





































































引用:Poria S, Hazarika D, Majumder N, et al. Beneath the tip of the iceberg: Current challenges and new directions in sentiment analysis research[J]. IEEE Transactions on Affective Computing, 2020.
发表:IEEE Transactions on Affective Computing, 2020. CCF-B
由于本文是情感分析综述论文,细分情感分析对应测领域,故将文章的主要内容进行简要介绍。
What
Sentiment Analysis,情感分析,也称为意见挖掘,是一个旨在理解非结构化内容的潜在情感的研究领域。自早期开始以来(Pang et al., 2002; Turney, 2002),情感分析广泛应用于个人、企业和政府,了解人们对产品、政治议程或营销活动的看法。舆论也影响与金融预测。此外,教育和医疗保健部门利用情绪分析对学生和患者的行为分析。人们研究情感分析问题只当做一个文本/内容分类任务——分为两种或三类情绪:正面、负面或中性,现已经逐渐趋向饱和。在基础数据集上(如 IMDB or SST-2)的研究效果如图 1 。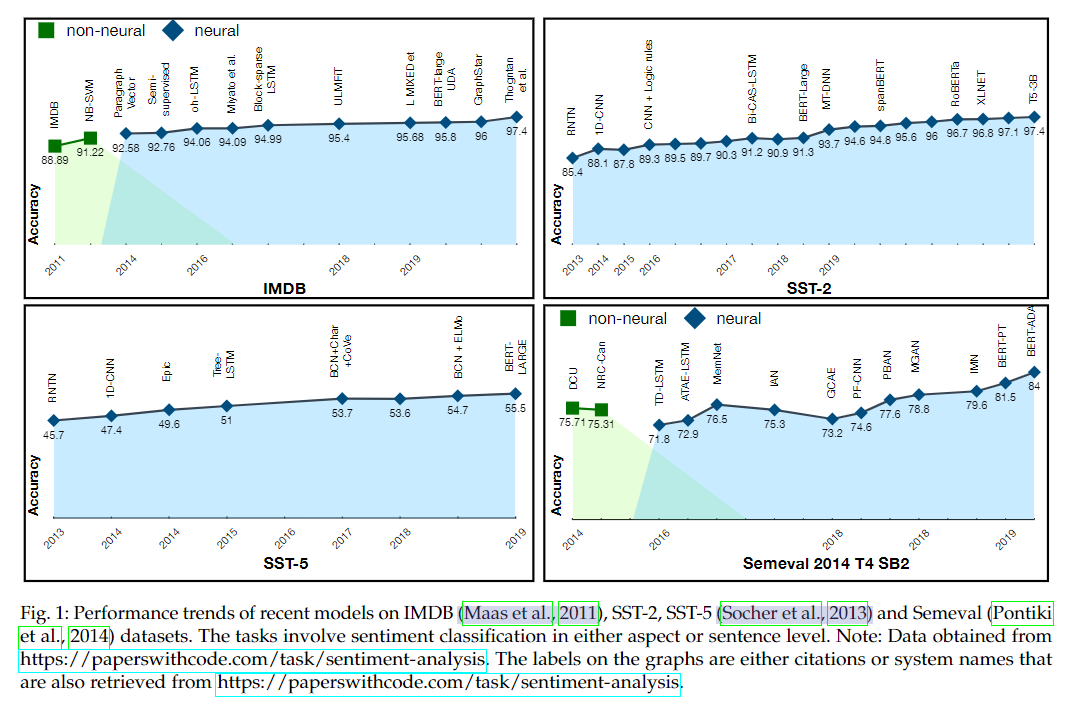
同时,图 1 还显示了每个基础数据集使用的模型方法。
Example
"John dislikes the camera of iPhone 7", according to the technical definition (Liu, 2012) of sentiment analysis, John plays the role of the opinion holder exposing his negative sentimenttowards the aspect – camera of the entity – iPhone 7.
How
2 NOSTALGIC PAST: DEVELOPMENTS ANDACHIEVEMENTS IN SENTIMENT ANALYSIS
sentiment analysis 的过去和现在,如图 2 。
Granularities 粒度层级
主要分为三类:
1 Document-level: 给出文档的整体正负向观点。
主要方法:unigrams (bag of words) and trained simple classifiers, such as Naive Bayes classifiers and SVMs.
2 Sentence-level: 单个句子。
在许多情况下上述的粒度并未指示情感的目标。他们隐含地假设文本跨度(文档或句子)传达了对实体的单一情绪,针对更精细的审查级别,引出了更细粒度的分析。
3 Aspect-level: 即方面级别的情感分析,其中每个实体识别情绪(Hu & Liu, 2004b)(along with its aspects)。方面级分析可以更好地理解情感分布。
除了这三个粒度级别之外,还对短语级情感分析(phrase-level sentiment analysis)进行了大量的研究,这些情感分析侧重于句子中的短语(Wilson et al., 2005b)。
Trends in Sentiment Analysis Applications 趋势
1 Rule-Based Sentiment Analysis:
利用情感词并利用它们的组合来分析极性的短语单元。
例如,词袋模型的局限导致了对价转移器(valence shifters)的研究的出现,该研究结合了基于上下文使用的术语的价和极性的变化(Polanyi & Zanen, 2006; Moilanen & Pulman, 2007)。然而,只有价移器不足以检测情感——它还需要了解句法单元的情感流,产生了启发式和规则学习(Choi & Cardie, 2008)、混合系统(Rentoumi et al., 2010)、句法依赖等。 (heuristics and rules (Choi & Cardie, 2008), hybrid systems (Rentoumi et al., 2010), syntactic dependencies (Nakagawa et al., 2010; Hutto & Gilbert, 2014))2 Sentiment Lexicons:
是基于规则的情感分析方法的核心。
词典是包含其组成词、短语或同义词集的情感注释的词典。如SentiWordNet (Esuli & Sebastiani, 2006) 、SO-CAL (Taboada et al., 2011) 、SCL-OPP等。这些词典不仅存储单词极性关联,还包括反映复杂情感组合的短语或规则,例如否定、增强词。
词典主要是使用三种广泛的方法、手动、自动和半监督创建的。但没有一个词典可以处理从语义组合性中观察到的所有细微差别(Tolleo-Ronen 等人,2018;Kiritchenko 和 Mohammad,2016d),或解释上下文极性。3 Machine Learning-Based Sentiment Analysis:
如 Naive Bayes Classifiers (Tan et al., 2009), nearest neighbour (Moghaddam & Ester, 2010), bag-of-words (including weighted variants) (Martineau & Finin, 2009), lexicons (Gavilanes et al., 2016) to syntactic features such as parts of speech (Mejova & Srinivasan, 2011)等方法。-
4 Deep Learning Era: 如 RNTN、CNNs、RNNs等。
单词表示依赖于它用于的任务(Labutov & Lipson,2013)。然而,大多数基于情感分析的模型都使用静态的通用词表示(general-purpose word representations)。如图 3 显示的关键里程碑节点。
深度网络的注释数据通常是有限的。因此,需要通过句法信息提供归纳偏差,或者以词典的形式提供外部知识作为附加输入(Tay 等人,2018b)。比如BERT、XLNet、RoBERTa。
5 Sentiment-Aware Word Embeddings: 深度学习架构的关键构建块之一是其词嵌入。
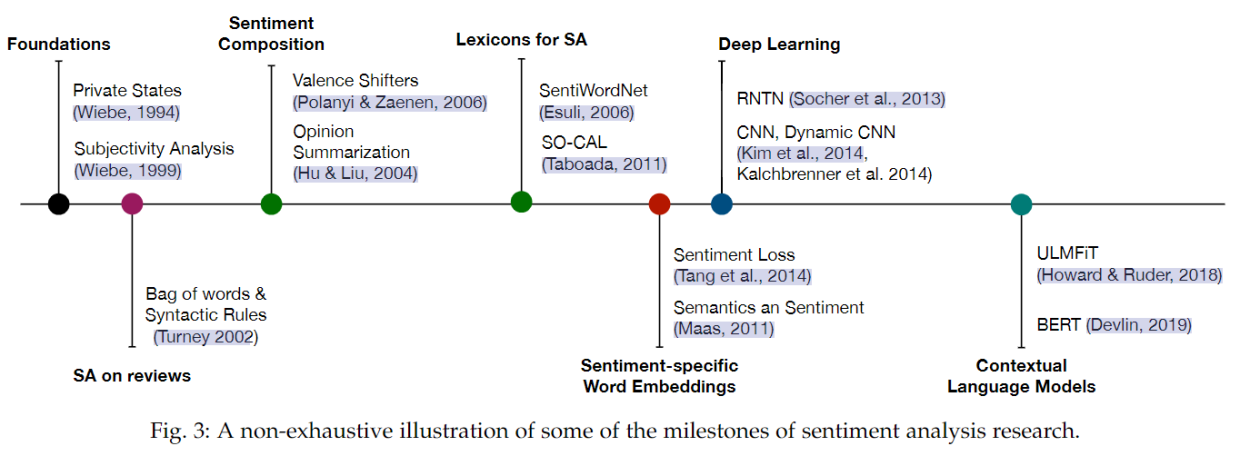 Figure 3
Figure 3
3 OPTIMISTIC FUTURE: UPCOMING TRENDS IN SENTIMENT ANALYSIS
Sentiment analysis 涉及的子领域如下图,后文将根据本图进行展开论述。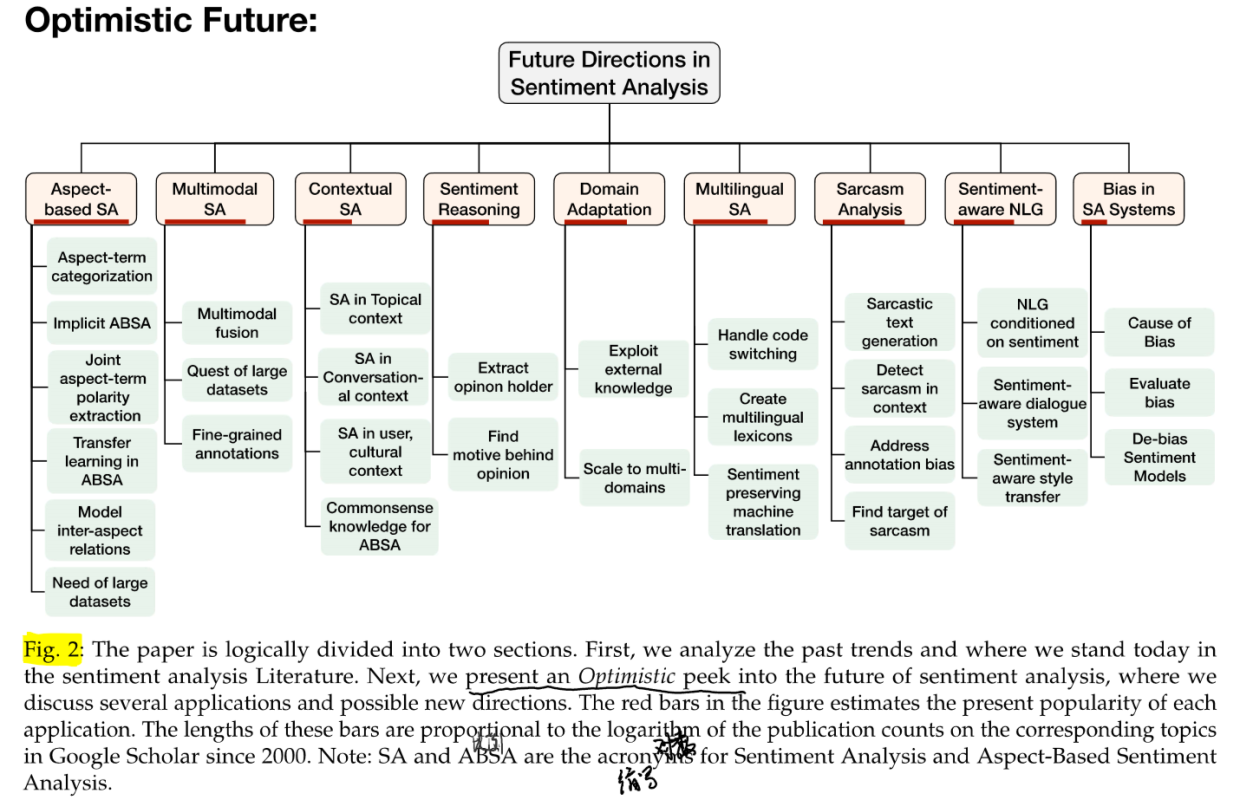
案例
图 4 展示了一个用户与闲聊式聊天机器人聊天。在对话中,为了产生适当的响应,机器人需要了解用户的意见。这涉及多个子任务,包括
- 提取实体航空公司的服务、座位等方面,
- 方面级别的情感分析以及知道,
-
谁持有意见以及为什么(情感推理)。
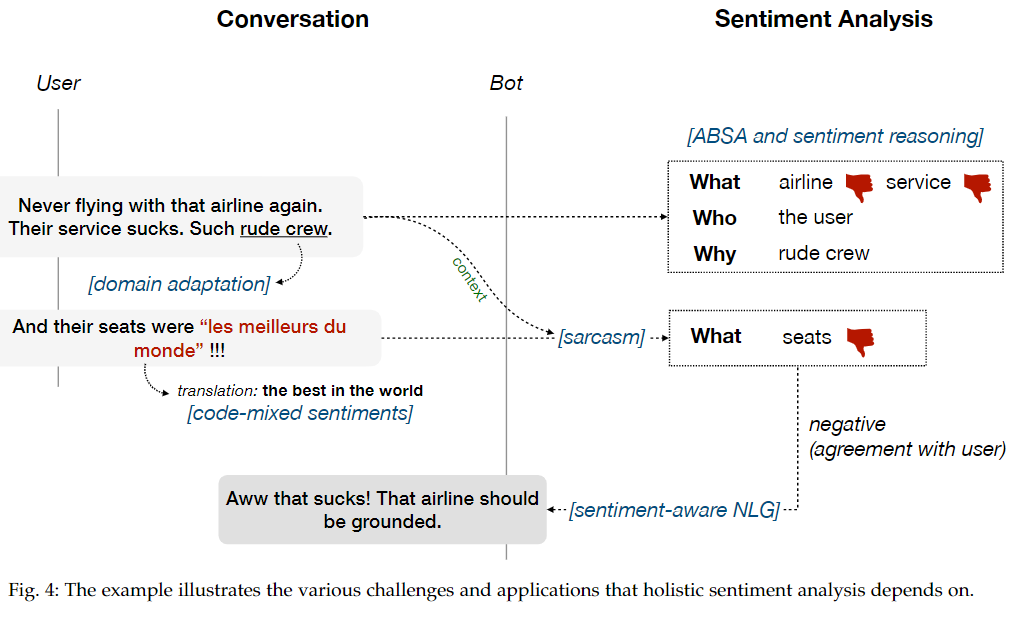 Figure 4
Figure 4
3.1 Aspect-Based Sentiment Analysis 基于方面的情感分析
在基于方面的情感分析的上下文中,方面是用于主题、实体或其属性/特征的通用术语( topics, entities, or their attributes/features)。它们也被称为意见目标。
- 例如,“This actor is the only failure in an otherwise brilliant cast.”,意见附加到两个特定的实体,演员(负面意见)和演员(正面意见)。也有没有可以分配给完整句子的整体意见。
基于方面的情感分析 (ABSA) 采用这种细粒度的视图,旨在识别每个实体(或其方面)的情绪(Liu,2015;Liu & Zhang,2012)。该问题涉及两个主要子任务:
- 1)Aspectextraction 方面提取,它识别给定句子或段落中提到的方面(在上面的例子中演员和演员)。
- 2)Aspect-level Sentiment Analysis (ALSA) 方面级情感分析(ALSA),它确定与相应方面/意见目标(演员↦负面和演员↦正面)相关的情感方向(Hu & Liu, 2004a)。
3.1.1 Aspect-Term Auto-Categorization
方面术语提取是方面级情感分析的第一步。我们在图 5 中说明了这种分类。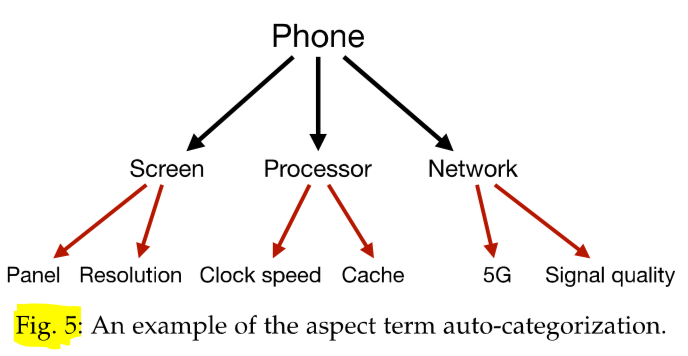
基于监督和无监督的主题分类和词典驱动能成功地克服了可扩展性问题。我们相信基于实体链接的方法,加上 Probase (Wu et al., 2012) 等语义图,应该能够在克服可扩展性问题的同时合理地执行。例如,"With this phone, I always have a hard time getting signal indoors." 包含一个方面术语信号,可以传递给实体链接器——在图 5 所示的树上—— with the surrounding words as context to obtain aspect category phone:signal-quality
3.1.2 Implicit Aspect-Level Sentiment Analysis
不同方面的情绪可以隐式表达。
- 例如,在句子中,"Oh no! Crazy Republicans voted against this bill",演讲者明确表达了她/他对共和党的负面情绪。
3.1.3 Aspect Term-Polarity Co-Extraction
方法有:分层神经网络(Lakkaraju 等人,2014 年)、多任务 CNN(Wu 等人,2016 年)和基于 CRF、联合学习、迁移学习等。
3.1.4 Exploiting Inter-Aspect Relations for Aspect-Level Sentiment Analysis 利用方面级情感分析的方面间关系
主要重点是对意见目标与其对应的自以为为是的之间的依赖关系进行建模。
- 例如,在句子“my favs here is the tacos pastor and tostada de tinga”中,方面“tacos pastor”和“tostada de tinga”使用连词“and”连接,两者都依赖于带有情感的词“favvs”。
3.2 Multimodal Sentiment Analysis 多模态情感分析
动机:形如YouTube, Facebook, Vimeo等企业倾向于通过分析这些视频中的用户情绪来对其产品做出商业决策。

下面简述有助于未来研究的三个关键方向:
- 3.2.1 Complex Fusion Methods vs. Simple Concatenation 复杂融合方法与简单连接
- 3.2.2 Lack of Large Datasets 缺乏大型数据集
- 3.2.3 Fine-Grained Annotation 细粒度注释
3.3 Contextual Sentiment Analysis
3.3.1 Influence of Topics
情感词的使用因一个主题而异。当与其他单词或短语共轭时,表面上听起来中性的词可以带有情绪。
- 例如,大房子里的大这个词在有人打算购买大房子供休闲时可以带有积极的情绪。然而,同一个词在上下文中使用时可能会引起负面情绪——大房子很难清理。
某些词的情绪可能含糊不清,并且仅在上下文中看到时指定。 - 例如,the word massive in the context of massive earthquake and massive villa.
这项研究问题也与词义消歧有关。例如:
- a. The Federal Government carried the province for many years.
- b. The troops carried the town after a brief fight.
在第一句中,carry 的意义具有正极性。然而,在第二个句子中,同一个词具有负面含义。
3.3.2 Sentiment Analysis in Monologues and Conversational Context
上下文的概念可能因问题而异。
- 例如,在计算单词表示时,周围的单词携带上下文信息。同样,为了对文档中的句子进行分类,其他相邻句子被视为其上下文。
- 例如,“Oh no. The bill has been passed”。由于孤立句子中不存在明确的情感标记——“The bill has been passed”,它会听起来像中性句子。因此,“bill”背后的情绪不是由任何特定单词表达的。然而,考虑到上下文中的句子——“Oh no”表现出负面情绪,可以推断“bill”表达的意见是负面的。
方法有:logic rules, finite-state transducers, belief, and information propagation mechanisms, using a gate or switch to learn and further infer when to count on contextual information.
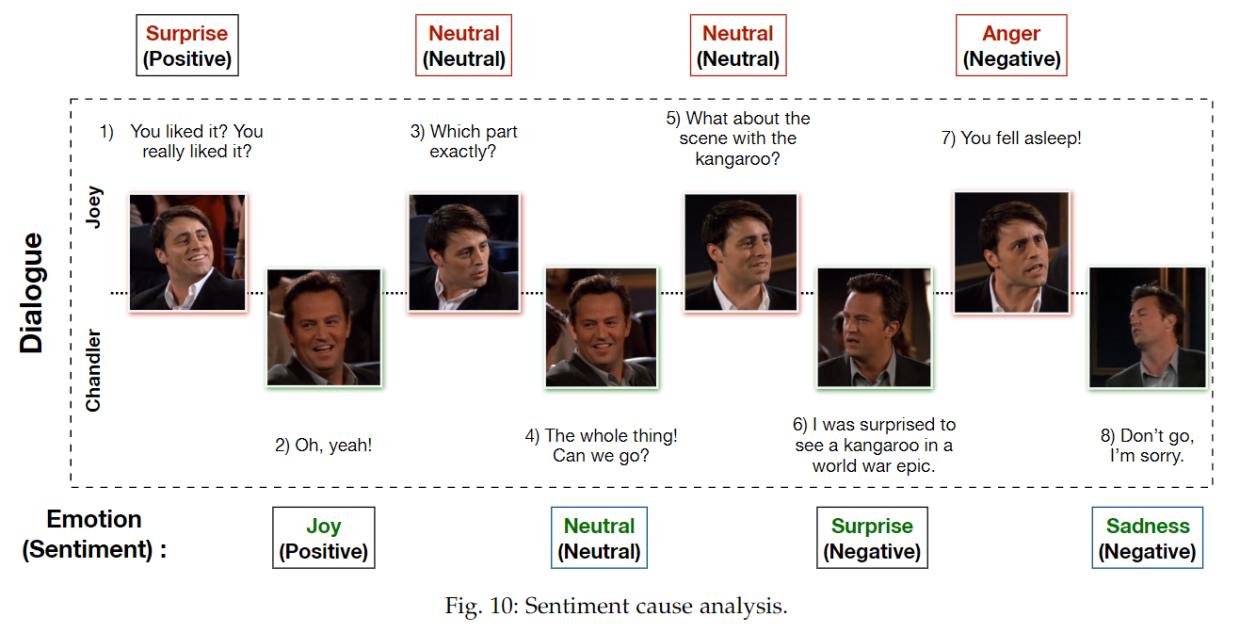
对话中的情绪与情绪动态密切相关,包括两个重要方面(Morris & Keltner,2000):
- Self dependency,自我依赖,也称为情感惯性,处理说话者在对话中对自己的影响方面(Kuppens 等人,2010)。
-
inter-personal dependencies 人际依赖与对应物诱导说话者的情感感知影响有关。相反,在对话过程中,说话者也倾向于反映他们的同行来构建融洽关系(Navarretta et al., 2016)。这种现象如图7所示。
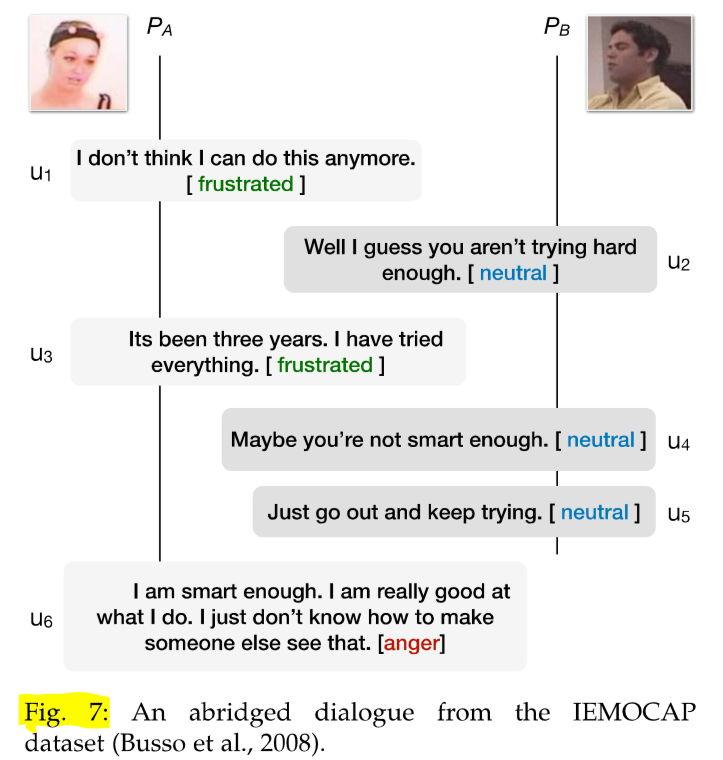 Figure 7
Figure 7 - Pa is frustrated over her long term unemployment and seeks encouragement (u1, u3). Pb, however, is pre-occupied and replies sarcastically (u4). This enrages Pa to appropriate an angry response (u6). In this dialogue, self-dependencies are evident in Pb, who does not deviate from his nonchalant behavior. Pa, however, gets sentimentally influenced by Pb.
因此,分析对话的主题以及参数结构、对话者个性、意图、对话中的观点、彼此的态度等各种因素对于可能导致丰富上下文理解的真实自我和个人间依赖建模至关重要(Hazarika 等人,2018d)。
上下文的有用性在对短话语进行分类方面更为普遍,例如 yeah、okay、no,可以根据对话的上下文和话语来表达不同的情感。图 8 中的示例解释了这种现象,如何推断 “Yeah”表达的情绪。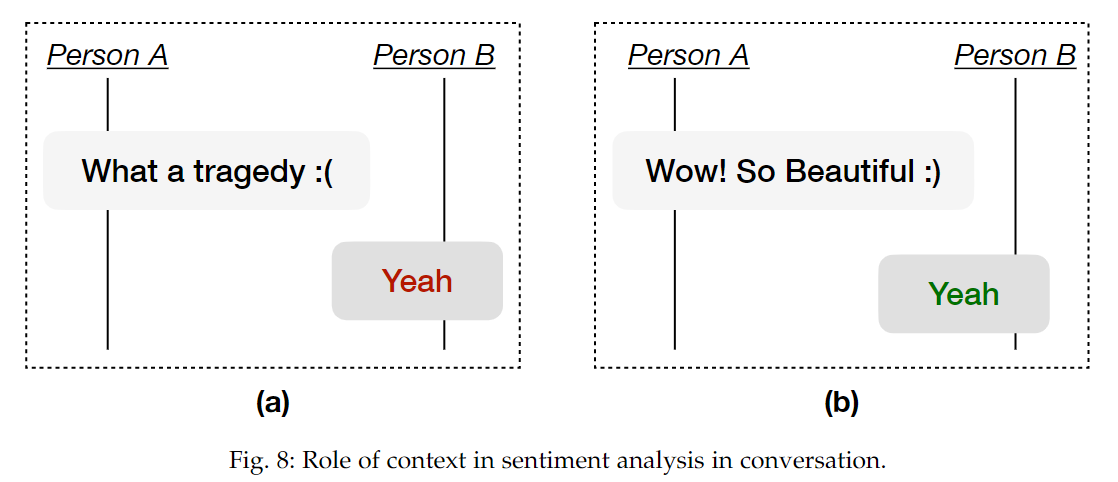
3.3.3 User, Cultural, and Situational Context
上下文情感还取决于用户、文化和情境背景。
- 例如,some individuals are more sarcastic than others. For such cases, the usage of certain words would vary depending on if they are being sarcastic. Let's consider this example, Pa ∶ The order has been cancelled. Pb ∶ This is great!. If Pb is a sarcastic person, then his response would express negative emotion to the order being canceled through the word great. On the other hand, Pb's response,great, could be taken literally if the canceled order is beneficial to Pb (perhaps Pb cannot afford the product he ordered).
由于对话中经常缺少必要的背景信息,因此基于先前话语的说话人分析通常会产生改进的结果。
同一个词的潜在情感可能因一个人而异。
- E.g., the word okay can bear different sentiment intensity and polarity depending on the speaker's character.
3.3.4 Role of Commonsense Knowledge in Sentiment Analysis
常识知识的提炼已经成为现代 NLP 研究的新趋势,如图 9 。
-
The present scenario informs that David is a good cook and will be making pasta for some people. Based on this information, commonsense can be employed to infer related events such as, dough for the pasta would be available, people would eat food (pasta), the pasta is expected to be good (David is good cook), etc.
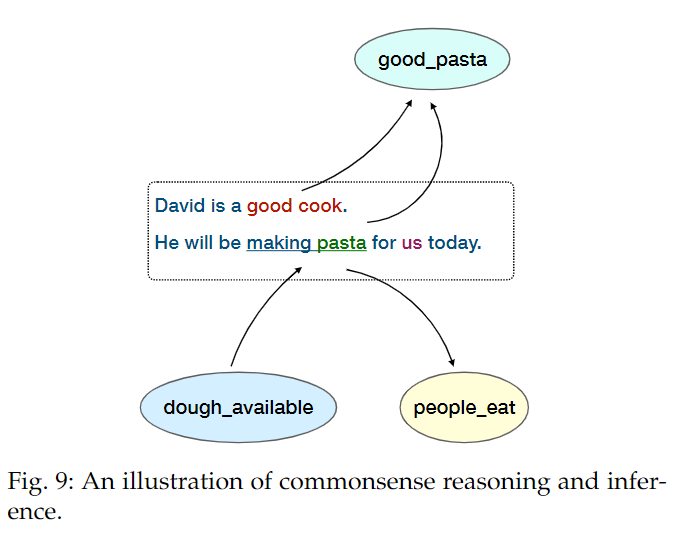 Figure 9
Figure 9
3.4 Sentiment Reasoning
Apart from exploring the what, we should also explore the who and why.
3.4.1 Who?
The Opinion Holder .
Consider the following two lines of opinionated text:
- a. The movie was too slow and boring.
- b. Stella found the movie to be slow and boring.
第一句的意见持有者是说话者,而第二句是 Stella。
该任务可能更加复杂,需要映射同一实体术语(例如 Jonathan、John)的不同用法或代词(he、she、它们)(Liu,2012)。
故许多作品研究了意见持有者识别任务——意见提取的子任务。其方法有:
named-entity recognition (Kim & Hovy, 2004),
parsing and ranking candidates (Kim & Hovy, 2006),
semantic role labeling (Wiegand & Ruppenhofer, 2015),
structured prediction using CRFs (Choi et al., 2006),
multi-tasking (Yang & Cardie, 2013), amongst others.
3.4.2 Why?
为了对意见持有者的特定情绪进行推理,重要的是要了解情绪的目标(Deng & Wiebe,2014),以及是否存在持有此类情绪的影响。
- For instance, when stating "I am sorry that John Doe went to prison.", understanding the target of the sentiment in the phrase "John Doe goes to prison", and knowing that "go to prison" has negative implications on the target, implies positive sentiment toward John Doe.
3.5 Domain Adaptation 领域适应
大多数最先进的情感分析模型都在域内训练数据集。然而,每个域管理大量的训练数据是不切实际的。情感分析中的域适应通过学习不可见域的特征来解决这个问题。
Breakthroughs:adversarial learning、bag of words、distributed word representations such as Glove, BERT.
3.5.1 Use of External Knowledge
虽然全局或上下文词嵌入已经显示出它们在建模域不变和特定表示方面的有效性,但将这些嵌入与多关系外部知识图相结合以进行域适应可能是一个很好的想法。例如 Glove,因为这些嵌入不是在显式语义关系上训练的。语义知识图可以使用领域通用概念建立多个领域特定领域概念之间的关系——提供可用于域适应的重要信息。如图11。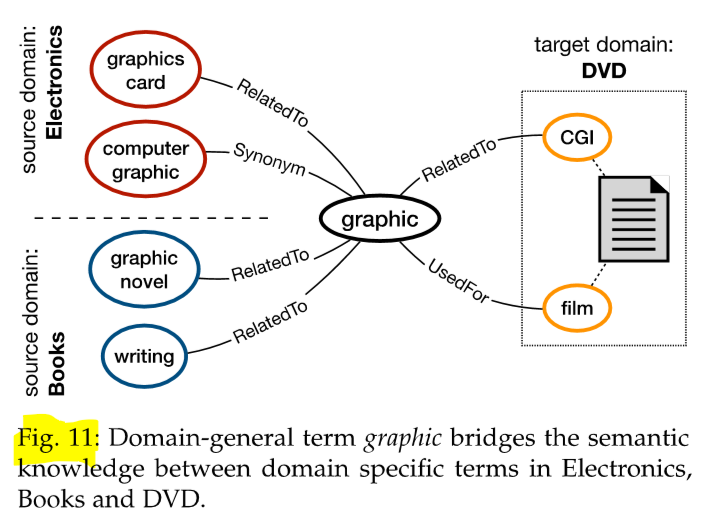
3.5.2 Scaling Up to Many Domains
该领域的大多数现有工作都使用源域和目标域对的设置进行训练。
3.6 Multilingual Sentiment Analysis 多语言情感分析
大多数情感分析研究都是在英语数据集上进行的。
3.6.1 Language-Specific Lexicons
印地语、法语、阿拉伯语等其他语言,没有太多精心策划的词典可用。
3.6.2 Sentiment Analysis of Code-Mixed Data
社交媒体帖子内容上的人是多种语言混合的。
- For example, "Itna izzat diye aapne mujhe !!! Tears of joy. :'( :'(", in this sentence, the bold text is in Hindi with roman orthography, and the rest is in English.
3.6.3 Machine Translation as a Solution to Multilingual
机器翻译可以用作多语言或跨语言情感分析的解决方案。Saadany & Orasan (2016) 的几篇论文; Balamurali 等人。 (2013) 尝试了这个问题。Saadany & Orasan (2010) 声称,当从阿拉伯语翻译成英语时,不会保留相关情绪用于同义词、否定、变音符号和惯用表达。
3.7 Sarcasm Analysis
由于文本的比喻性质,检测讽刺非常具有挑战性,伴随着细微差别和隐含意义(Jorgensen 等,1984)。
考虑的因素有:
prosodic cues (Bryant, 2010; Woodland & Voyer, 2011),
acoustic features including low-level descriptors,
and spectral features (Cheang & Pell, 2008).
Whereas in textual systems, traditional approaches consider rule-based (Khattri et al., 2015) or statistical patterns (Gonz ́alez-Ib ́a ̃nez et al., 2011b), stylistic patterns (Tsur et al., 2010), incongruity (Joshi et al., 2015; Tay et al., 2018a), situational disparity (Riloff et al., 2013), and hashtags (Maynard & Greenwood, 2014).
3.7.1 Leveraging Context in Sarcasm Detection
与情感分析(第 3.2 节和第 3.3 节)类似,讽刺检测可以受益于对话历史、作者趋势和多模态提供的上下文线索。
User Profiling and Conversational Context
authorial context:利用作者上下文通过查看作者的历史和元数据(Bamman & Smith, 2015; Hazarika et al., 2018a)来深入研究分析作者的讽刺倾向(用户分析)。
conversational context. 会话上下文使用从周围话语中获得的附加信息来确定句子是否具有讽刺意味(Ghosh 等人,2018 年)。
For example, "He sure played very well" is sarcastic, it is imperative to look at prior statements in the conversation to reveal facts ("The team lost yesterday").
Multimodal Context
音调的变化、单词、直脸等均是线索。
图 12 显示了来自该数据集的两种情况,其中讽刺是通过模态之间的不一致来表达的。在第一种情况下,语言模态表示恐惧或愤怒。相比之下,面部模态缺乏任何与文本模态一致的可见焦虑迹象。在第二种情况下,文本表示赞美,但发声和面部表情显示无差异。

3.7.2 Annotation Challenges
Intended vs. Perceived Sarcasm
困难:perceived sarcasm、the low annotator agreements across the datasets
方法:utilize perceptual uncertainty、rely on self annotated data collection
3.7.3 Target Identification in Sarcastic Text
任务:识别嘲笑对象
3.7.4 Style Transfer between Sarcastic and Literal
任务:将具有比喻意义转换为其真实和字面形式的意义。
- 例如,"I loved sweating under the sun the whole day" to "I hated sweating under the sun the whole day".
3.7.5 Sentiment and Creative Language
其他形式的创造性语言工具,如讽刺、幽默等,也与情感分析有共同依赖。
Ironyis more generic than sarcasm as it used to mean the opposite of what is being said.
Humor is another tool that is often used in human language.
3.8 Sentiment-Aware Natural Language Generation (NLG)
现在的模型能够没有经过训练来产生能够模拟人类交流的情感内容。
3.8.1 Conditional Generative Models
我们人类的几个特征——emotion, sentiment, prior assumptions, intent, or personality ——均可以通过模型生成语言特征。
思路与方法:
- learning disentangled representations, where the key idea is to separate the textual content from high-level attributes,VAEs (Hu et al., 2017), GANs (Wang & Wan, 2018) or Seq2Seq models (Radford et al., 2017)
- pose the problem as an attributeto-text translation task (Dong et al., 2017; Zang & Wan, 2017).
3.8.1.2 Aspect-level text summarization:
如图 14。方面级文本摘要任务包括两个阶段:: aspect extraction and aspect summarization。第一阶段提取输入文本中讨论的所有方面。后者从源文本中生成提取方面的抽象或提取要点。在抽象要点的情况下,模型生成以给定方面为条件的内容。 Figure 14
Figure 14
3.8.2 Sentiment-Aware Dialogue Generation
情感控制文本领域也渗透到对话系统中。这里的目的是为这些系统配备情感智能以提高用户兴趣和参与度(Partala & Surakkar,2004;Prendinger & Ishizuka,2005)。两个关键点:
- Given a user query, determine the best emotional/sentiment response adhering to social rules of conversations.
- Generate the response eliciting that emotion/sentiment. Present works in this field either approach these two sub-problems independently (Ghosh et al., 2017) or in a joint manner (Gu et al., 2019).
3.8.3 Sentiment-Aware Style Transfer
Style transfer of sentiment 侧重于通过删除或插入新的情感词来翻转句子的情感。
- E.g., to change the sentiment of "The chicken was delicious", we need to find a replacement of the word delicious that carries negative sentiment.
思路:依赖基于规则的 (Li et al., 2018) 和基于对抗学习、应该与 ABSA(基于方面的情感分析)研究一起进行研究,以学习主题/方面和情感词之间的关联。
3.9 Bias in Sentiment Analysis Systems
公平性最近受到了广泛关注。
情感分析系统通常用于敏感的领域,例如医疗保健,它处理咨询等敏感话题。
3.9.1 Identifying Causes of Bias in Sentiment Analysis Systems
Bias 可以通过三个主要来源引入到情感分析模型中:
- Bias in word embeddings: 公开的数据集来自女性特征非常少,自然无法代表女性观点。
- Bias in the model architecture: 情感分析系统通常使用元信息,例如性别标识符和人口统计指标,包括年龄、种族、国籍和地理线索。可能会导致隐形的偏见。
For example, the general perception about good weather,good traffic, cheap phone can vary among the Indian and American populations. - Bias in the training data:
For instance, samples from female subjects frequently belonging to positive sentiment category. An author's stylistic sense of writing can also be one of the many sources of bias in sentiment systems.
E.g., one person uses strong sentiment words to express a positive opinion but prefers to use milder sentiment words in exhibiting negative opinions.
Similarly, sentiment expression might vary across races and genders, e.g., as shown in a recent study by Bhardwaj et al. (2020). 当同一个句子中的性别词从阳性变为阴性时,情感分析模型可能会显示出情感强度的显着差异。
3.9.3 De-biasing
Approach:
提取一个数据子集没有表现出任何明确的偏见迹象。用单词替换扰乱文本,以生成训练数据中的反事实案例。然后,这些生成的实例可用于规范模型的学习,或者通过约束嵌入空间对扰动保持不变或最小化正确实例和扰动实例之间的预测差异。
然而,现有的研究主要集中在识别与上下文无关的词表示中的性别偏见,例如 GloVe(Bolukbasi 等人,2016;Kaneko 和 Bollegala,2019;Kumar 等人,2020)。
相反,BERT 词向量到向量的映射高度依赖于上下文,这使得很难分析 BERT 固有的偏差。
In Zhao et al. (2019); Basta et al. (2019); Gonen & Goldberg (2019), 等人对 ELMo 应用去偏。
Kurita等人(2019)提出了一种基于模板的方法来量化BERT中的偏差。
Sahlgren & Olsson (2019) 研究了上下文化和非上下文化瑞典语嵌入的偏差。
除了模型的传统偏差外,在做出研究选择时,偏差也可以在更高级别存在。一个简单的例子是社区倾向于求助于基于英语的语料库。
4 CONCLUSION
情感分析通常被视为一个简单的分类任务,将内容分类为正面、负面和中性情绪。相比之下,情感分析的任务非常复杂,受人类动机、意图、上下文细微差别等多个变量控制。
以上为情感分析各个子任务的大概分析内容。

 技术文档
技术文档
 推荐好文
推荐好文







 155-2731-8020
155-2731-8020