















































软件

产品


讲解视频:可以在bilibili搜索“MATLAB教程新手入门篇——数学建模清风主讲”。

首先我们介绍字符的概念。字符是文本的最基本单元,在英文语境中,它包括字母、数字、标点符号、空格、换行符等,它们是构成单词、句子和段落的基础;在中文语境中,每个汉字同样也被视为一个字符。实际上,我们在生活中读到的文本都是由各种字符组成的。
存储在计算机中的所有数据都是以二进制的形式表示的,由字符组成的文本数据也是一样。将字符转换成相应的二进制数,这个过程称为对字符编码。为了使不同的计算机能够准确无误地交换文本数据,它们必须使用相同的编码规则。为此,我们这一节将介绍两种最广为使用的编码标准:ASCII和Unicode编码。
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是最早的编码规则之一,它基于拉丁字母,并且主要设计来显示现代英语。ASCII编码总共定义了128个字符,这128个字符的十进制编号为0到127。
下面是ASCII编码的表格,完整的表格可以查阅本章的附录1:ASCII编码。
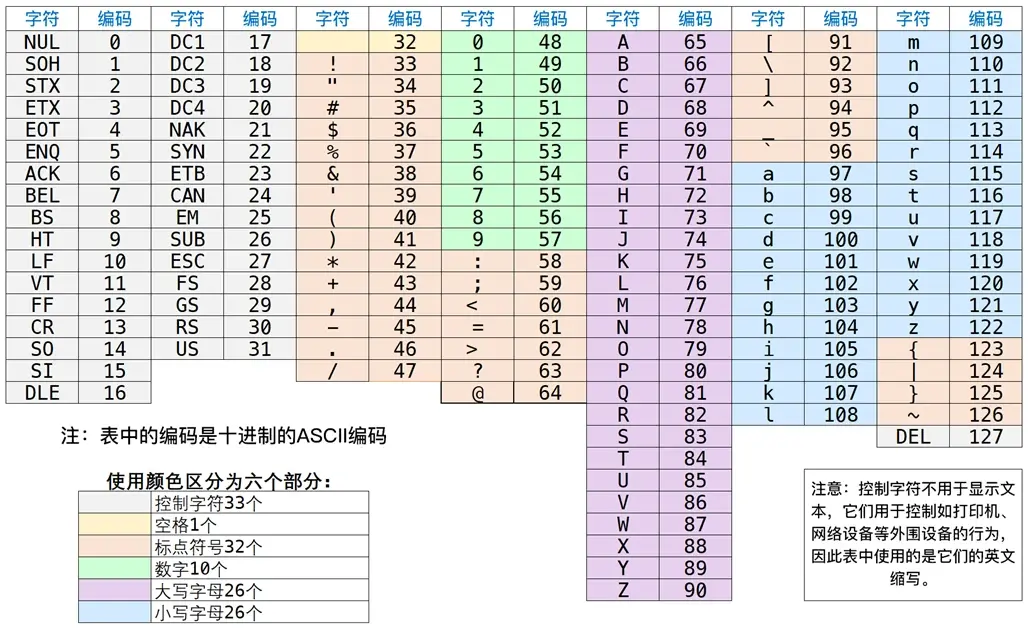
在ASCII编码表中,常用字符的编码(十进制)如下所示:
此外,在ASCII编码中,编码10表示换行符,这个符号用于将文本分隔为多行;编码32表示空格,大家可以使用键盘上的空格键打出来。
随着计算机技术的全球化,仅用ASCII编码已无法满足全球用户的需求,因为它只能表示英语文字。因此,各个国家或地区开始制定自己的编码标准。例如我国1980年推出了第一代汉字编码GB2312(GB:国标),并于1995年进一步推出了扩展的汉字编码GBK(K:扩)。
但是,当不同的编码不统一时(即同一个编码表示的字符不相同时),计算机中就可能出现乱码问题。因此Unicode编码应运而生,它为每种语言中的每个字符设定了统一且唯一的编码,以满足跨语言、跨平台的要求,Unicode编码的中文翻译通常为统一码或万国码。另外,为了兼容ASCII编码,Unicode 编码的前128 个字符和ASCII编码一致。
尽管Unicode编码为各种字符提供了一个唯一的编码,但它并没有指定这些编码应该如何存储在计算机中。目前最常用的存储格式有三种:UTF-8、UTF-16 和 UTF-32。UTF是 Unicode Transformation Format 的缩写,直译就是Unicode的转换格式,后面的8、16和32分别代表存储每种字符编码所需的最少的比特位数。关于这一块的知识点比较复杂,感兴趣的同学可以自行查阅相关资料。大家只需要知道:MATLAB保存字符选用的是UTF-16格式。

更多文章可点击下方合辑:

武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















