















































软件

产品


昨晚睡得好吗?睡不好可以刷快手的《11 点睡吧》。这部当代人睡眠困境的微综艺,总曝光量达到 107亿,不但科普睡眠知识,更深度探讨都市人的喜怒哀乐[1]。惊人的曝光量背后,是快手对用户画像数据的精准分析,离不开强大技术支持下的推荐系统,得以让优质的内容被更多喜欢它的人看到。
作为超 3 亿日活、日均千万级短视频上传、强调社区普惠的短视频 APP,快手推荐系统在大规模复杂业务中面临着巨大性能挑战。想要化解算力瓶颈,异构计算是一个重要选项,这种使用不同类型指令集和体系架构的计算单元组成系统的计算方式,能够针对不同任务选择最优的计算架构,从而充分挥各种计算机构的优势,协同完成复杂的工作任务。

快手作为短视频内容平台,内容生产、内容理解、内容分发、内容消费、用户互动这些环节,构成了大规模的复杂业务,对算力产生更多元的需求。举例来说:在推荐业务场景中,需要根据用户画像推荐感兴趣的内容,就要从海量信息中选择与用户特征相关的结果,再通过“排序”来划分内容的优先级别。在这一过程中,参数服务器的作用非常重要,它负责存储、处理海量数据特征以及排序模型参数,保证任务高效、准确地完成。
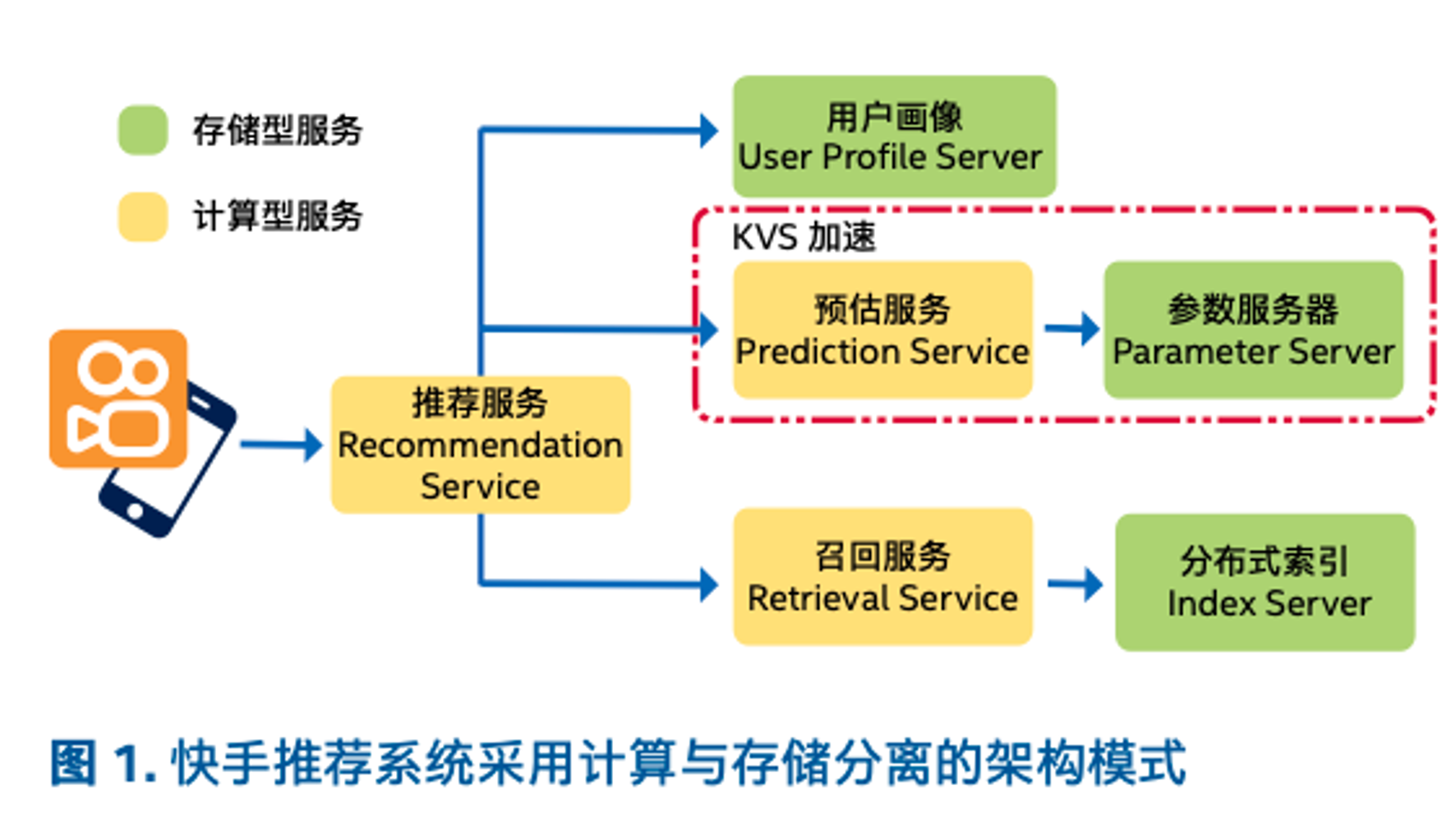
快手的推荐系统为了应对海量数据冲击,在架构上分离了计算与存储。参数服务器属于存储型服务,该服务要保存和实时更新上亿规模的用户画像、数十亿规模的短视频特征、以及千亿规模的排序模型参数。受限于容量和带宽的参数服务器,还要支撑每秒数亿次的 KV 请求,耗费大量 CPU 资源。
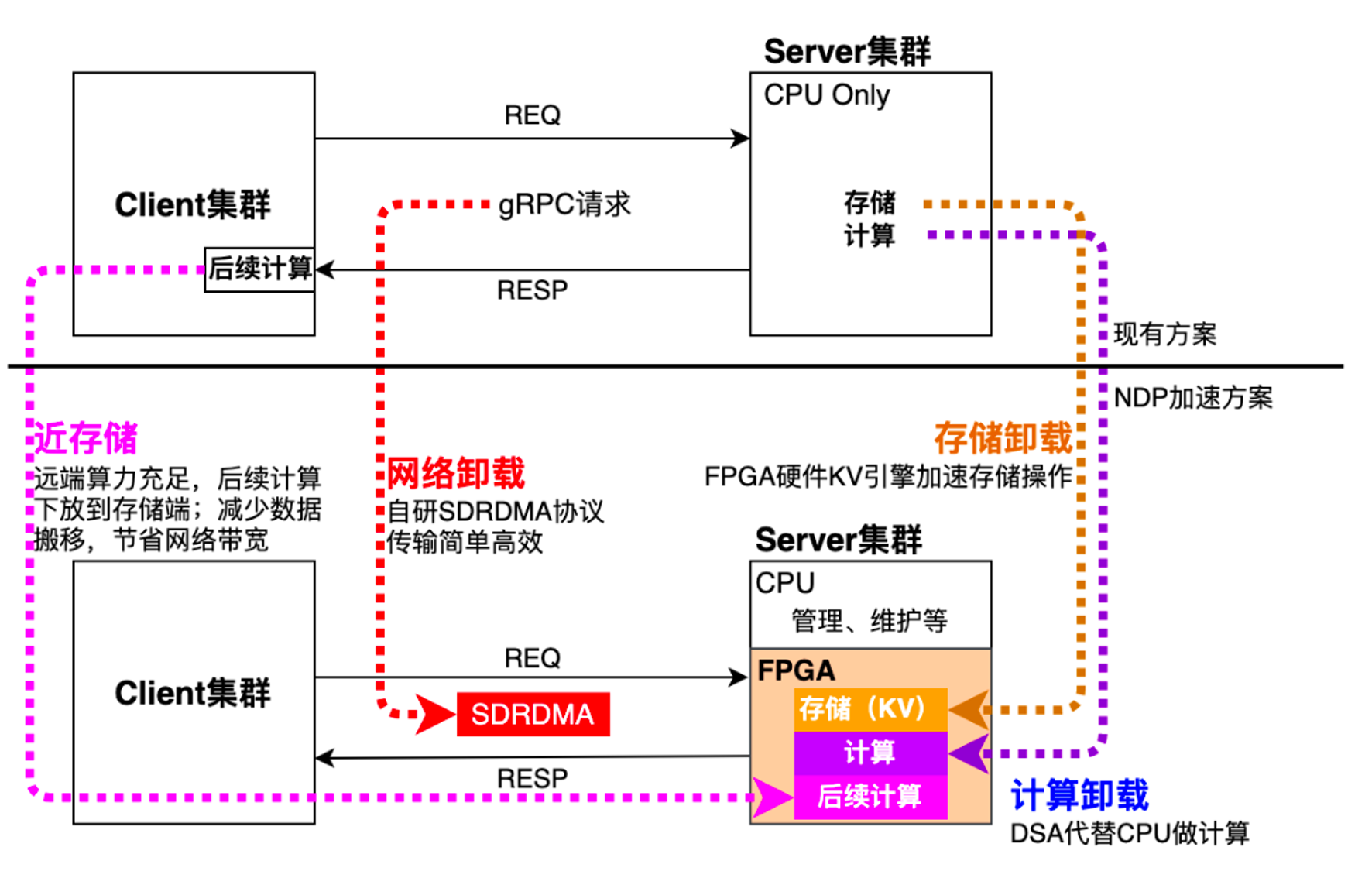
要解决此类瓶颈,最佳方案是使用不同计算设备处理不同负载。快手的LaoFe NDP 近数据架构,在计算体系结构上实现创新,使用英特尔® 至强®可扩展处理器、英特尔®️ Agilex™ FPGA 和英特尔®️ 傲腾™ 持久内存,借助软硬一体化、领域专用加速器设计,从而做到网络、存储、计算三重加速,为各个业务系统提供低延迟、高并发、高吞吐、低总体拥有成本的基础资源。

在网络层面,LaoFe NDP 架构将 CPU的网络数据处理转移到英特尔® Stratix 10 FPGA 上,同时基于该 FPGA 实现了“软件定义远程直接内存访问”协议(SD-RDMA),大幅降低了请求延时。
在存储层面,该架构打造了支持 SSD、英特尔® 傲腾™ 持久内存、以及 DRAM 的Key-Value 存储引擎,将CPU 层面的存储操作也转移到 FPGA 中,最大程度发挥 FPGA 的能力,相比 CPU 方案,将存储引擎的吞吐能力提升 5 倍以上。该引擎还利用英特尔® 傲腾™ 持久内存的特性,让基于异构存储的索引系统几乎达到纯 DRAM 相同的性能指标,成本降低 30%。同时相比之前小时级的故障恢复速度,异构存储的索引系统只需几分钟就能重新上线。
LaoFe NDP 的计算加速仰仗 FPGA 作为领域专用处理,可以更有效地并行处理数据,提供更高效的内存层次结构与定制化的执行单元,从而支持机器学习、深度学习和大数据等场景。英特尔®️ FPGA 具备富于弹性的可编程硬件能力,延时低且可精确控制,单位算力功耗低、 片上内存大,适合于快手延时要求高、批处理比较小、
并发性和重复性强的应用场景。
快手LaoFe NDP 架构在英特尔软硬件优化下,最终实现了如下优势:
■ 系统吞吐显著提升,延时显著降低:参数服务器的吞吐性能提升了 5-6 倍,整体请求延时降低了 70%-80%,提供更好的用户体验。
■ 更好地控制 TCO:FPGA 的强大性能提供远超传统方案的吞吐能力,仅需部署少量的服务器就能满足特性的性能指标要求,替代比可达到 1:5,有效降低 TCO。
■ 降低性能抖动:基于CPU的软件方案常因需要进行高频率更新而出现性能抖动,而通过FPGA来处理负载,能大幅减少性能抖动。
通过快手的实践能够看出,以异构计算加速不同负载,能够显著提升在推荐等场景下的系统吞吐与延时表现。未来,英特尔还会和快手等合作伙伴一起,推进面向未来数据中心的异构参考架构,通过CPU、IPU、XPU的产品组合以及软件堆栈,以及智能网络结构,提供跨越整个数据管道的解决方案,高效挖掘海量数据中的智慧,让用户与用户、用户与内容、用户与商品可及时按需建立高效、有温度的连接互动。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















