















































软件

产品


首先来简单说明一下 Seq2Seq 模型,如果搞过深度学习,想必一定听说过 Seq2Seq 模型,Seq2Seq 其实就是 Sequence to Sequence,也简称 S2S,也可以称之为 Encoder-Decoder 模型,这个模型的核心就是编码器(Encoder)和解码器(Decoder)组成的,架构雏形是在 2014 年由论文 Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation, Cho et al 提出的,后来 Sequence to Sequence Learning with Neural Networks, Sutskever et al 算是比较正式地提出了 Sequence to Sequence 的架构,后来 Neural Machine Translation by Jointly Learning to Align and Translate, Bahdanau et al 又提出了 Attention 机制,将 Seq2Seq 模型推上神坛,并横扫了非常多的任务,现在也非常广泛地用于机器翻译、对话生成、文本摘要生成等各种任务上,并取得了非常好的效果。
下面的图示意了 Seq2Seq 模型的基本架构:
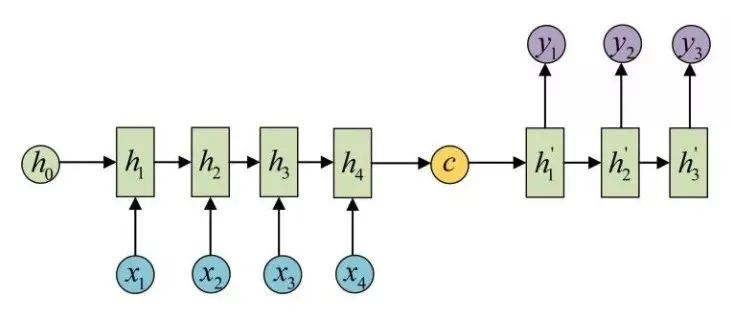
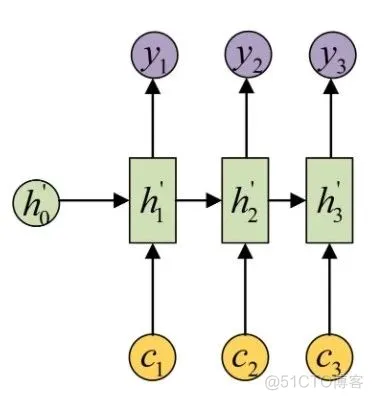
可以看到图中有一个中间状态c向量,在c向量左侧的我们可以称之为编码器(Encoder),编码器这里示意的是 RNN 序列,另外 RNN 单元还可以使用 LSTM、GRU 等变体, 在编码器下方输入了,代表模型的输入内容,例如在翻译模型中可以分别代表“我爱中国”这四个字,这样经过序列处理,它就会得到最后的输出,我们将其表示为c向量,这样编码器的工作就完成了。在图中c向量的右侧部分我们可以称之为解码器(Decoder),它拿到编码器生成的c向量,然后再进行序列解码,得到输出结果,例如刚才输入的“我爱中国”四个字便被解码成了 “I love China”,这样就实现了翻译任务,以上就是最基本的 Seq2Seq 模型原理。
另外还有一种变体,c向量在每次解码的时候都会作为解码器的输入,其实原理都是类似的,如图所示:
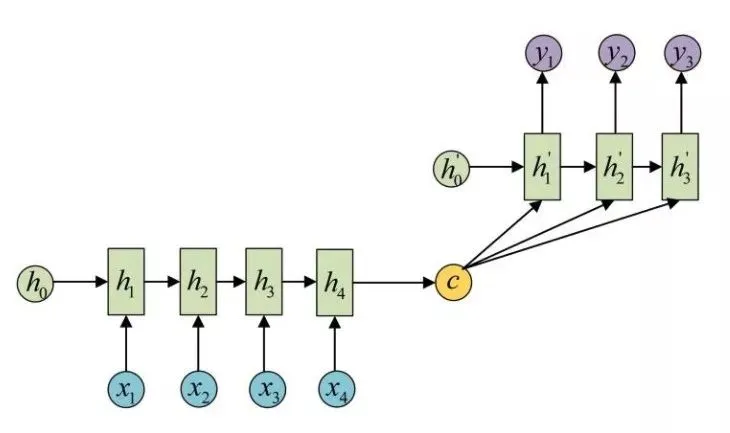
这种模型架构是通用的,所以它的适用场景也非常广泛。如机器翻译、对话生成、文本摘要、阅读理解、语音识别,也可以用在一些趣味场景中,如诗词生成、对联生成、代码生成、评论生成等等,效果都很不错。
通过上图我们可以发现,Encoder 把所有的输入序列编码成了一个c向量,然后使用c向量来进行解码,因此,c向量中必须包含了原始序列中的所有信息,所以它的压力其实是很大的,而且由于 RNN 容易把前面的信息“忘记”掉,所以基本的 Seq2Seq 模型,对于较短的输入来说,效果还是可以接受的,但是在输入序列比较长的时候,c向量存不下那么多信息,就会导致生成效果大大折扣。
Attention 机制解决了这个问题,它可以使得在输入文本长的时候精确率也不会有明显下降,它是怎么做的呢?既然一个c向量存不了,那么就引入多个c向量,称之为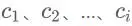 ,在解码的时候,这里的i对应着 Decoder 的解码位次,每次解码就利用对应的
,在解码的时候,这里的i对应着 Decoder 的解码位次,每次解码就利用对应的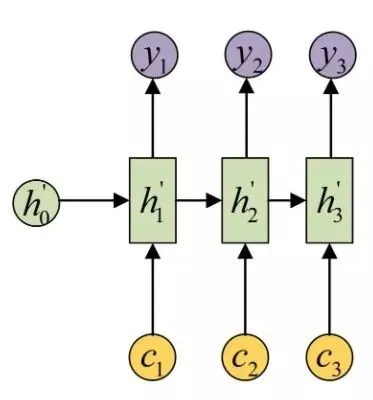 向量来解码,如图所示:
向量来解码,如图所示:
这里的每个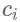 向量其实包含了当前所输出与输入序列各个部分重要性的相关的信息。不同的
向量其实包含了当前所输出与输入序列各个部分重要性的相关的信息。不同的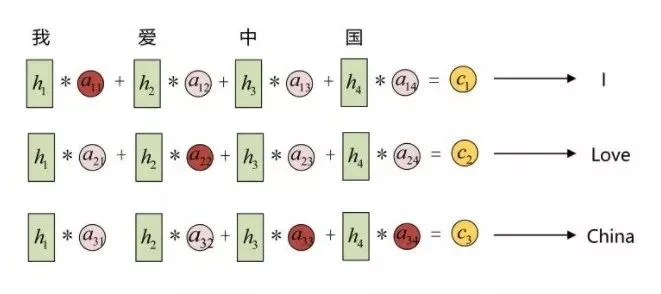 向量里面包含的输入信息各部分的权重是不同的,先放一个示意图:
向量里面包含的输入信息各部分的权重是不同的,先放一个示意图:
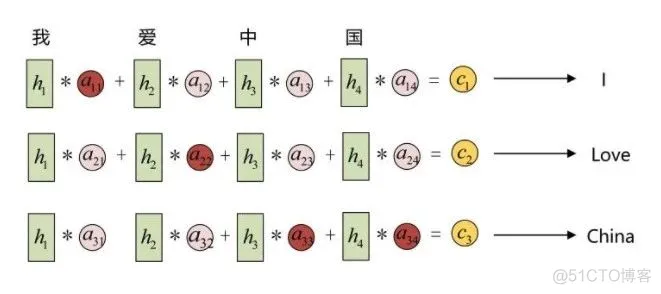
还是上面的例子,例如输入信息是“我爱中国”,输出的的理想结果应该是“I love China”,在解码的时候,应该首先需要解码出 “I” 这个字符,这时候会用到向量,而向量包含的信息中,“我”这个字的重要性更大,因此它便倾向解码输出 “I”,当解码第二个字的时候,会用到向量,而向量包含的信息中,“爱” 这个字的重要性更大,因此会解码输出 “lve”,在解码第三个字的时候,会用到向量,而向量包含的信息中,”中国” 这两个字的权重都比较大,因此会解码输出 “China”。所以其实,Attention 注意力机制中的向量记录了不同解码时刻应该更关注于哪部分输入数据,也实现了编码解码过程的对齐。经过实验发现,这种机制可以有效解决输入信息过长时导致信息解码效果不理想的问题,另外解码生成效果同时也有提升。
下面我们以 Bahdanau 提出的 Attention 为例来详细剖析一下 Attention 机制。
在没有引入 Attention 之前,Decoder 在某个时刻解码的时候实际上是依赖于三个部分的,首先我们知道 RNN 中,每次输出结果会依赖于隐层和输入,在 Seq2Seq 模型中,还需要依赖于c向量,所以这里我们设在i时刻,解码器解码的内容是,上一次解码结果是,隐层输出是,所以它们满足这样的关系: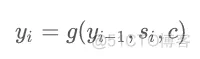
同时和还满足这样的关系: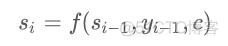
即每次的隐层输出是上一个隐层和上一个输出结果和c向量共同计算得出的。
但是刚才说了,这样会带来一些问题,c 向量不足以包含输入内容的所有信息,尤其是在输入序列特别长的情况下,所以这里我们不再使用一个c向量,而是每一个解码过程对应一个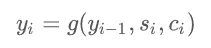 向量,所以公式改写如下:
向量,所以公式改写如下: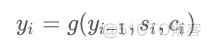
同时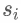 的计算方式也变为如下公式:
的计算方式也变为如下公式:
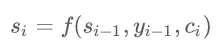
所以,这里每次解码得出时,都有与之对应的向量。那么这个向量又是怎么来的呢?实际上它是由编码器端每个时刻的隐含状态加权平均得到的,这里假设编码器端的的序列长度为,序列位次用j来表示,编码器段每个时刻的隐含状态即为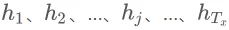 ,对于解码器的第i时刻,对应的表示如下:
,对于解码器的第i时刻,对应的表示如下:
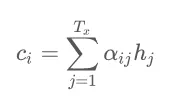
编码器输出的结果中, 中包含了输入序列中的第j个词及前面的一些信息,如果是用了双向 RNN 的话,则包含的是第j个词即前后的一些词的信息,这里代表了分配的权重,这代表在生成第i个结果的时候,对于输入信息的各个阶段的
中包含了输入序列中的第j个词及前面的一些信息,如果是用了双向 RNN 的话,则包含的是第j个词即前后的一些词的信息,这里代表了分配的权重,这代表在生成第i个结果的时候,对于输入信息的各个阶段的.png) 的注意力分配是不同的。 当的值越高,表示第i个输出在第j个输入上分配的注意力越多,这样就会导致在生成第i个输出的时候,受第j个输入的影响也就越大。
的注意力分配是不同的。 当的值越高,表示第i个输出在第j个输入上分配的注意力越多,这样就会导致在生成第i个输出的时候,受第j个输入的影响也就越大。
那么又是怎么得来的呢?其实它就又关系到第i-1个输出隐藏状态以及输入中的各个隐含状态,公式表示如下:

同时又表示为:
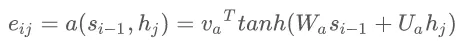
这也就是说,这个权重就是和分别计算得到一个数值,然后再过一个 softmax 函数得到的,结果就是。
因此就可以表示为:
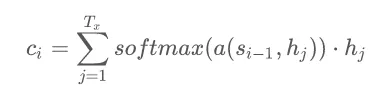
以上便是整个 Attention 机制的推导过程。
我们了解了基本原理,但真正离程序实现出来其实还是有很大差距的,接下来我们就结合 TensorFlow 框架来了解一下 Attention 的实现机制。
在 TensorFlow 中,Attention 的相关实现代码是在 tensorflow/contrib/seq2seq/python/ops/attention_wrapper.py 文件中,这里面实现了两种 Attention 机制,分别是 BahdanauAttention 和 LuongAttention,其实现论文分别如下:
整个 attention_wrapper.py 文件中主要包含几个类,我们主要关注其中几个:
下面我们以 BahdanauAttention 为例来说明 Attention 机制及 AttentionWrapper 的实现。
首先我们来介绍 BahdanauAttention 类的具体原理。
首先我们来看下它的初始化方法:
1.def __init__(self,
num_units,
memory,
memory_sequence_length=None,
normalize=False,
probability_fn=None,
score_mask_value=None,
dtype=None,
name="BahdanauAttention"):
这里一共接受八个参数,下面一一进行说明:
1.query_layer=layers_core.Dense(num_units, name="query_layer", use_bias=False, dtype=dtype)
memory_layer=layers_core.Dense(num_units, name="memory_layer", use_bias=False, dtype=dtype)
这里我们可以看到声明了一个 querylayer 和 memory_layer,分别和.png) 及
及.jpeg) 做全连接变换,统一维度。
做全连接变换,统一维度。
1.with ops.name_scope(
name, "BaseAttentionMechanismInit", nest.flatten(memory)):
self._values = _prepare_memory(
memory, memory_sequence_length,
check_inner_dims_defined=check_inner_dims_defined)
self._keys = (
self.memory_layer(self._values) if self.memory_layer
else self._values)
这里通过 _prepare_memory() 方法对 memory 进行处理,然后调用 memory_layer 对 memory 进行全连接维度变换,变换成 [batch_size, max_time, num_units]。
1.seq_len_mask = array_ops.sequence_mask(
memory_sequence_length,
maxlen=array_ops.shape(nest.flatten(memory)[0])[1],
dtype=nest.flatten(memory)[0].dtype)
seq_len_batch_size = (
memory_sequence_length.shape[0].value
or array_ops.shape(memory_sequence_length)[0])
接下来类里面定义了一个 __call__() 方法:
1.def __call__(self, query, previous_alignments):
with variable_scope.variable_scope(None, "bahdanau_attention", [query]):
processed_query = self.query_layer(query) if self.query_layer else query
score = _bahdanau_score(processed_query, self._keys, self._normalize)
alignments = self._probability_fn(score, previous_alignments)
return alignments
这里首先定义了 processedquery,这里也是通过 query_layer 过了一个全连接网络,将最后一维统一成 num_units,然后调用了 _bahdanau_score() 方法,这个方法是比较重要的,主要用来计算公式中的.png) ,传入的参数是 processedquery 以及上文中提及的 _keys 变量,二者一个代表了
,传入的参数是 processedquery 以及上文中提及的 _keys 变量,二者一个代表了.png) ,一个代表了
,一个代表了.jpeg) ,_bahdanau_score() 方法实现如下:
,_bahdanau_score() 方法实现如下:
1.def _bahdanau_score(processed_query, keys, normalize):
dtype = processed_query.dtype
# Get the number of hidden units from the trailing dimension of keys
num_units = keys.shape[2].value or array_ops.shape(keys)[2]
# Reshape from [batch_size, ...] to [batch_size, 1, ...] for broadcasting.
processed_query = array_ops.expand_dims(processed_query, 1)
v = variable_scope.get_variable(
"attention_v", [num_units], dtype=dtype)
if normalize:
# Scalar used in weight normalization
g = variable_scope.get_variable(
"attention_g", dtype=dtype,
initializer=math.sqrt((1. / num_units)))
# Bias added prior to the nonlinearity
b = variable_scope.get_variable(
"attention_b", [num_units], dtype=dtype,
initializer=init_ops.zeros_initializer())
# normed_v = g * v / ||v||
normed_v = g * v * math_ops.rsqrt(
math_ops.reduce_sum(math_ops.square(v)))
return math_ops.reduce_sum(normed_v * math_ops.tanh(keys + processed_query + b), [2])
else:
return math_ops.reduce_sum(v * math_ops.tanh(keys + processed_query), [2])
这里其实就是实现了 keys 和 processedquery 的加和,如果指定了 normalize 的话还需要进行额外的 normalize,结果就是公式中的.png) ,在 TensorFlow 中常用 score 变量表示。
,在 TensorFlow 中常用 score 变量表示。
接下来再回到 __call__() 方法中,这里得到了 score 变量,接下来可以对齐求 softmax() 操作,得到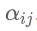 :
:
alignments = self._probability_fn(score, previous_alignments)1.这就代表了在i时刻,Decoder 的时候对 Encoder 得到的每个.jpeg) 的权重大小比例,在 TensorFlow 中常用 alignments 变量表示。
的权重大小比例,在 TensorFlow 中常用 alignments 变量表示。
所以综上所述,BahdanauAttention 就是初始化时传入 num_units 以及 Encoder Outputs,然后调时传入 query 用即可得到权重变量 alignments。
接下来我们再看下 AttentionWrapperState 这个类,这个类其实比较简单,就是定义了 Attention 过程中可能需要保存的变量,如 cell_state、attention、time、alignments 等内容,同时也便于后期的可视化呈现,代码实现如下:
1.class AttentionWrapperState(
collections.namedtuple("AttentionWrapperState",
("cell_state", "attention", "time", "alignments",
"alignment_history"))):
可见它就是继承了 namedtuple 这个数据结构,其实整个 AttentionWrapperState 就像声明了一个结构体,可以传入需要的字段生成这个对象。
了解了 Attention 机制及 BahdanauAttention 的原理之后,最后我们再来了解一下 AttentionWrapper,可能你用过很多其他的 Wrapper,如 DropoutWrapper、ResidualWrapper 等等,它们其实都是 RNNCell 的实例,其实 AttentionWrapper 也不例外,它对 RNNCell 进行了封装,封装后依然还是 RNNCell 的实例。一个普通的 RNN 模型,你要加入 Attention,只需要在 RNNCell 外面套一层 AttentionWrapper 并指定 AttentionMechanism 的实例就好了。而且如果要更换 AttentionMechanism,只需要改变 AttentionWrapper 的参数就好了,这可谓对 Attention 的实现架构完全解耦,配置非常灵活,TF 大法好!
接下来我们首先来看下它的初始化方法,其参数是这样的:
1.def __init__(self,
cell,
attention_mechanism,
attention_layer_size=None,
alignment_history=False,
cell_input_fn=None,
output_attention=True,
initial_cell_state=None,
name=None):
下面对参数进行一一说明:
1.if attention_layer_size is not None:
attention_layer_sizes = tuple(attention_layer_size if isinstance(attention_layer_size, (list, tuple)) else (attention_layer_size,))
if len(attention_layer_sizes) != len(attention_mechanisms):
raise ValueError("If provided, attention_layer_size must contain exactly one integer per attention_mechanism, saw: %d vs %d" % (len(attention_layer_sizes), len(attention_mechanisms)))
self._attention_layers = tuple(layers_core.Dense(attention_layer_size, name="attention_layer", use_bias=False, dtype=attention_mechanisms[i].dtype) for i, attention_layer_size in enumerate(attention_layer_sizes))
self._attention_layer_size = sum(attention_layer_sizes)
else:
self._attention_layers = None
self._attention_layer_size = sum(attention_mechanism.values.get_shape()[-1].value for attention_mechanism in attention_mechanisms)
for i, attention_mechanism in enumerate(self._attention_mechanisms):
attention, alignments = _compute_attention(attention_mechanism, cell_output, previous_alignments[i], self._attention_layers[i] if self._attention_layers else None)
alignment_history = previous_alignment_history[i].write(state.time, alignments) if self._alignment_history else ()
cell_inputs = self._cell_input_fn(inputs, state.attention)1.AttentionWrapper 的核心方法在它的 call() 方法,即类似于 RNNCell 的 call() 方法,AttentionWrapper 类对其进行了重载,代码实现如下:
1.def call(self, inputs, state):
# Step 1
cell_inputs = self._cell_input_fn(inputs, state.attention)
# Step 2
cell_state = state.cell_state
cell_output, next_cell_state = self._cell(cell_inputs, cell_state)
# Step 3
if self._is_multi:
previous_alignments = state.alignments
previous_alignment_history = state.alignment_history
else:
previous_alignments = [state.alignments]
previous_alignment_history = [state.alignment_history]
all_alignments = []
all_attentions = []
all_histories = []
for i, attention_mechanism in enumerate(self._attention_mechanisms):
attention, alignments = _compute_attention(attention_mechanism, cell_output, previous_alignments[i], self._attention_layers[i] if self._attention_layers else None)
alignment_history = previous_alignment_history[i].write(state.time, alignments) if self._alignment_history else ()
all_alignments.append(alignments)
all_histories.append(alignment_history)
all_attentions.append(attention)
# Step 4
attention = array_ops.concat(all_attentions, 1)
# Step 5
next_state = AttentionWrapperState(
time=state.time + 1,
cell_state=next_cell_state,
attention=attention,
alignments=self._item_or_tuple(all_alignments),
alignment_history=self._item_or_tuple(all_histories))
# Step 6
if self._output_attention:
return attention, next_state
else:
return cell_output, next_state
在这里将一些异常判断代码去除了,以便于结构看得更清晰。
首先在第一步中,调用了 _cell_input_fn() 方法,对 inputs 和 state.attention 变量进行处理,默认是使用 concat() 函数拼接,作为当前时间步的输入。因为可能前一步的 Attention 可能对当前 Attention 有帮助,以免让模型连续两次将注意力放在同一个地方。
在第二步中,其实就是调用了普通的 RNNCell 的 call() 方法,得到输出和下一步的状态。
第三步中,这时得到的输出其实并没有用上 AttentionMechanism 中的 alignments 信息,所以当前的输出信息中我们并没有跟 Encoder 的信息做 Attention,所以这里还需要调用 _compute_attention() 方法进行权重的计算,其方法实现如下:
1.def _compute_attention(attention_mechanism, cell_output, previous_alignments, attention_layer):
alignments = attention_mechanism(cell_output, previous_alignments=previous_alignments)
expanded_alignments = array_ops.expand_dims(alignments, 1)
context = math_ops.matmul(expanded_alignments, attention_mechanism.values)
context = array_ops.squeeze(context, [1])
if attention_layer is not None:
attention = attention_layer(array_ops.concat([cell_output, context], 1))
else:
attention = context
return attention, alignments
这个方法接收四个参数,其中 attentionmechanism 就是 AttentionMechanism 的实例,cell_output 就是当前 Output,previous_alignments 是上步的 alignments 信息,调用 attention_mechanism 计算之后就会得到当前步的 alignments 信息了,即 .png) 。接下来再利用 alignments 信息进行加权运算,得到 attention 信息,即
。接下来再利用 alignments 信息进行加权运算,得到 attention 信息,即.jpeg) ,最后将二者返回。
,最后将二者返回。
在第四步中,就是将 attention 结果每个时间步进行 concat,得到 attention vector。
第五步中,声明 AttentionWrapperState 作为下一步的状态。
第六步,判断是否要输出 Attention,如果是,输出 Attention 及下一步状态,否则输出 Outputs 及下一步状态。
好,以上便是整个 AttentionWrapper 源码解析过程,了解了源码之后,再做模型优化的话就非常得心应手了。
免责声明:本文系网络转载或改编,未找到原创作者,版权归原作者所有。如涉及版权,请联系删
武汉格发信息技术有限公司,格发许可优化管理系统可以帮你评估贵公司软件许可的真实需求,再低成本合规性管理软件许可,帮助贵司提高软件投资回报率,为软件采购、使用提供科学决策依据。支持的软件有: CAD,CAE,PDM,PLM,Catia,Ugnx, AutoCAD, Pro/E, Solidworks 等。
 技术文档
技术文档
 推荐好文
推荐好文






 155-2731-8020
155-2731-8020




















