















































软件

产品


arXiv论文“Graph-DETR3D: Rethinking Overlapping Regions for Multi-View 3D Object Detection“,22年6月,中科大、哈工大和商汤科技的工作。

从多个图像视图中检测3-D目标是视觉场景理解的一项基本而富有挑战性的任务。由于其低成本和高效率,多视图3-D目标检测显示出了广阔的应用前景。然而,由于缺乏深度信息,通过3-D空间中的透视图去精确检测目标,极其困难。最近,DETR3D引入一种新的3D-2D query范式,用于聚合多视图图像以进行3D目标检测,并实现了最先进的性能。
本文通过密集的引导性实验,量化了位于不同区域的目标,并发现“截断实例”(即每个图像的边界区域)是阻碍DETR3D性能的主要瓶颈。尽管在重叠区域中合并来自两个相邻视图的多个特征,但DETR3D仍然存在特征聚合不足的问题,因此错过了充分提高检测性能的机会。
为了解决这个问题,提出Graph-DETR3D,通过图结构学习(GSL)自动聚合多视图图像信息。在每个目标查询和2-D特征图之间构建一个动态3D图,以增强目标表示,尤其是在边界区域。此外,Graph-DETR3D得益于一种新的深度不变(depth-invariant)多尺度训练策略,其通过同时缩放图像大小和目标深度来保持视觉深度的一致性。
Graph-DETR3D的不同在于两点,如图所示:
1)动态图特征的聚合模块;
2)深度不变的多尺度训练策略。它遵循DETR3D的基本结构,由三个组件组成:图像编码器、transformer解码器和目标预测头。给定一组图像I={I1,I2,…,IK}(由N个周视摄像机捕捉),Graph-DETR3D旨在预测感兴趣边框的定位和类别。首先用图像编码器(包括ResNet和FPN)将这些图像变成一组相对L个特征图级的特征F。
然后,构建一个动态3-D图,通过动态图特征聚合(dynamic graph feature aggregation,DGFA)模块广泛聚合2-D信息,优化目标查询的表示。最后,利用增强的目标查询输出最终预测。
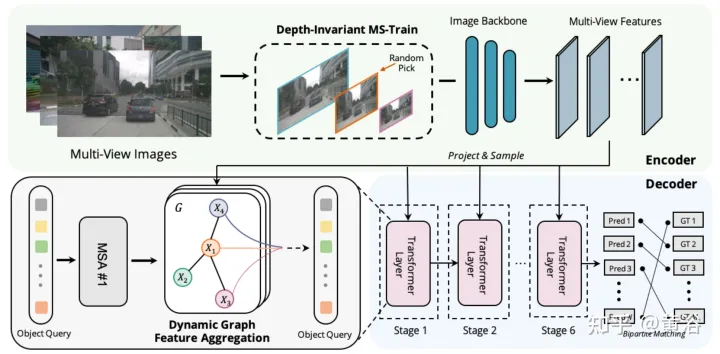
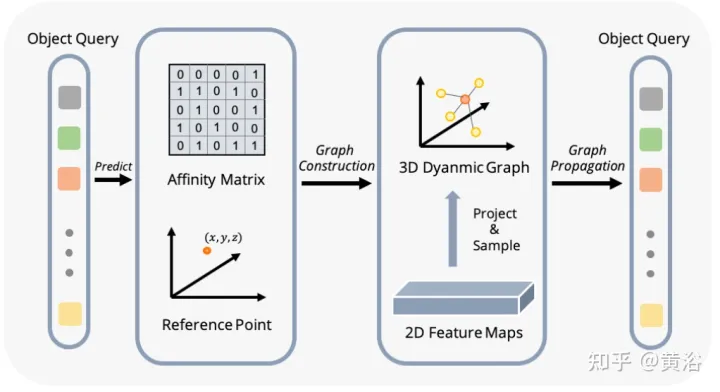
如图显示动态图特征聚合(DFGA)过程:首先为每个目标查询构造一个可学习的3-D图,然后从2-D图像平面采样特征。最后,通过图连接(graph connections)增强了目标查询的表示。这种相互连接的消息传播(message propagation)方案支持对图结构构造和特征增强的迭代细化方案。
多尺度训练是2D和3D目标检测任务中常用的数据增强策略,经证明有效且推理成本低。然而,它很少出现在基于视觉的3-D检测方法中。考虑到不同输入图像大小可以提高模型的鲁棒性,同时调整图像大小和修改摄像机内参来实现普通多尺度训练策略。
一个有趣的现象是,最终的性能急剧下降。通过仔细分析输入数据,发现简单地重新缩放图像会导致透视-多义问题:当目标调整到较大/较小的比例时,其绝对属性(即目标的大小、到ego point的距离)不会改变。
作为一个具体示例,如图显示这个多义问题:尽管(a)和(b)中所选区域的绝对3D位置相同,但图像像素的数量不同。深度预测网络倾向于基于图像的占用面积来估计深度。因此,图中的这种训练模式可能会让深度预测模型糊涂,并进一步恶化最终性能。

为此从像素透视重新计算深度。算法伪代码如下:

如下是解码操作:

重新计算的像素大小是:
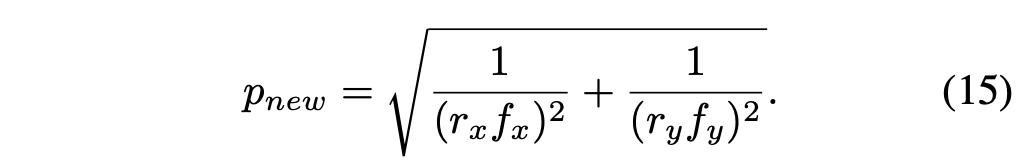
假设尺度因子r = rx = ry,则简化得到:
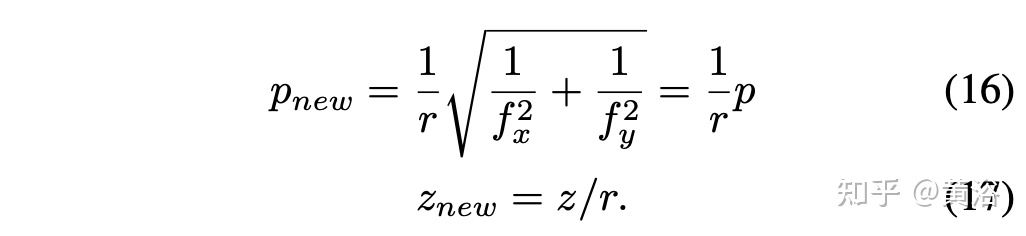
实验结果如下:
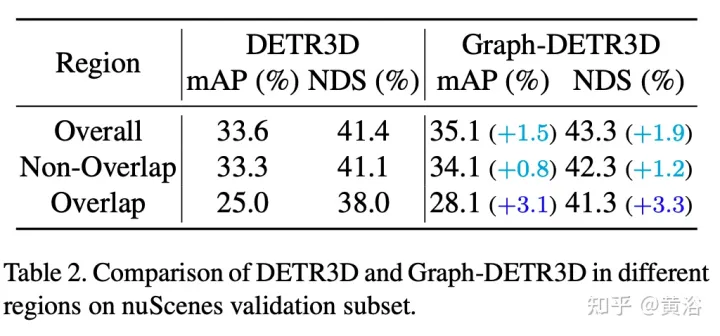
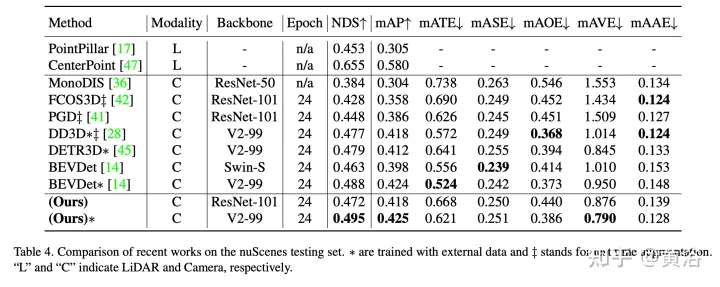
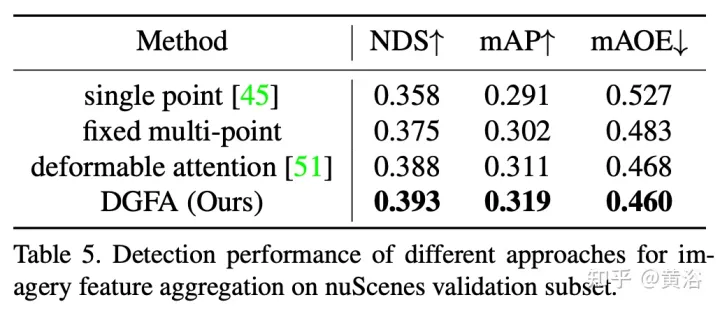
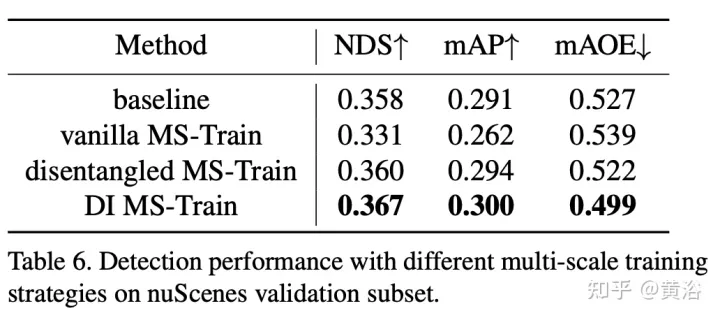
注:DI = Depth-Invariant
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















