















































软件

产品


进行深度学习模型训练的时候,一般使用GPU来进行加速,当训练样本只有百万级别的时候,单卡GPU通常就能满足我们的需求,但是当训练样本量达到上千万,上亿级别之后,单卡训练耗时很长,这个时候通常需要采用多机多卡加速。深度学习多卡训练常见有两种方式,一种是数据并行化(data parallelism),另外一种是模型并行化(model parallelism)。
数据并行化:每个GPU上面跑一个模型,模型与模型之间结构参数相同,只是训练的数据不一样,每个模型通过最后的loss计算得到梯度之后,再把梯度传到一个parameter server(PS)上进行参数平均average gradient,然后再根据average gradient更新模型的参数。
数据并行化分为梯度的更新分为同步和异步两种模式。
同步模式:等到所有的数据分片都完成了梯度计算并把梯度传到PS之后统一的更新每个模型的参数。优点是训练稳定,训练出来的模型得到精度比较高;缺点是训练的时间取决于分片中最慢的那个片,所以同步模式适用于GPU之间性能差异不大情况下。
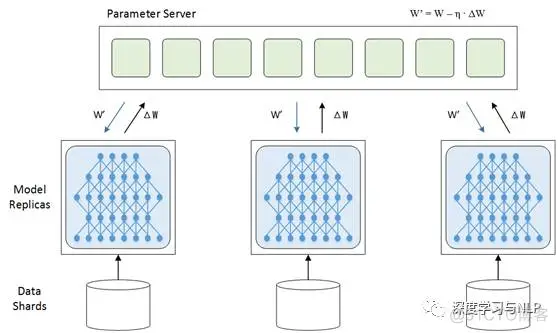
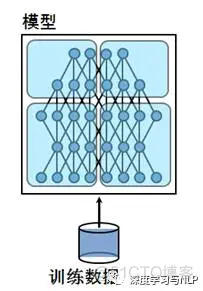
模型并行化:当一个模型非常复杂,非常大,达到单机的内存根本没法容纳的时候,模型并行化就是一个好的选择。直观说就多多个GPU训练,每个GPU分别持有模型的一个片。它的优点很明显,大模型训练,缺点就是模型分片之间的通信和数据传输很耗时,所以不能简单说,模型并行就一定比数据并行要快。
还有数据并行和模型并行的混合模型:
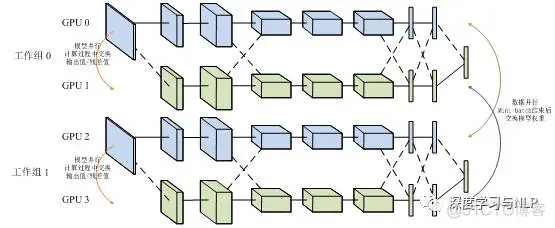
数据并行适用于数据量比较小时快速训练模型,模型并行适用于大数据、大模型场景下。这里只是简单介绍,想要深入了解细节可以找其他资料学习一下。下面主要基于tensorflow讲一个数据并行化的实例。
1、 单机多卡训练:给个例子,比如一台机器上装有4个GPU卡,以cpu做为PS(master),主要保存一下参数和变量,进行梯度平均。其余4个GPU训练模型(worker),进行一些计算量比加大的操作。
1) 本地对数据切分为一个一个batch;
2) 把数据分别放到送到4个GPU进行模型训练,每个GPU拿到数据不一样;
3) 四个GPU训练,求loss得到梯度,并把梯度送回到CPU进行模型平均。
4) cpu接收4个gpu传来的梯度,进行梯度平均。
5) 四个GPU跟新参数
6) 重复2~5知道模型收敛。
2、 分布式的多久多卡:当是在一个多台机器的集群上训练的时候采用这种方式,在tensorflow中需要明确指定ps和worker的地址,这种方式兼容单机多卡,只是把ps和worker的地址设为local就可以了。
下面简要介绍下tensorflow中支持多卡训练和参数更新的几个API,具体介绍可以参考这篇文章(Distributedtensorflow实现原理)
Tensorflow进行重复性训练有In-graph replication和Between-graphreplication两种方式,In-graph replication就是数据并行化模式,Between-graphreplication就是数据并行化模式。梯度更新有异步Asynchronous training和同步Synchronous training两种模式。
Tensorflow官网也给了一个cifar10_multi_gpu_train.py 的例子,在单机多卡上运行,这里我给一个自己做的单机多卡训练的简单例子供参考,自己在搭建这个结构过程中也栽了很多坑,还在继续探索中,仅有训练部分。
程序主要分为五个部分:
Main函数:定义主要运行逻辑;
Run_epoch函数:定义主要训练逻辑;
Generate_feed_dic函数:产生训练需要的batch样本;
Multi_gpu_model函数:定义多个tower,每个tower对应一个gpu;
Average_gradients函数:梯度平均计算。
一下是完整代码:
#critital class define
#getaverage gradient
defaverage_gradients(tower_grads):
average_grads = []
for grad_and_vars in zip(*tower_grads):
grads = []
for g, _ in grad_and_vars:
expanded_g = tf.expand_dims(g, 0)
grads.append(expanded_g)
grad = tf.concat(axis=0, values=grads)
grad = tf.reduce_mean(grad, 0)
v = grad_and_vars[0][1]
grad_and_var = (grad, v)
average_grads.append(grad_and_var)
return average_grads
#setupmultiple gpu tower
defmulti_gpu_model(num_gpus=4, word_embeddings = None):
grads = []
global_step = tf.Variable(0,name="global_step", trainable=False)
optimizer = tf.train.AdamOptimizer(1e-3)
withtf.variable_scope(tf.get_variable_scope()) as initScope:
for i in range(num_gpus):
withtf.device("/gpu:%d"%i):
withtf.name_scope("tower_%d"%i):
siameseModel = SiameseLSTM(
sequence_length=FLAGS.max_document_length,
embedding_size=FLAGS.embedding_dim,
hidden_units=FLAGS.hidden_units,
l2_reg_lambda=FLAGS.l2_reg_lambda,
batch_size=FLAGS.batch_size,
word_embeddings=word_embeddings)
tf.get_variable_scope().reuse_variables()
tf.add_to_collection("train_model", siameseModel)
grad_and_var =optimizer.compute_gradients(siameseModel.loss)
grads.append(grad_and_var)
tf.add_to_collection("loss",siameseModel.loss)
tf.add_to_collection("accuracy",siameseModel.accuracy)
tf.add_to_collection("distance",siameseModel.distance)
with tf.device("cpu:0"):
averaged_gradients =average_gradients(grads)
train_op =optimizer.apply_gradients(averaged_gradients, global_step=global_step)
return train_op,global_step
#generating training data
defgenerate_feed_dic(sess, batch_generator,feed_dict,train_op):
SMS =tf.get_collection("train_model")
for siameseModel in SMS:
x1_batch, x2_batch, y_batch =batch_generator.next()
if random()>0.5:
feed_dict[siameseModel.input_x1] =x1_batch
feed_dict[siameseModel.input_x2] =x2_batch
feed_dict[siameseModel.input_y] =y_batch
feed_dict[siameseModel.dropout_keep_prob]= FLAGS.dropout_keep_prob
else:
feed_dict[siameseModel.input_x1] =x2_batch
feed_dict[siameseModel.input_x2] =x1_batch
feed_dict[siameseModel.input_y] =y_batch
feed_dict[siameseModel.dropout_keep_prob]= FLAGS.dropout_keep_prob
return feed_dict
#define main trainingprocess
def run_epoch(sess,train_x1_idsList,train_x2_idsList,train_y,scope,global_step,train_op=None,is_training=False):
if is_training:
epoches = len(train_x1_idsList) //FLAGS.batch_size
batch_generator =datatool.data_iterator(train_x1_idsList, train_x2_idsList,train_y,FLAGS.batch_size,FLAGS.max_document_length)
# siameseModels =tf.get_collection("train_model")
while epoches > 0:
feed_dict = {}
epoches -= 1
feed_dict =generate_feed_dic(sess,batch_generator,feed_dict,train_op)
i = FLAGS.num_iteration
while i > 0:
i = i - 1
losses =tf.get_collection("loss")
accuracy =tf.get_collection("accuracy")
distance =tf.get_collection("distance")
total_accuracy =tf.add_n(losses, name='total_accu')
total_distance = tf.add_n(losses,name='total_distance')
total_loss = tf.add_n(losses,name='total_loss')
avg_losses = total_loss / 4
avg_accu = total_accuracy / 4
avg_dist = total_distance / 4
time_str =datetime.datetime.now().isoformat()
_,step,avg_losses,avg_accu,avg_dist =sess.run([train_op,global_step,total_loss,avg_accu,avg_dist],feed_dict)
输出训练精度
print("TRAIN {}: step {},avg_loss {:g}, avg_dist {:g}, avg_acc {:g}".format(time_str, step,avg_losses, avg_dist, avg_accu))
#whole training process
defmain(argv=None):
print("\nParameters:")
for attr, value insorted(FLAGS.__flags.items()):
print("{}={}".format(attr.upper(),value))
print("")
加载词向量
word2id, word_embeddings =datatool.load_word2vec("your dir for word2vec")
print("load train data")
(train_x1_idsList,train_x2_idsList,train_y),(valid_x1_idsList, valid_x2_lList,valid_y) =datatool.get_data_for_siamese(word2id, FLAGS.data_path)
print("starting graph def")
gpu_options =tf.GPUOptions(per_process_gpu_memory_fraction=0.8)
withtf.Graph().as_default():#,tf.device('/cpu:0')
session_conf = tf.ConfigProto(
allow_soft_placement=FLAGS.allow_soft_placement,
log_device_placement=FLAGS.log_device_placement,
gpu_options=gpu_options)
sess = tf.Session(config=session_conf)
print("started session")
print ("build multiplemodel")
with tf.name_scope("train")as train_scope:
print("define multiple gpumodel and init the training operation")
train_op,global_step =multi_gpu_model(FLAGS.num_gpus,word_embeddings)
print ("init allvariable")
sess.run(tf.global_variables_initializer())
print ("run epochestage")
run_epoch(sess,train_x1_idsList,train_x2_idsList,train_y,train_scope,global_step,train_op,True)
# Checkpoint directory. Tensorflowassumes this directory already exists so we need to create it
timestamp = str(int(time.time()))
checkpoint_dir =os.path.abspath(os.path.join(out_dir, "checkpoints"))
checkpoint_prefix =os.path.join(checkpoint_dir, "model")
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
out_dir =os.path.abspath(os.path.join(os.path.curdir, "runs", timestamp))
print("Writing to {}\n".format(out_dir))
saver =tf.train.Saver(tf.global_variables(), max_to_keep=100)
注意:我用的是已经训练好的词向量,这里只需要加载进来就可以了。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















