















































软件

产品


以一个例子总结一下批量读取文件的两个不同的思路,如下图所示
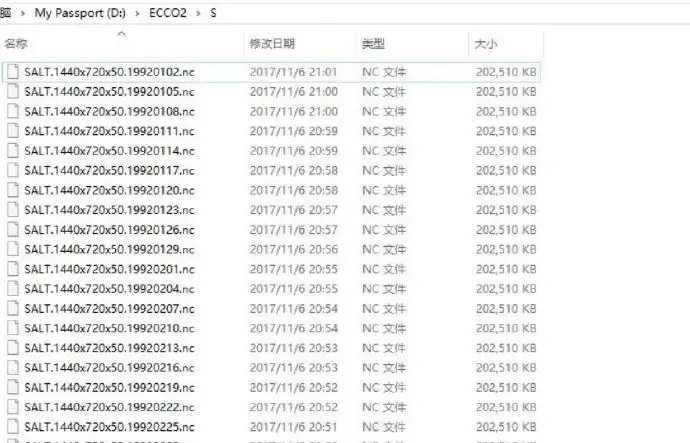
第一个方法,是根据文件的命名特征,可以发现文件前面的命名都是SALT.1440x720x50.,只有后面的时间在变,第一个文件的时间是19920102,第二个是19920105,后面都是加3天。这就涉及都是matlab时间处理函数了。
以下程序演示如何批量读取图中的19个nc文件(matlab时间处理函数参考了https://www.cnblogs.com/emanlee/archive/2011/12/19/2293234.html)
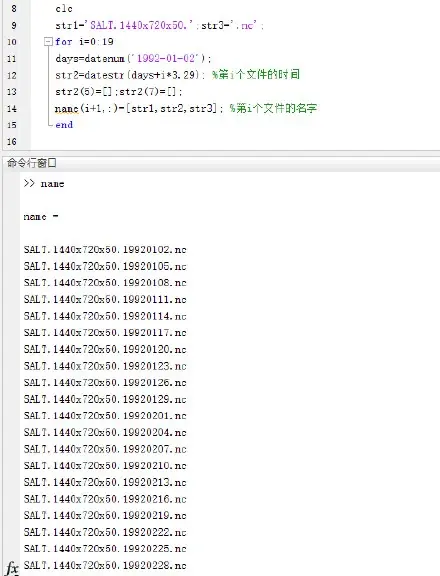
clc str1='SALT.1440x720x50.';str3='.nc'; for i=0:19 days=datenum('1992-01-02'); str2=datestr(days+i*3,29); %第i个文件的时间 str2(5)=[];str2(7)=[]; name(i+1,:)=[str1,str2,str3]; %第i个文件的名字 end
name数组如下:
第二个方法更加简单粗暴,也更加普适,直接通过目录操作获取该目录下文件的名字
(参考http://blog.sina.com.cn/s/blog_836db8100102vsij.html)
file_path='My Passport\ECCO2\S\'; img_path_list=dir(strcat(file_path,'*.nc'))
img_path_list是一个结构体,存储了该目录下所有nc文件的信息,包括name,date,bytes等等
img_path_list(1).name 就是 'SALT.1440x720x50.19920102.nc'
img_path_list(2).name就是 'SALT.1440x720x50.19920105.nc'
其余类推
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















