















































软件

产品


用一个例程复现一下,首先新建了五个excel文件放在一个文件夹中。

第一步是导入该文件夹下的所有文件信息

可以看到信息包括文件名、路径、修改时间、大小等,这些里面需要关注的即文件名。
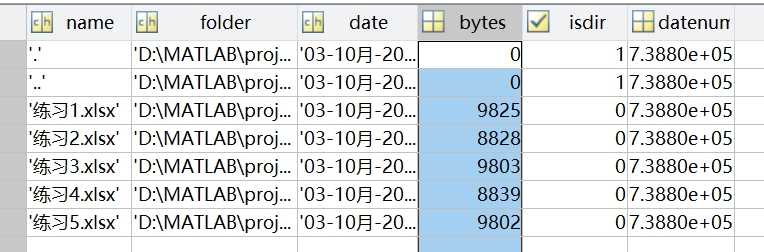
在进行数据处理之前要先进行预处理,获取的文件信息是struct结构,先将其转化为元胞数组,然后取数组第一列,也就是含有文件夹名字的那一列,并去除前两个变量后保存为新数组。

预处理后就成功得到了由文件名构成的字符串数组c。

最后进行数据处理,数据处理可分为两种,一种是对原始表格进行修改,覆盖原表,另一种是不进行修改,只是根据判定进行简单归类。如果是前一种,就要进行写文件操作,这也是平常使用最多的操作,如果是后一种,就要用到文件操作,文件复制与文件剪切,该操作也比较简单,使用copyfile与movefile指令,然后根据预处理得到的文件名数组进行循环遍历就行了。
该例程中的数据处理,是对文件表1中的第二列与第三列进行数值比较,差值大于10的个数大于10则判定为异常,应用时根据实际需要编写即可。


运行后就完成了所有文件的自动处理,正常文件与异常文件被自动分到了两个文件夹中。


免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















