















































软件

产品


在Spark几种运行模式的配置中涉及jar包都是我先前准备的,这些jar都是关于词频统计的,我使用的idea打的jar,相信大家到这里应该会有一定能力去编写一个词频统计的代码并打成jar包上传至虚拟机,如果有什么问题可以自行搜索。
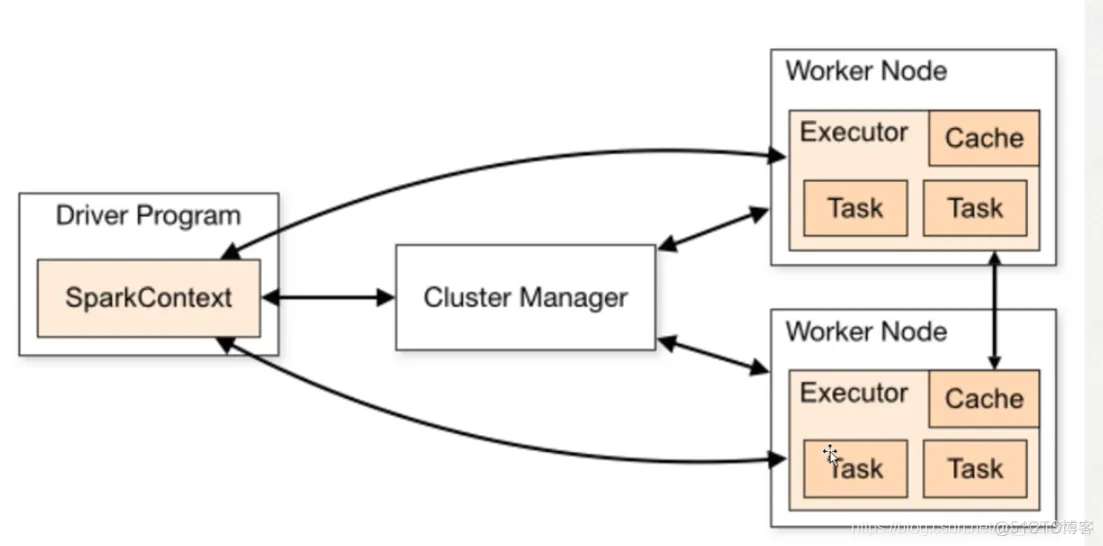
运行流程:sparkContext向Master申请所需要的资源,然后Master在Worker节点上申请资源,Worker向Master注册,Master通过指令让worker启动Executor,Executor进程主要负责运行Task任务,Executor会返回报告给sparkContext,最后应用程序会将运行结果报告给用户。
这里首先要修改原文件名,去掉.template
panda-pro02.xiong.com 自己的hostname
这里首先要修改原文件名,去掉.template
JAVA_HOME=/opt/modules/jdk1.8.0_11
SCALA_HOME=/opt/modules/scala-2.11.8
进入spark目录下conf
SPARK_CONF_DIR=/opt/modules/spark-2.2.0-bin-custom-spark/conf
配置端口号
SPARK_MASTER_HOST=panda-pro02.xiong.com
SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_CORES=1
SPARK_WORKER_MEMORY=1g
SPARK_WORKER_PORT=7078
SPARK_WORKER_WEBUI_PORT=8081
sbin/start-all.sh
进入web界面ip+8080
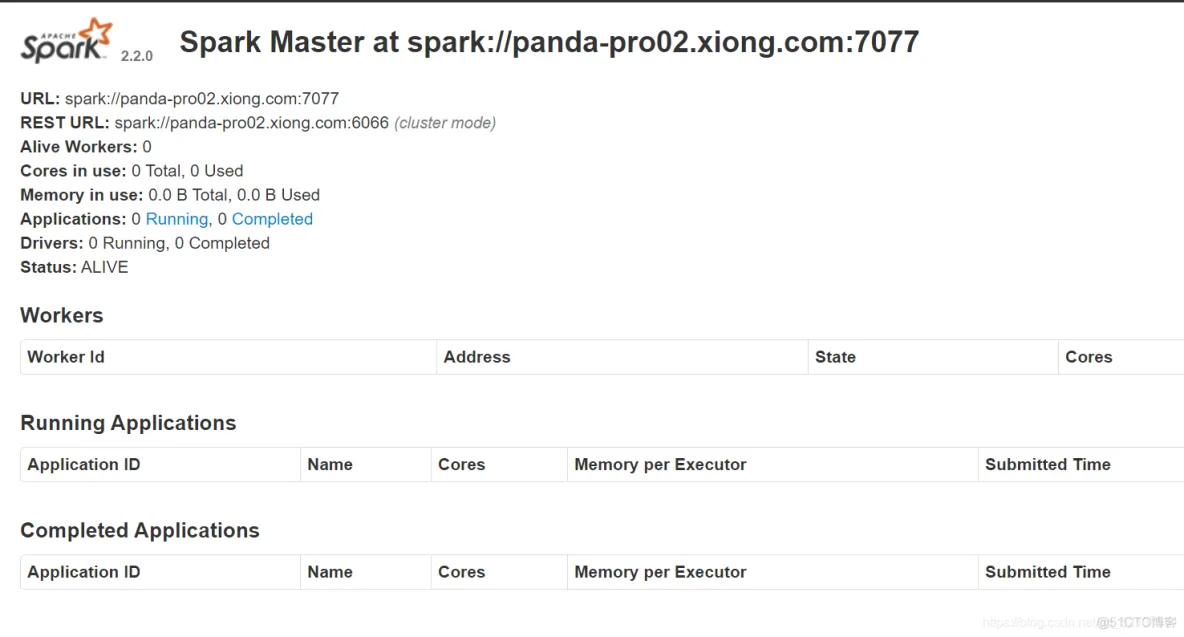
客户端测试
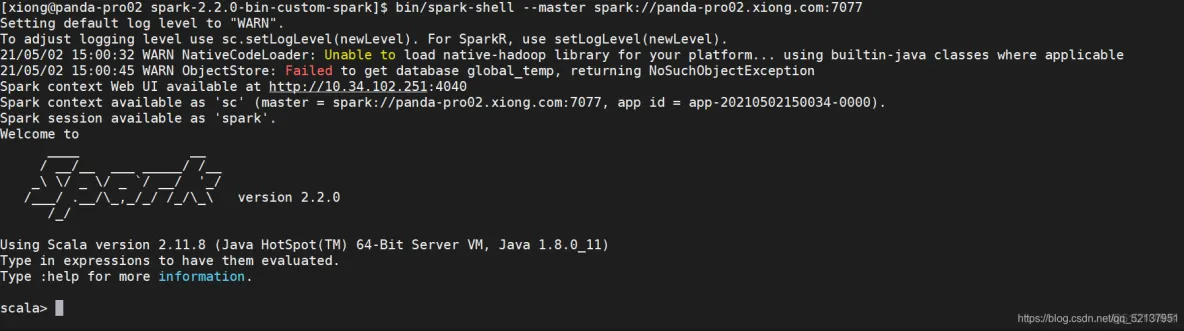
bin/spark-shell --master spark://panda-pro02.xiong.com:7077
在spark on yarn的模式下有一个线程会实时监控任务,如果这个任务超过了(虚拟、物理)内存,它会把这个任务给kill掉,上述文件设置问true就会kill了,设置false就不会kill,等时间长之后慢慢执行,若你的内存给的大,就不用配置这个文件了。
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
bin/spark-shell --master yarn --deploy-mode client
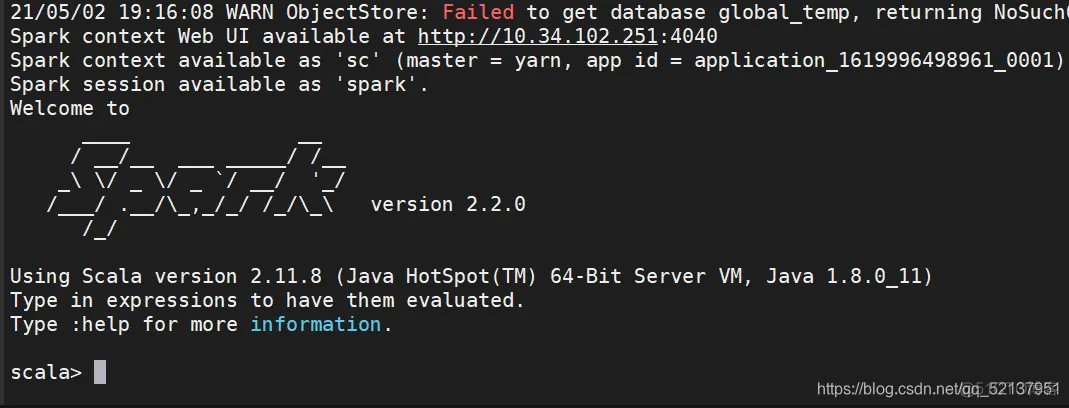
在yarn的web界面上看到

stu.txt自己先创建好,里面填入一些单词
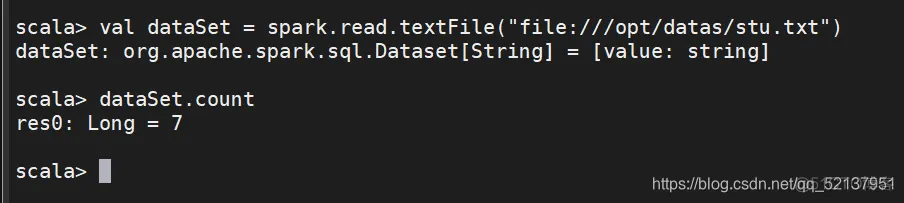
val dataSet = spark.read.textFile("file:///opt/datas/stu.txt").count
bin/spark-submit --class com.spark.test.Test --master yarn --deploy-mode cluster /opt/jars/Myspark.jar file:///opt/datas/stu.txt
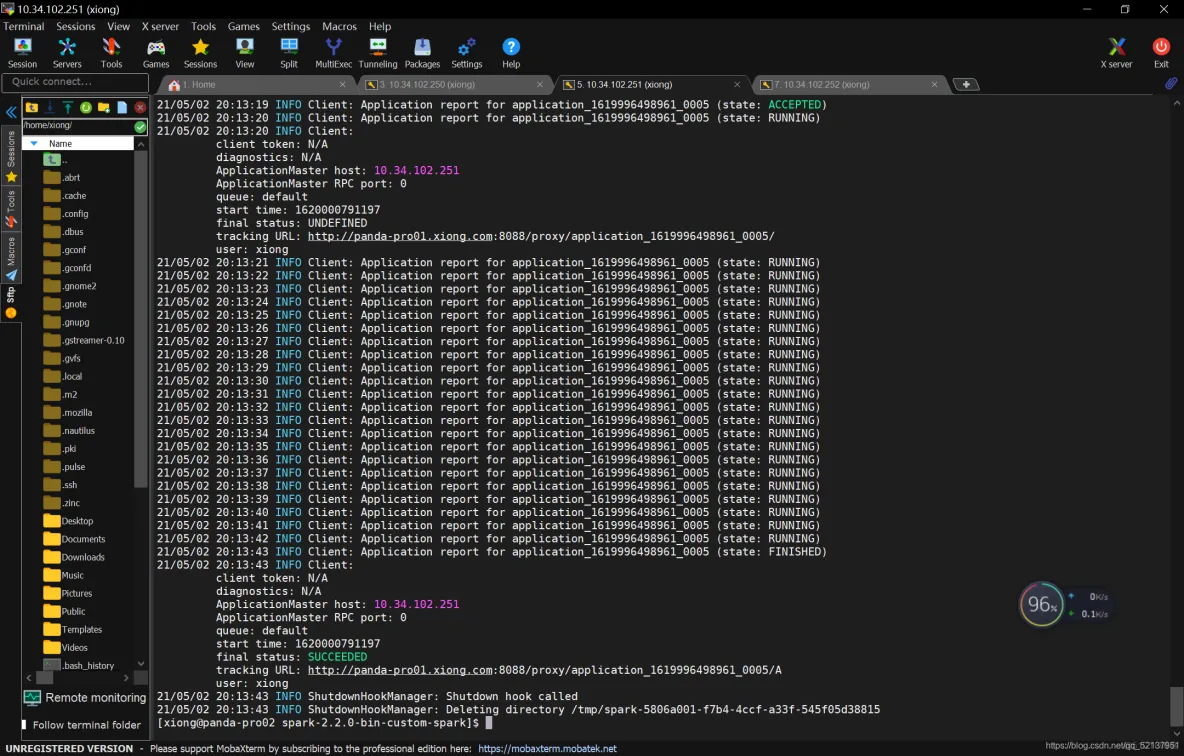
在yarn的web界面可以看到

上图看到有两次failed,这是由于内存不够了,yarn监控程序会kill掉一些进程,这样会导致失败,所以多试几次,或者关掉一些不必要的进程,或者多给这台机器分配一点运行内存,前提是电脑配置允许。
关于spark的几种Spark几种运行模式的配置与测试就到这里,过程有些坎坷,总之还是顺利完成了,作者能力有限,如有不当之处,还请指正。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















