreadID : SV_DispatchThreadID)
- {
- // 放在数组中便于索引
- float weights[11] = { w0, w1, w2, w3, w4, w5, w6, w7, w8, w9, w10 };
-
- //
- // 通过填写本地线程存储区来减少带宽的负载
- // 若要对N个像素进行模糊处理,根据模糊半径,我们需要加载N+2*BlurRadius个像素
- //
-
- // 此线程组运行着N个线程
- // 为了获得额外的2*BlurRadius个像素,就需要有2*BlurRadius个线程都多采集一个像素数据
- if(groupThreadID.x < gBlurRadius)
- {
- int x = max(dispatchThreadID.x - gBlurRadius, 0);
- gCache[groupThreadID.x] = gInput[int2(x, dispatchThreadID.y)];
- }
- if(groupThreadID.x >= N-gBlurRadius)
- {
- int x = min(dispatchThreadID.x + gBlurRadius, gInput.Length.x-1);
- gCache[groupThreadID.x+2*gBlurRadius] = gInput[int2(x, dispatchThreadID.y)];
- }
-
- gCache[groupThreadID.x+gBlurRadius] = gInput[min(dispatchThreadID.xy, gInput.Length.xy-1)];
-
- // 同步命令:等待所有线程完成任务
- GroupMemoryBarrierWithGroupSync();
-
- //
- // 现在对每个像素进行模糊处理
- //
-
- float4 blurColor = float4(0, 0, 0, 0);
-
- for(int i = -gBlurRadius; i <= gBlurRadius; ++i)
- {
- int k = groupThreadID.x + gBlurRadius + i;
-
- blurColor += weights[i+gBlurRadius]*gCache[k];
- }
-
- gOutput[dispatchThreadID.xy] = blurColor;
- }
-
- [numthreads(1, N, 1)]
- void VertBlurCS(int3 groupThreadID : SV_GroupThreadID,
- int3 dispatchThreadID : SV_DispatchThreadID)
- {
- float weights[11] = { w0, w1, w2, w3, w4, w5, w6, w7, w8, w9, w10 };
-
- if(groupThreadID.y < gBlurRadius)
- {
- int y = max(dispatchThreadID.y - gBlurRadius, 0);
- gCache[groupThreadID.y] = gInput[int2(dispatchThreadID.x, y)];
- }
- if(groupThreadID.y >= N-gBlurRadius)
- {
- int y = min(dispatchThreadID.y + gBlurRadius, gInput.Length.y-1);
- gCache[groupThreadID.y+2*gBlurRadius] = gInput[int2(dispatchThreadID.x, y)];
- }
-
- gCache[groupThreadID.y+gBlurRadius] = gInput[min(dispatchThreadID.xy, gInput.Length.xy-1)];
-
-
- GroupMemoryBarrierWithGroupSync();
-
- float4 blurColor = float4(0, 0, 0, 0);
-
- for(int i = -gBlurRadius; i <= gBlurRadius; ++i)
- {
- int k = groupThreadID.y + gBlurRadius + i;
-
- blurColor += weights[i+gBlurRadius]*gCache[k];
- }
-
- gOutput[dispatchThreadID.xy] = blurColor;
- }
最后一行代码,gOutput[dispatchThreadID.xy] = blurColor,中xy如果越界则不执行任何操作,所以不会影响。
补充:
①模糊后的纹理怎么展示?
我们是将模糊后的纹理CopyResource到后台缓冲区,也就是之前操作的逆操作,再Present即可

3.使用消耗缓冲区和追加缓冲区完成练习题1:
DirectX11--深入理解与使用缓冲区资源 - X_Jun - 博客园 (cnblogs.com)https://www.cnblogs.com/X-Jun/p/10359345.html消耗缓冲区与追加缓冲区涉及修改的操作,所以它们只能通过UAV的方式使用。
之前缓冲区我们通过SRV的方式访问,具体做法:
- // 使用CreateDefaultBuffer创建默认缓冲区
- mInputBufferA = d3dUtil::CreateDefaultBuffer(
- md3dDevice.Get(),
- mCommandList.Get(),
- dataA.data(),
- byteSize,
- mInputUploadBufferA);
-
- // [设置根签名] ...
-
- // 根签名传入实参:
- mCommandList->SetComputeRootShaderResourceView(0, mInputBufferA->GetGPUVirtualAddress());
具体分析CreateDefaultBuffer()函数:
- Microsoft::WRL::ComPtr<ID3D12Resource> d3dUtil::CreateDefaultBuffer(
- ID3D12Device* device,
- ID3D12GraphicsCommandList* cmdList,
- const void* initData,
- UINT64 byteSize,
- Microsoft::WRL::ComPtr<ID3D12Resource>& uploadBuffer)
- {
- ComPtr<ID3D12Resource> defaultBuffer;
-
- // 创建资源(缓冲区) -- 放在默认堆 -- GPU端
- ThrowIfFailed(device->CreateCommittedResource(
- &CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT),
- D3D12_HEAP_FLAG_NONE,
- &CD3DX12_RESOURCE_DESC::Buffer(byteSize),
- D3D12_RESOURCE_STATE_COMMON, // 资源状态:COMMON -- 资源在复制前必须处于的common状态
- nullptr,
- IID_PPV_ARGS(defaultBuffer.GetAddressOf())));
-
-
- // 创建上传缓冲区 -- 位于中介位置的上传堆
- ThrowIfFailed(device->CreateCommittedResource(
- &CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_UPLOAD),
- D3D12_HEAP_FLAG_NONE,
- &CD3DX12_RESOURCE_DESC::Buffer(byteSize),
- D3D12_RESOURCE_STATE_GENERIC_READ,
- nullptr,
- IID_PPV_ARGS(uploadBuffer.GetAddressOf())));
-
-
- D3D12_SUBRESOURCE_DATA subResourceData = {};
- subResourceData.pData = initData;
- subResourceData.RowPitch = byteSize;
- subResourceData.SlicePitch = subResourceData.RowPitch;
-
-
- cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(defaultBuffer.Get(),
- D3D12_RESOURCE_STATE_COMMON, D3D12_RESOURCE_STATE_COPY_DEST));
- UpdateSubresources<1>(cmdList, defaultBuffer.Get(), uploadBuffer.Get(), 0, 0, 1, &subResourceData);
-
- cmdList->ResourceBarrier(1,
- &CD3DX12_RESOURCE_BARRIER::Transition(defaultBuffer.Get(),
- D3D12_RESOURCE_STATE_COPY_DEST,
- D3D12_RESOURCE_STATE_GENERIC_READ) // 注意:结束复制操作后,缓冲区资源状态是只可读!!!!!
- );
-
- return defaultBuffer;
- }
d3dUtil代码中可以直接用于SRV,而不能直接用于UAV的原因:结束复制操作后,缓冲区资源状态是只可读的。然而资源要用作UAV,需要保持D3D12_RESOURCE_STATE_UNORDERED_ACCESS状态。
下面两处代码验证了👆的结论:
①UAV用于结构化缓冲区,(不需要初始化数据),创建对应的缓冲区资源时:
- ThrowIfFailed(md3dDevice->CreateCommittedResource(
- &CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT),
- D3D12_HEAP_FLAG_NONE,
- &CD3DX12_RESOURCE_DESC::Buffer(resByteSize, D3D12_RESOURCE_FLAG_ALLOW_UNORDERED_ACCESS),
- D3D12_RESOURCE_STATE_UNORDERED_ACCESS, // 资源状态:UAV!
- nullptr,
- IID_PPV_ARGS(&mOutputBuffer)));
②UAV用作结构化缓冲区,(需要初始化数据),创建对应的缓冲区资源时:
- // 缓冲区
- ThrowIfFailed(md3dDevice->CreateCommittedResource(
- &CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT),
- D3D12_HEAP_FLAG_NONE,
- &texDesc, // 注意:如果使用快捷创建方法CD3DX12...,注意给FLAG
- D3D12_RESOURCE_STATE_COMMON,
- nullptr,
- IID_PPV_ARGS(&mPrevSol)));
-
- // 上传缓冲区
- ThrowIfFailed(md3dDevice->CreateCommittedResource(
- &CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_UPLOAD),
- D3D12_HEAP_FLAG_NONE,
- &CD3DX12_RESOURCE_DESC::Buffer(uploadBufferSize),
- D3D12_RESOURCE_STATE_GENERIC_READ,
- nullptr,
- IID_PPV_ARGS(mPrevUploadBuffer.GetAddressOf())));
-
- // 准备数据
- D3D12_SUBRESOURCE_DATA subResourceData = {};
- subResourceData.pData = initData.data();
- subResourceData.RowPitch = mNumCols*sizeof(float);
- subResourceData.SlicePitch = subResourceData.RowPitch * mNumRows;
-
- // 复制前的资源转换
- cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(mPrevSol.Get(),
- D3D12_RESOURCE_STATE_COMMON, D3D12_RESOURCE_STATE_COPY_DEST));
-
- // 上传数据
- UpdateSubresources(cmdList, mPrevSol.Get(), mPrevUploadBuffer.Get(), 0, 0, num2DSubresources, &subResourceData);
-
- // 结束复制操作后的资源转换 -- 唯一不同!
- cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(mPrevSol.Get(),
- D3D12_RESOURCE_STATE_COPY_DEST, D3D12_RESOURCE_STATE_UNORDERED_ACCESS));
-
ConsumeStructuredBuffer - Win32 apps | Microsoft Learn
创建UAV缓冲区,并给他从CPU端初始化数据:注意,在创建Resource资源时,如果使用快捷方法CD3DX12_RESOURCE_DESC::Buffer,一定要给flag:D3D12_RESOURCE_FLAG_ALLOW_UNORDERED_ACCESS,保证后续能正确进行资源转换:D3D12_RESOURCE_STATE_UNORDERED_ACCESS
- // Create the actual default buffer resource. -- GPU端
- ThrowIfFailed(md3dDevice->CreateCommittedResource(
- &CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT),
- D3D12_HEAP_FLAG_NONE,
- &CD3DX12_RESOURCE_DESC::Buffer(byteSize, D3D12_RESOURCE_FLAG_ALLOW_UNORDERED_ACCESS),
- D3D12_RESOURCE_STATE_COMMON,
- nullptr,
- IID_PPV_ARGS(mInputBufferA.GetAddressOf())));
-
- // an intermediate upload heap. -- 位于中介位置的上传堆
- ThrowIfFailed(md3dDevice->CreateCommittedResource(
- &CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_UPLOAD),
- D3D12_HEAP_FLAG_NONE,
- &CD3DX12_RESOURCE_DESC::Buffer(byteSize),
- D3D12_RESOURCE_STATE_GENERIC_READ,
- nullptr,
- IID_PPV_ARGS(mInputUploadBufferA.GetAddressOf())));
-
- D3D12_SUBRESOURCE_DATA subResourceData = {};
- subResourceData.pData = dataA.data();
- subResourceData.RowPitch = byteSize;
- subResourceData.SlicePitch = subResourceData.RowPitch;
-
- mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(mInputBufferA.Get(),
- D3D12_RESOURCE_STATE_COMMON, D3D12_RESOURCE_STATE_COPY_DEST));
-
- UpdateSubresources<1>(mCommandList.Get(), mInputBufferA.Get(), mInputUploadBufferA.Get(), 0, 0, 1, &subResourceData);
-
- mCommandList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition(mInputBufferA.Get(),
- D3D12_RESOURCE_STATE_COPY_DEST, D3D12_RESOURCE_STATE_UNORDERED_ACCESS));
现在纹理可以使用RWStructuredBuffer了,但是消耗结构化缓冲区和追加结构化缓冲区依然报错!

注意:绑定到此资源的UAV必须使用D3D11_BUFFER_UAV_FLAG_APPEND创建,这里的FLAG是UAV结构的成员,要使用UAV结构,就不能使用根描述符的办法,必须创建描述符堆!
但是我们使用的接口是D3D12的,不能使用D3D11的成员属性,这里兼容性有些问题,所以这个追加缓冲区貌似不能正常使用!
当我上某知名交友网站上寻求解答时,我得到了这样的answer:
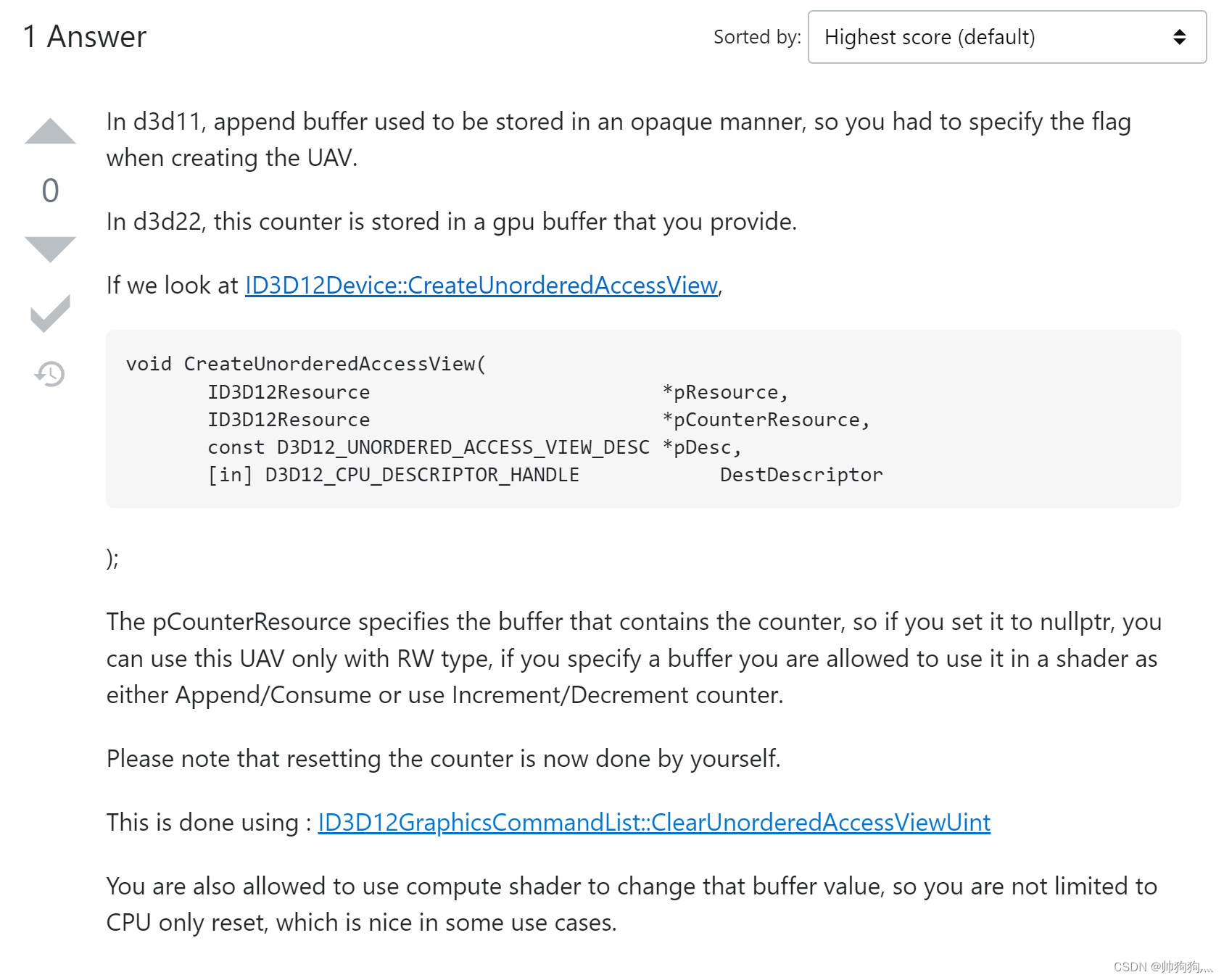
UAV Counters - Win32 apps | Microsoft Learn
游戏引擎随笔 0x16:现代图形 API 的 UAV Counter - 知乎 (zhihu.com)
也就是说需要自行指定计数器资源,它是一个缓冲区,在dispatch和draw调用过程中它的资源状态必须是D3D12_RESOURCE_STATE_UNORDERED_ACCESS)。
?????????
4.研究双边模糊(bilateral blur,也称作双边滤波器,Bilateral filter)技术,并用计算着色器来加以实现。最后,以此技术来完成另一版本的Blur模糊演示程序。
参考资料:
双边滤波 - Bilateral Filter - 知乎 (zhihu.com)https://zhuanlan.zhihu.com/p/180497579①高斯模糊:
其中:p是中心像素点位置,q是当前计算权值的像素,||p-q||代表两个像素点之间的距离
②双边模糊(滤波):Bilateral Filter
Wp是归一化因子,
我们计算的时候可以忽略 ,反正最后除以对应的归一化因子即可
之前高斯模糊因子放在cpu程序端实现,并通过根常量传递给CS。但是要实现双边模糊,需要运用纹理颜色之差作为因变量,所以需要在shader代码中实现。
5.波浪程序通过GPU计算波浪高度,保存在纹理中,然后直接将纹理视为位移贴图
6.索贝尔算子(Sobel Operator)用于图像的边缘检测。它会针对每一个像素估算其梯度(gradient)的大小。有着较大梯度的像素及表明它与周围像素的颜色差异极大,因此该像素一定位于图像的边缘。索贝尔算子返回的是一个范围在[0,1]内表示边沿陡峭程度的灰度值:0表示平坦,1表示非常陡峭。
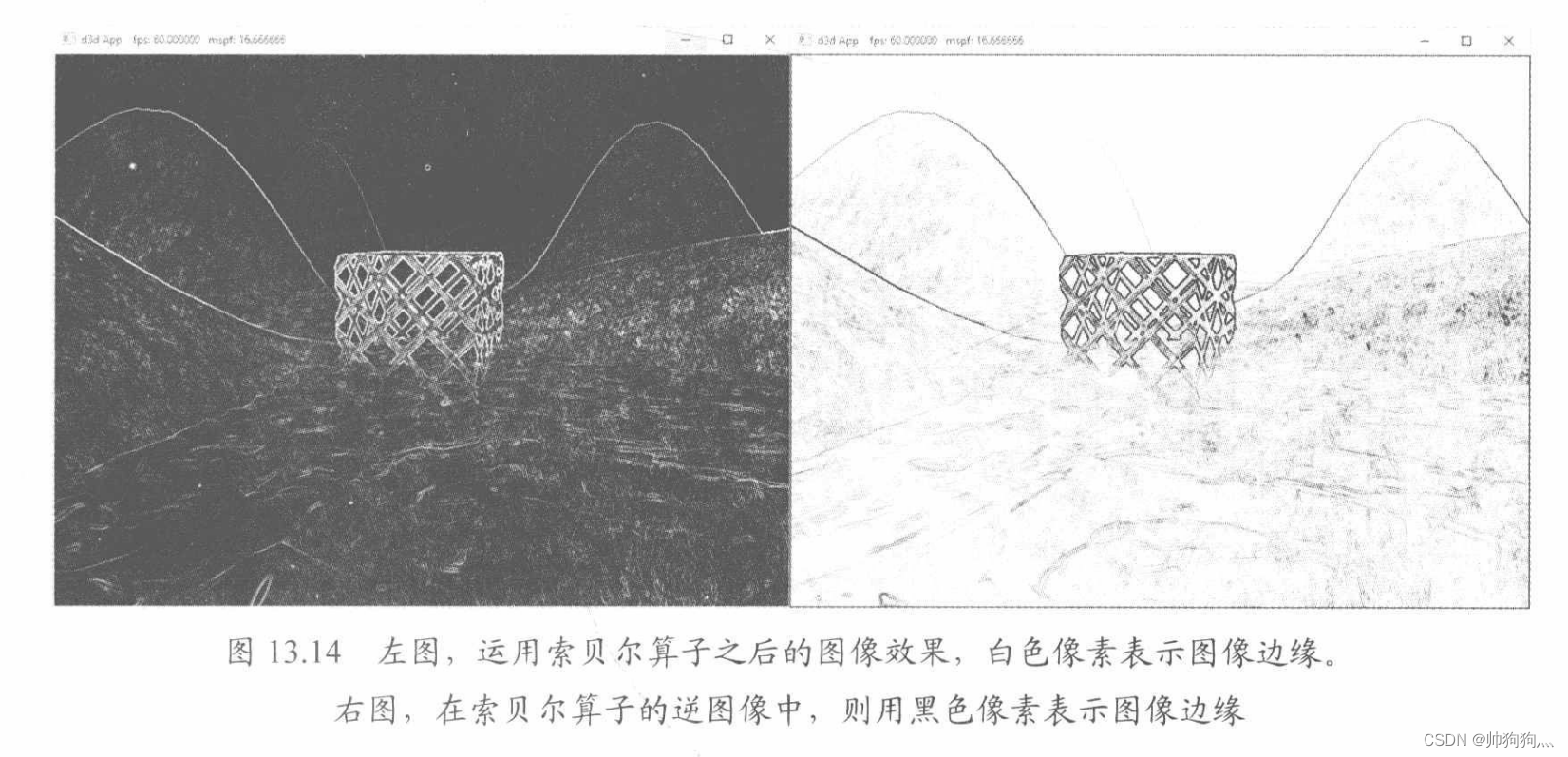
如果将原始图像与其经过索贝尔算子生成的逆图像两者间的对应颜色值相乘,我们就可以获得类似卡通画或动漫书中那样,其边缘就像用黑色的线勾描后的图像效果。

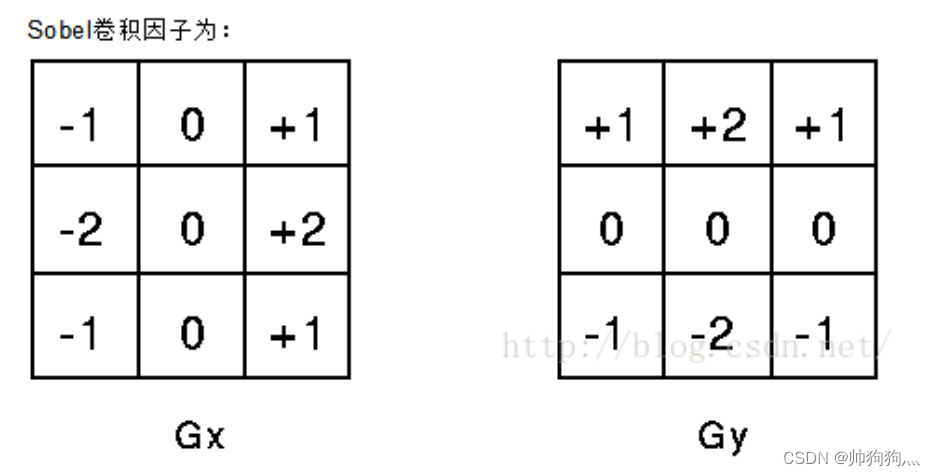
索贝尔卷积因子如👇,我们需要提取以当前像素点为中心的3×3矩阵内的所有像素点:
- float CalcLuminance(float3 color)
- {
- return dot(color, float3(0.299f, 0.587f, 0.114f));
- }
-
- // 针对每个颜色通道,运用索贝尔公式估算出关于x的偏导数近似值
- float4 Gx = -1.f*c[0][0] - 2.f*c[1][0] - 1.f*c[2][0] + 1.f*c[0][2] + 2.f*c[0][1] + 1.f*c[0][2];
-
- // 针对每个颜色通道,运用索贝尔公式估算出关于y的偏导数近似值
- float4 Gy = -1.0f*c[2][0] - 2.0f*c[2][1] - 1.0f*c[2][1] + 1.0f*c[0][0] + 2.0f*c[0][1] + 1.0f*c[0][2];
-
- // 梯度即为(Gx,Gy)
- float4 mag = sqrt(Gx*Gx+Gy*Gy);
-
- // 将梯度转换为颜色:
- mag = 1.f - saturate(CalcLuminance(mgb.rgb));
-

武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020



















.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)

